
Google DeepMind's Vision Banana applies lightweight instruction-tuning to the Nano Banana Pro image generation model to produce a generalist computer vision model that handles semantic segmentation, instance segmentation, monocular metric depth estimation, and surface normal estimation in a single architecture. It outperforms specialist models including SAM 3 and Depth Anything 3 on their own benchmarks, suggesting that generative pretraining can serve as a foundation for unified vision models. The model is currently a research release and not yet available as a public API.
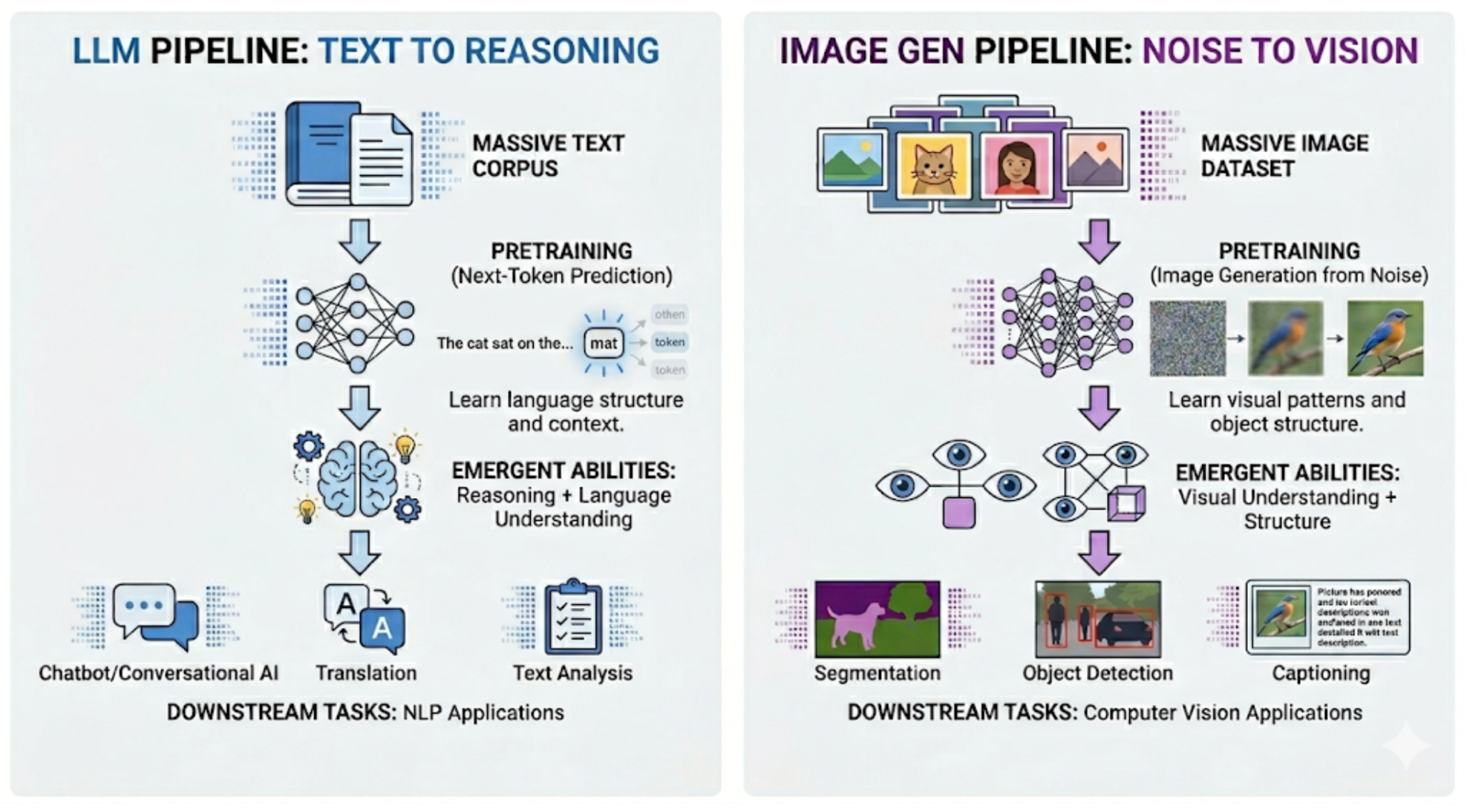
Building a computer vision pipeline often means managing chaining specialized models together. You deploy one architecture to segment scenes, and another to estimate depth.
Google DeepMind's Vision Banana might change that.
In their recent paper, Image Generators are Generalist Vision Learners, DeepMind shows that generative models can do much more than just create pixels: they can actually understand them. By applying lightweight instruction-tuning to an image generator (Nano Banana Pro), they transformed it into a multi-task generalist without sacrificing its core generative capabilities.
Vision Banana handles complex 2D and 3D visual understanding out of the box, including semantic and instance segmentation, metric depth estimation, and surface normal estimation – with better performance then SAM 3 and Depth Anything 3.
