
YOLOv5 is one of the most popular object detection networks in the world, and now object detection isn't the only trick up its sleeve!
As of August 2022, YOLOv5 also supports classification tasks.
This blog will walk through how to train YOLOv5 for classification on a custom dataset. (If you're interested object detection, we have a YOLOv5 for object detection guide as well.)
Follow along with the How To Train YOLOv5 Classification Colab Notebook.
This post will walk through:
- Setting up the environment
- Prepare a custom dataset for classification
- Training YOLOv5 for classification
- Testing and validating the custom model
Video tutorial for training YOLOv5 Classification
Setting Up The Environment
First, we need to clone the Ultralytics YOLOv5 repo and install all its dependancies.
!git clone https://github.com/ultralytics/yolov5 # clone
%cd yolov5
%pip install -qr requirements.txt # install
import torch
import utils
display = utils.notebook_init() # checksPrepare a Custom Dataset for Classification
In order to train YOLOv5 with a custom dataset, you'll need to gather a dataset, label the data, and export the data in the proper format for YOLOv5 to understand your annotated data. Roboflow Annotate makes each of these steps easy and is the tool we will use in this tutorial.
To get started, create a free Roboflow account. We will be using this Tomato classification dataset from Roboflow Universe as our example dataset. A tomato classification model could be used in precision agriculture to pick tomatoes with the correct ripeness, pick certain types of tomatoes, sort tomatoes once they have been picked, serve as input of overall crop growth or crop health, and more.
You can use classification to understand health scans, categorize art, or filter large databases of content. Multi-label classification is another option if your classes have multiple tags you'd like to assign to a single image.
Feel free to follow along with the same dataset or find another dataset in Universe (a community of 66M+ open source images) to use if you don't already have your own data.
If you have your own images ready to go from another source, here's what we'll do.
Create a new Project in Roboflow and select Single-Label Classification.
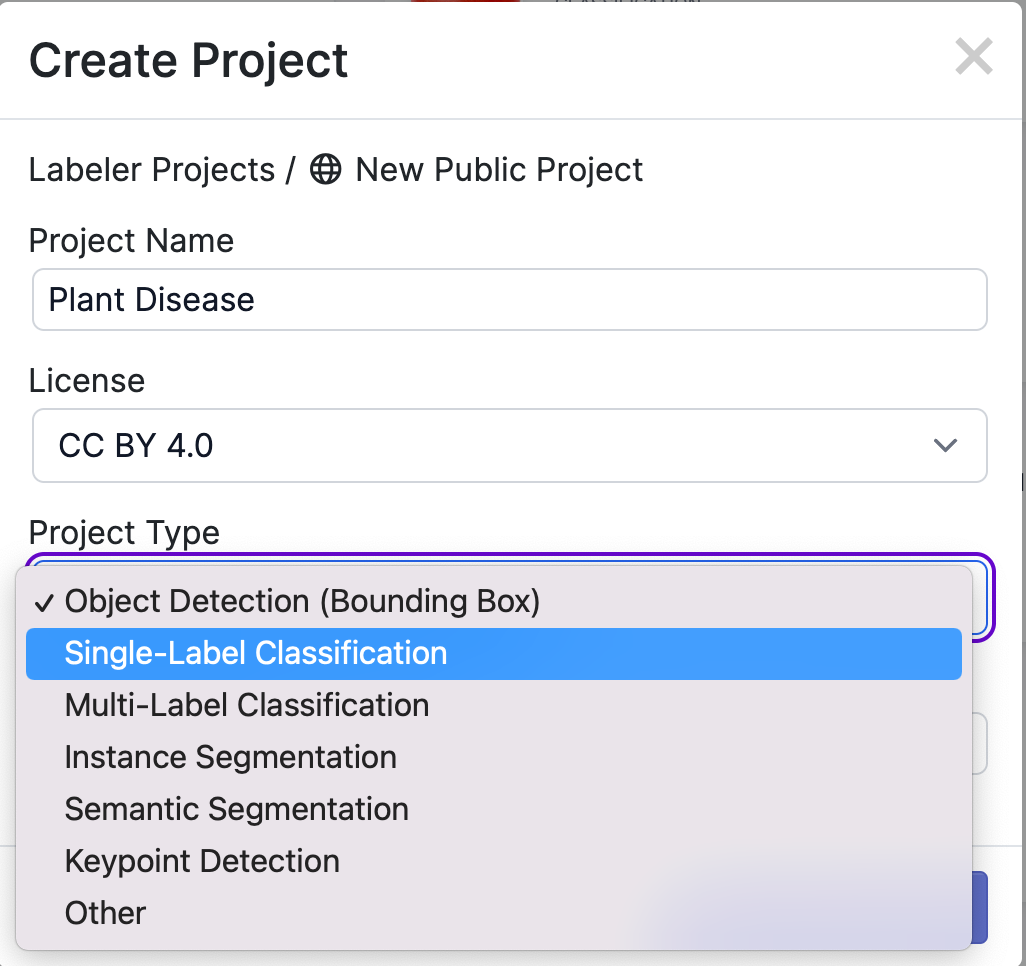
Next, add the data to your Project via API or through our web interface. If you're using a dataset from Roboflow Universe, you can download the data with the annotations already done for you which means you do not need to manually label your images.
