
This is a guest post written by Frederik Brammer, a student in Germany.
Due to the Coronavirus pandemic, working from home has become more important than ever. Because of homeschooling, school servers have crashed due to the enormous amount of traffic – in some cases, multiple days go by without contact between students and teachers. The biggest issues for those servers are likely to be videos and images. While single images are not a big problem, a large number of them quickly consumes a lot of bandwidth.
A solution to this problem would be to extract text from the documents so that instead of sending large images back and forth electronically, just the text is sent, consuming less bandwidth. While there are many services out there that offer automated document analysis, I wanted to take it a step further and see whether it is possible to have a custom machine learning model detect tasks from school books. The goal is to keep the task structure from the document while drastically reducing the size of what needs to be sent.
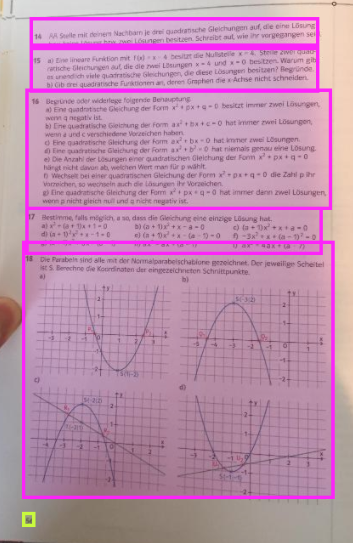
The first challenge is to identify individual tasks on a page. My dataset includes about 1,000 scans of pages from school books. I took the images from my cell phone and uploaded them to Roboflow.
I really like Roboflow’s end-to-end machine learning pipeline, which includes annotation, preprocessing, augmentation, and training. It helped me avoid unnecessary exports or conversions. Before using Roboflow, I previously had issues with weirdly rotated images due to wrong EXIF data destroying my dataset. By default, Roboflow removes the EXIF data and therefore eliminates the issue.
I used Roboflow Annotate to label my images. I labeled tasks (in pink bounding boxes) and page numbers (in yellow bounding boxes). After annotating, I resized my images.
In order to build a model that could generalize better to different textbook layouts, I applied many image augmentation techniques: random flipping, hue, saturation, exposure, and brightness. Initially, I tried writing custom Python programs for this, but between the number of bugs in the code and the amount of time it took to write the code, Roboflow sped up this process by a lot.
As I wanted to be able to scale the infrastructure hosting the model, I explored a few options.
- I first took a look at AWS Rekognition where payment is done per inference hour. I couldn't predict the traffic coming in, so this was not an ideal option.
- Microsoft Azure, on the other hand, has a pay-per-image service called Custom Vision. Custom Vision automatically selects the right model, so I don't have much control over it.
- I used the Scaled-YOLOv4 Colab notebook from Roboflow – I just had to export my dataset and train the model, with no additional coding required.
- I also tried Apple’s Create ML app, though found the Scaled-YOLOv4 model was performing significantly better.
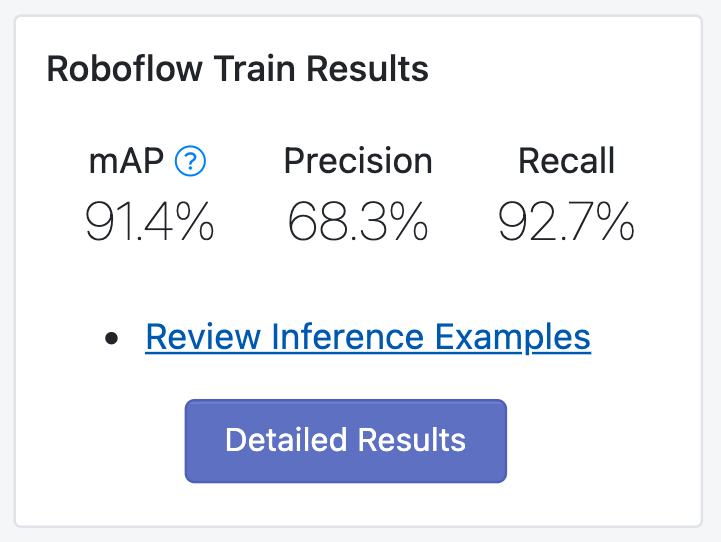
I am really excited to see how the model performs in production!
Using Roboflow, I’ve been able to quickly create, test, and deploy my machine learning ideas without needing much data science expertise or great coding skills.
Cite this Post
Use the following entry to cite this post in your research:
Matt Brems. (Apr 6, 2021). Using Computer Vision to Extract Document Structure. Roboflow Blog: https://blog.roboflow.com/using-computer-vision-extract-document-structure/