This release suggests that image generation pretraining could be the computer vision equivalent to LLM pretraining. By using image generation as a unified interface, developers can unlock emergent visual reasoning capabilities, potentially replacing complex, multi-model architectures with a single, highly capable foundation model.
What Is Vision Banana?
Vision Banana is a unified image generation model built via instruction-tuning of Nano Banana Pro, achieving state-of-the-art results across a variety of computer vision tasks, including image segmentation, monocular metric depth estimation, and surface normal estimation.
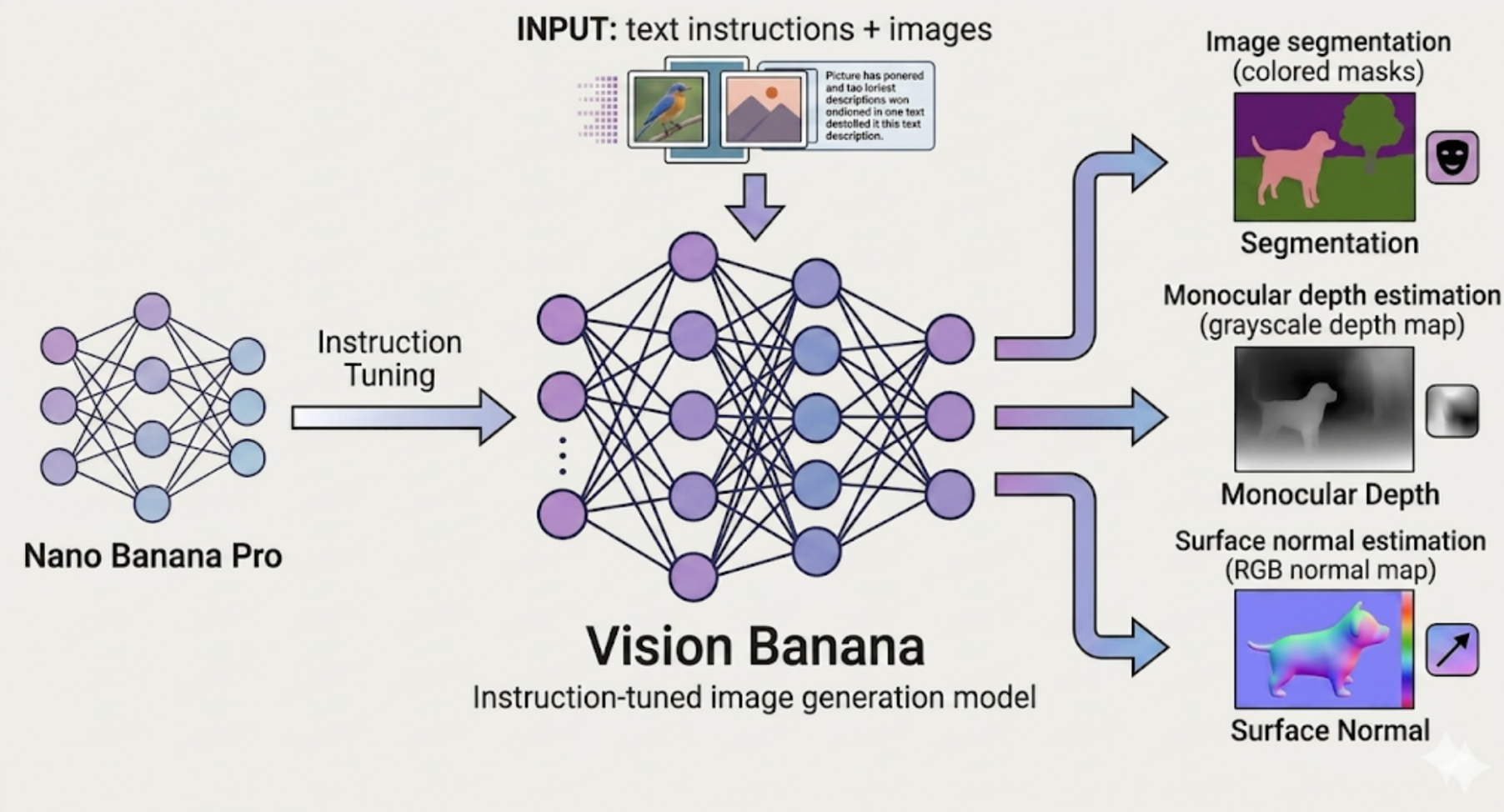
Nano Banana Pro is Google DeepMind’s latest and most powerful image generation model, part of the Gemini 3 series.
Instruction-tuning is a lightweight fine-tuning process that teaches a pretrained model to follow specific instructions without retraining it from scratch. In Vision Banana, the base model, Nano Banana Pro, is taught to format its outputs as RGB images that correspond to different computer vision tasks, guided by text prompts. Only a small amount of task-specific data is needed, since the core visual understanding was already established during generation pretraining.