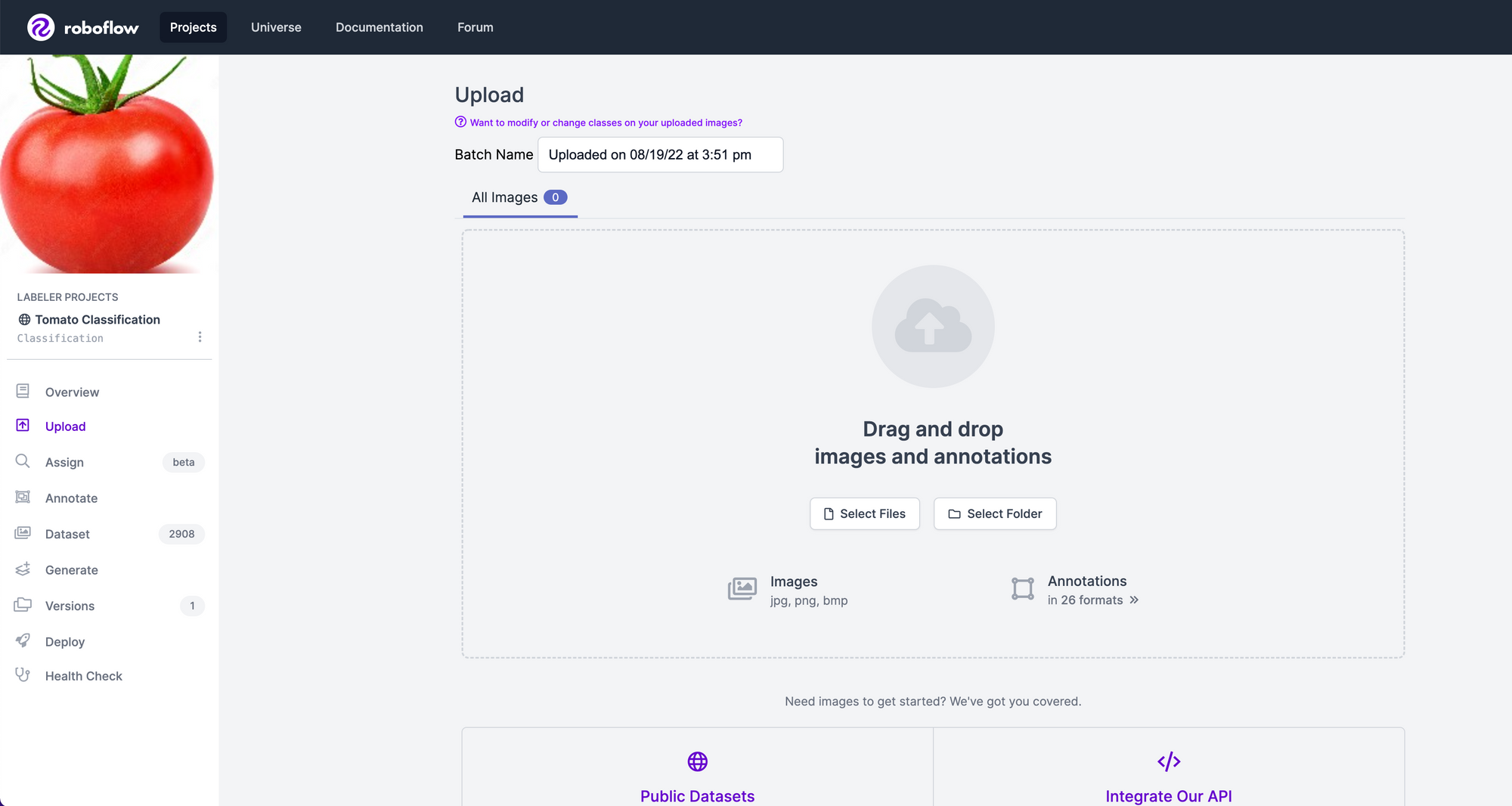
If your images are already separated such that each class is its own file directory (for example, all red tomatoes in a red-tomato folder and all yellow tomatoes in a yellow-tomato directory), Roboflow will automatically consider these images to be labeled based on the folder you drag-and-drop into the interface.
If your images are not with one folder in each class, we can label them in Roboflow. Add your images, and assign a user in your account to label them (even if this is assigning to yourself).
Labeling single-label classification data can be a quick if you only have a few classes of data. If you have a large dataset, consider labeling 50 to 100 images, then using Roboflow Train to enable model assisted labeling. Model assisted labeling can help speed up labeling time by automatically applying best estimate labels to your images.
After labeling the data, we can apply preprocessing and augmentation to increase the size of our dataset and account for cases that may give our model difficulty predicting the classification.
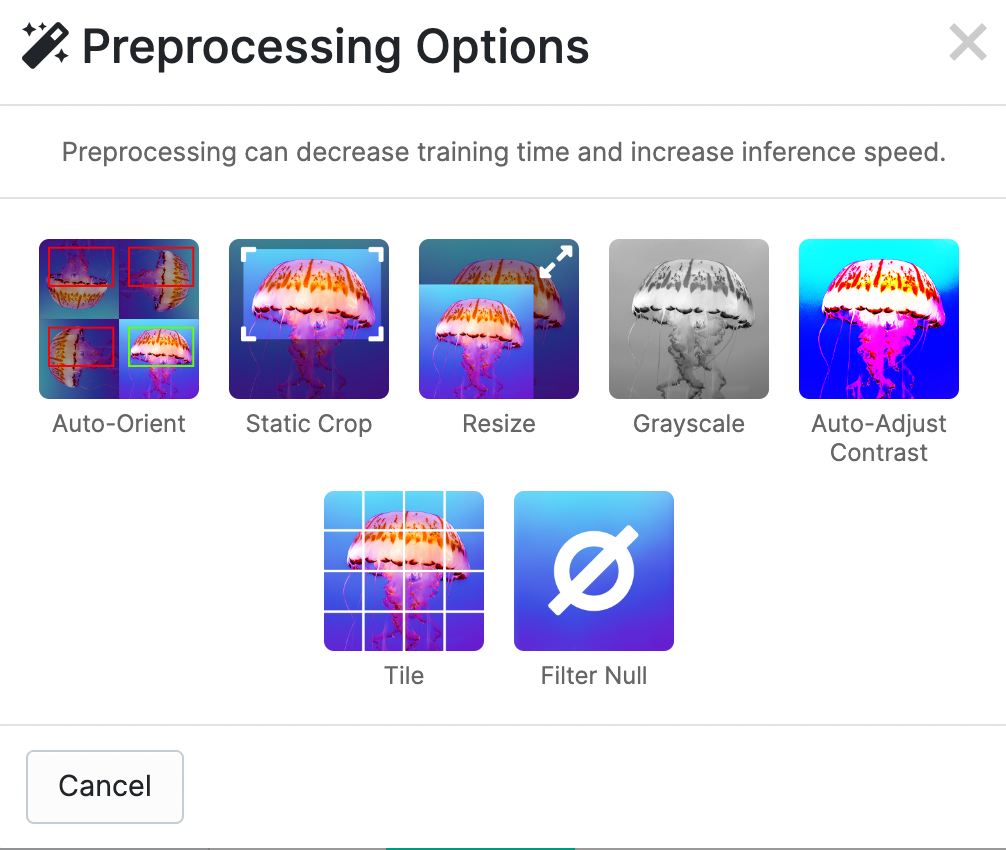
For this tutorial, let's use Auto-Orient and Resize because tomatoes can be in any position and we have different image sizes in our dataset.
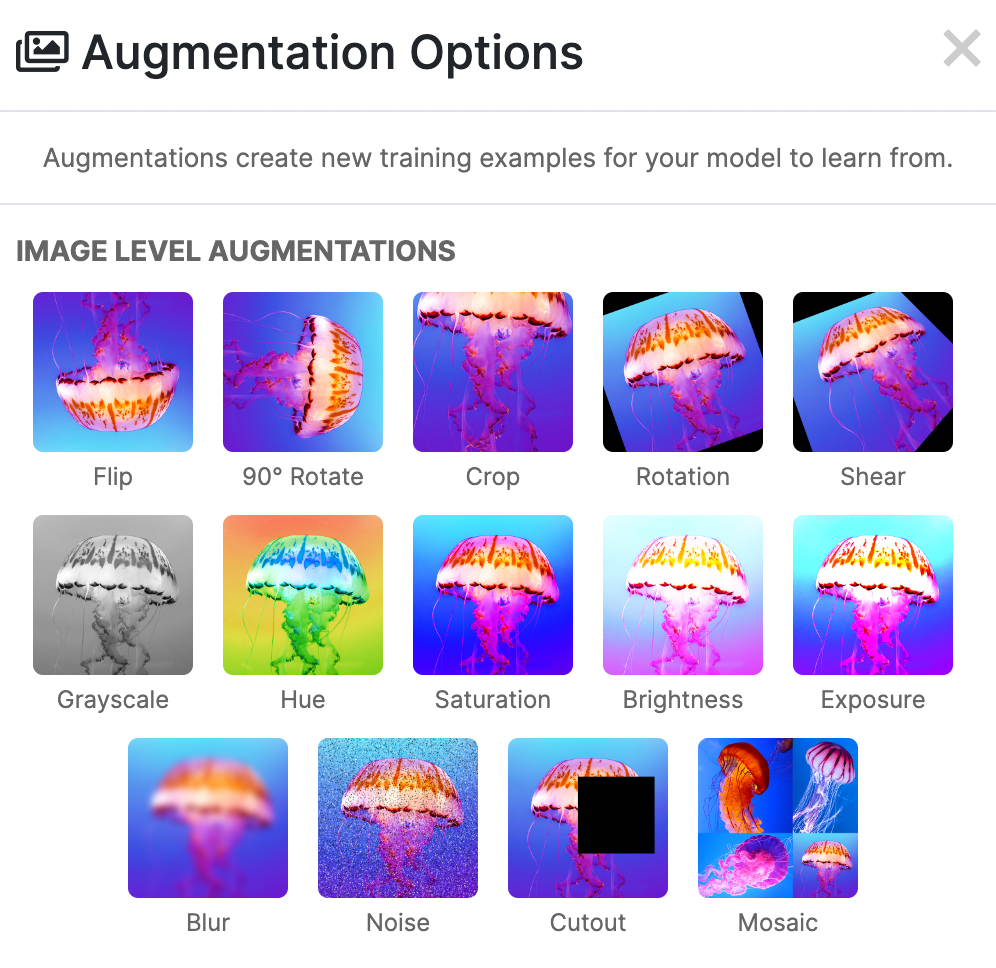
We can apply augmentations that could be possible in real world scenarios. Flipping, rotating, and shear will help when our objects can be in multiple orientations so we will apply those. Blur, noise, and cutout can help when anything is blocking the full view of our object or if other objects might enter our images.
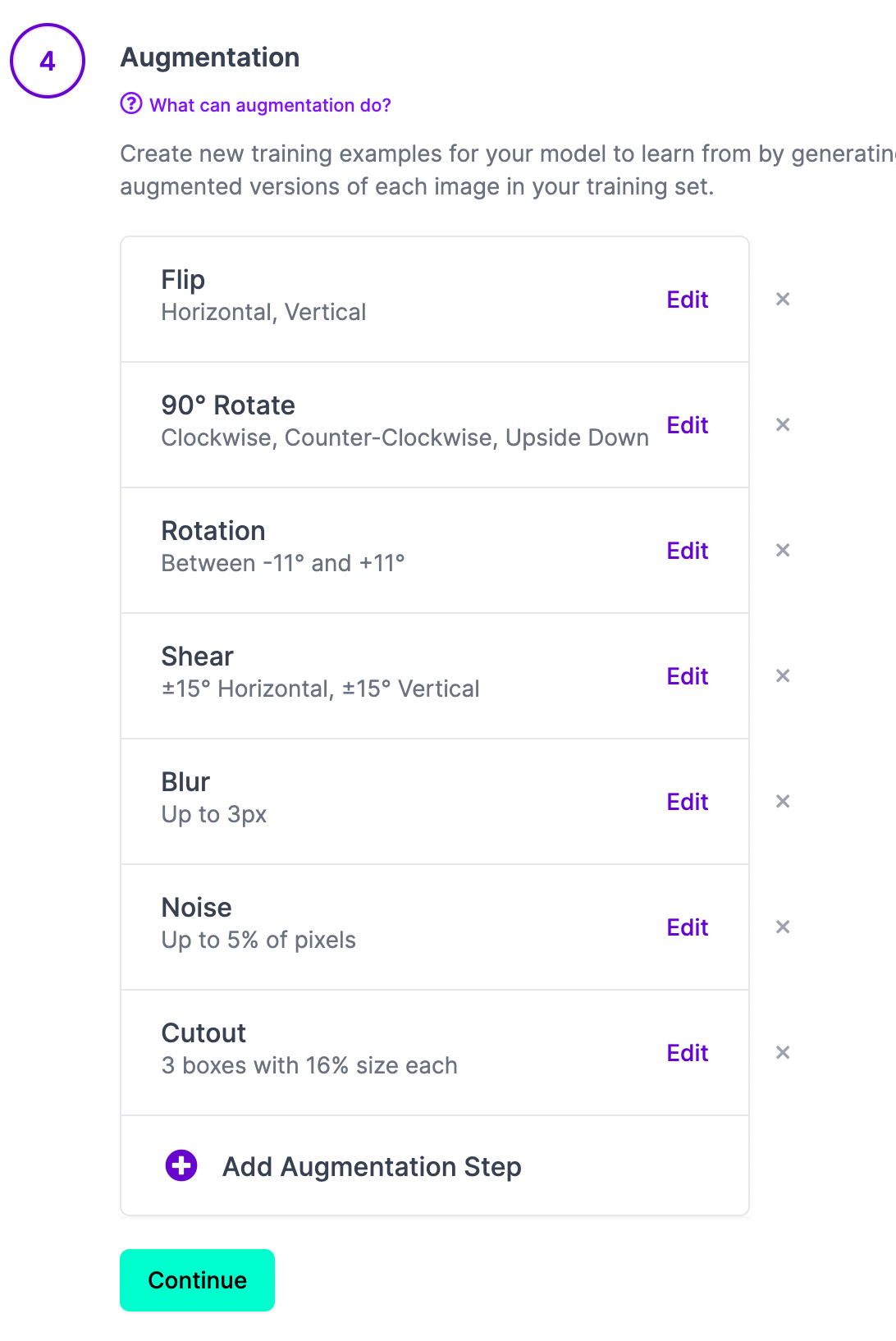
Once we've applied our preprocessing and augmentations, we can generate our dataset which is the final step in creating a dataset to train the model.
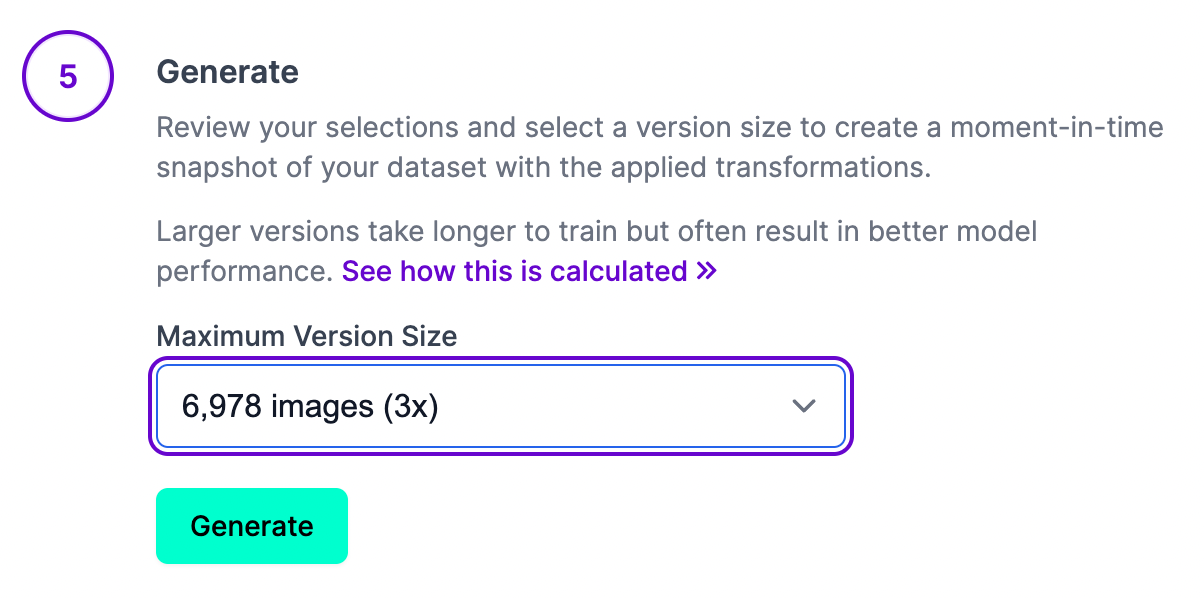
After clicking generate, our dataset will be prepared and can then be exported for training in our custom YOLOv5 classification notebook pipeline.
You have multiple options for exporting the dataset and for this tutorial you'll select 'show download code' which you'll use to then access this dataset in the Colab notebook.
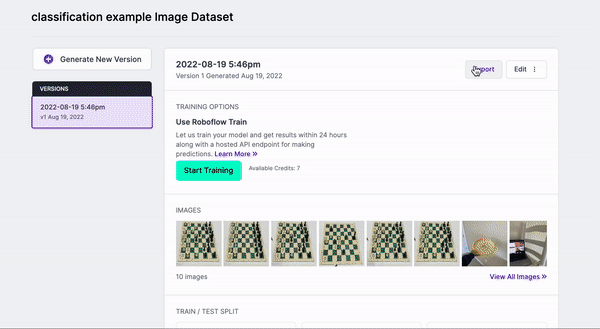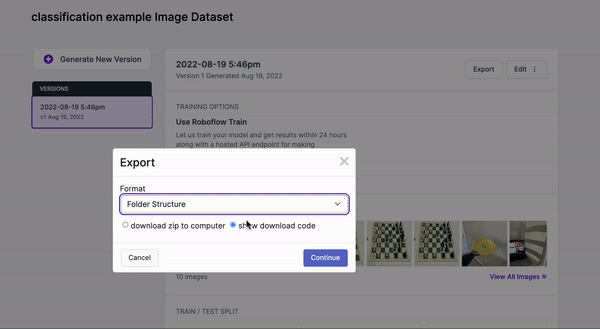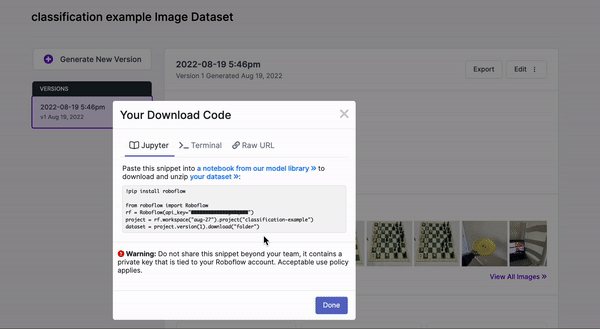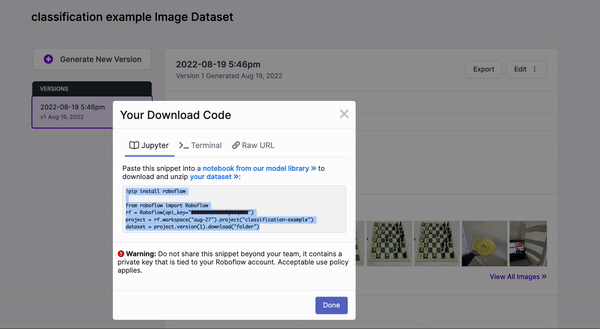
Be sure to copy this code snippet that Roboflow generates for us.
Return to the YOLOv5 Classification Colab Notebook and paste this generated code snippet. Be sure to paste the code snippet (which includes our Workspace, Project name, and private API key) to below %cd ../datasets/ so that the data downloads to the right place.
!pip install roboflow
%cd ../datasets/
from roboflow import Roboflow
rf = Roboflow(api_key="YOUR API KEY")
project = rf.workspace("workspace-name").project("project-name")
dataset = project.version(1).download("folder")In the notebook, we'll also set an environment variable equal to our dataset_name so we can reference this dataset when we call the custom training script below.
Train YOLOv5 For Classification on a Custom Dataset
Before training on our own custom dataset, we'll need do download some pre-trained weights so we aren't starting from scratch. This will accelerate the training process and improve the quality of our results.
%cd ../yolov5
from utils.downloads import attempt_download
p5 = ['n', 's', 'm', 'l', 'x'] # P5 models
cls = [f'{x}-cls' for x in p5] # classification models
for x in cls:
attempt_download(f'weights/yolov5{x}.pt')Then, we are ready to train! We can follow the same steps as above with some minor modifications to the input parameters.
!python classify/train.py --model yolov5s-cls.pt --data $DATASET_NAME --epochs 5 --img 128 --pretrained weights/yolov5s-cls.ptHere's the (truncated) output to expect:
Starting yolov5s-cls.pt training on Breeds-1 dataset with 2 classes for 5 epochs...
Epoch GPU_mem train_loss test_loss top1_acc top5_acc
1/5 0.396G 0.941 0.691 0.545 1: 100% 4/4 [00:00<00:00, 5.74it/s]
2/5 0.396G 0.69 0.69 0.545 1: 100% 4/4 [00:00<00:00, 5.03it/s]
3/5 0.396G 0.69 0.69 0.545 1: 100% 4/4 [00:00<00:00, 5.38it/s]
4/5 0.396G 0.687 0.69 0.545 1: 100% 4/4 [00:00<00:00, 4.66it/s]
5/5 0.396G 0.63 0.69 0.545 1: 100% 4/4 [00:00<00:00, 4.88it/s]
Training complete (0.001 hours)
Results saved to runs/train-cls/exp2
Predict: python classify/predict.py --weights runs/train-cls/exp2/weights/best.pt --source im.jpg
Validate: python classify/val.py --weights runs/train-cls/exp2/weights/best.pt --data /content/datasets/Breeds-1Test and Validate the Custom Model
We can test and validate with our newly trained custom model. This script reports the results of the classification training results for each class.
!python classify/val.py --weights runs/train-cls/exp/weights/best.pt --data ../datasets/$DATASET_NAMEThis shows us metrics over our entire validation set:
Class Images top1_acc top5_acc
all 33 0.545 1
red-tomato 15 0 1
yellow-tomato 18 1 1Next, we can try out inferring with our custom model! We'll pass an example image. In the notebook, note that we set a TEST_IMAGE_PATH to be one of the images that comes in the test set folder that comes from the Roboflow data loader. This ensures that we're truly testing on an image our model did not see in training.
!python classify/predict.py --weights runs/train-cls/exp/weights/best.pt --source $TEST_IMAGE_PATHWe'll see output scores like red-tomato 0.54, yellow-tomato 0.46 , so it looks like our model is beginning to learn, though it can likely benefit from more data and active learning.
Improving the Model with Active Learning
Once you have trained the model, you may want to improve the results by adding additional data going through your computer vision pipeline. Use the Roboflow pip package to make the most of your trained model.
Using the pip package you can download or export images from your dataset, upload images and annotations, run inference on a trained version of your dataset, and improve your model's performance by adding more data to train the model again.
from roboflow import Roboflow
import json
# private api key found in Roboflow > YOURWORKSPACE > Roboflow API
# NOTE: this is your private key, not publishable key!
# https://docs.roboflow.com/rest-api#obtaining-your-api-key
private_api_key = "INSERT API KEY HERE"
# gain access to your workspace
rf = Roboflow(api_key=private_api_key)
workspace = rf.workspace()
# you can obtain your model path from your project URL, it is located
# after the name of the workspace within the URL - you can also find your
# model path on the Example Web App for any dataset version trained
# with Roboflow Train
# https://docs.roboflow.com/inference/hosted-api#obtaining-your-model-endpoint
model_path = "INSERT MODEL PATH HERE"
project = workspace.project(f"{model_path}")
# be sure to replace with a path to your file
# if you run this in Colab, be sure to upload the file to colab, hover over
# the file name, and select the 3 dots on the right of the file name to copy
# the file path, and paste it as the value for "imgpath"
img_path = "INSERT IMAGE PATH HERE"
# establish number of retries to use in case of upload failure
project.upload(f"{img_path}", num_retry_uploads=3)Below you'll see ways to upload images that can help select the right data to then improve the performance of your model. By growing the available data to train with and focusing on images your model is not handling well, you can ensure your model quickly improves performance while in production.
from roboflow import Roboflow
# obtaining your API key: https://docs.roboflow.com/rest-api#obtaining-your-api-key
rf = Roboflow(api_key="INSERT_PRIVATE_API_KEY")
workspace = rf.workspace()
raw_data_location = "INSERT_PATH_TO_IMAGES"
raw_data_extension = ".jpg" # or ".png", ".jpeg" depending on file type
# replace * with your model version number for inference
inference_endpoint = ["INSERT_MODEL_ID", *]
upload_destination = "INSERT_MODEL_ID"
# set the conditionals values as necessary for your active learning needs
conditionals = {
"required_objects_count" : 1,
"required_class_count": 1,
"target_classes": [],
"minimum_size_requirement" : float('-inf'),
"maximum_size_requirement" : float('inf'),
"confidence_interval" : [10,90],
}
# filtering out images for upload by similarity is available for paid plans
# contact the Roboflow team for access: https://roboflow.com/sales
# conditionals = {
# "required_objects_count" : 1,
# "required_class_count": 1,
# "target_classes": [],
# "minimum_size_requirement" : float('-inf'),
# "maximum_size_requirement" : float('inf'),
# "confidence_interval" : [10,90],
# "similarity_confidence_threshold": .3,
# "similarity_timeout_limit": 3
# }
workspace.active_learning(raw_data_location=raw_data_location,
raw_data_extension=raw_data_extension,
inference_endpoint=inference_endpoint,
upload_destination=upload_destination,
conditionals=conditionals)
Summary
And there you have it! YOLOv5 trained for classification on a custom dataset.
Don't forget to checkout the How To Train YOLOv5 Classification Colab.
Happy classifying!
Cite this Post
Use the following entry to cite this post in your research:
Paul Guerrie, Trevor Lynn. (Aug 19, 2022). How to Train YOLOv5-Classification on a Custom Dataset. Roboflow Blog: https://blog.roboflow.com/train-yolov5-classification-custom-data/