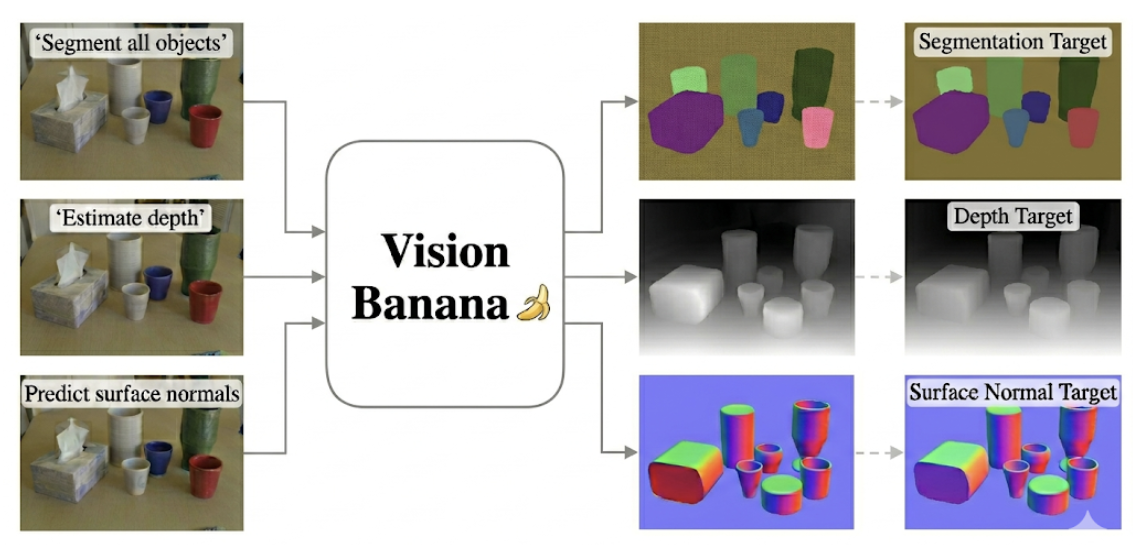
Vision Banana develops remarkable 2D and 3D understanding capabilities. It outperforms several strong models, including Segment Anything Model 3 (SAM 3) on segmentation tasks, and the Depth Anything series on metric depth estimation, all within a single unified model.
Ditching Task-Specific Heads: RGB as a Universal API
Traditional computer vision models typically rely on task-specific outputs for different computer vision tasks. Even vision foundation models, such as DINO, which utilize a powerful, general-purpose backbone, still depend on task-specific heads that can be fine-tuned with a small amount of labeled data. Vision banana, instead of relying on task-specific outputs, parametrizes the output space as RGB images. The generated structure of the output is then controlled via text prompts. No specialized architectural components required for different tasks.
One Prompt, Multiple Modalities: 2D and 3D Tasks
Vision Banana inherits the image generation (text-to-image) capabilities of Nano Banana Pro, and performs on par with it in image editing.
Additionally, it covers two categories of visual understanding tasks. For 2D understanding: semantic segmentation, instance segmentation and referring expression segmentation. For 3D understanding: monocular metric depth estimation and surface normal estimation. It is trained on annotated web data for 2D visual understanding tasks, and synthetic data generated from simulation engines for 3D tasks.
Let's break down exactly how Vision Banana tackles these five core vision tasks:
- Semantic Segmentation: This task assigns a class label to every pixel in an image. The Vision Banana model is prompted to generate an image where each pixel is colored according to its class. The classes can be arbitrary text strings, not limited to a fixed set of predefined categories and the color of each class is specified in the prompt.
- Instance Segmentation: Unlike semantic segmentation, instance segmentation requires the model to distinguish between individual objects belonging to the same class. Since the number of instances is unknown in advance, colors cannot be specified in the prompt. Vision Banana is instead instructed once per class to produce segmentation masks, allowing the model to dynamically assign colors to different instances.
- Referring Expression Segmentation: This task requires the model to segment objects identified by free-form text queries, rather than fixed category labels. This demands understanding of natural language and complex relationships among objects.
- Monocular Metric Depth Estimation: Depth estimation aims to produce a depth map from a monocular image, where each pixel represents the physical distance from the camera to the observed surface. The Vision Banana model is instructed to render depth as an image where color encodes distance. This color-to-distance mapping is invertible, allowing the generated color image to be decoded back into a metric depth map. A metric depth map assigns to each pixel an absolute distance value from the camera in real-world units. Note that camera intrinsics are not needed. The term monocular means estimating depth from a single image.
- Surface Normal Estimation: Surface normal estimation predicts, for each pixel, a unit vector describing the orientation of the surface at that point. Since surface normals have three components (x, y, z) each ranging from −1 to 1, they map naturally to RGB color channels, making visualization straightforward without requiring any additional color encoding.
1. Semantic Segmentation
Vision Banana can generate segmentation masks for images based on text prompts, supporting input from single words to full phrases. Notice below how the model maps specific text instructions directly to pixel-level color masks without needing a predefined class list. Users can specify which categories to segment as well as the colors used for visualization. Colors can be defined in various formats.

2. Instance Segmentation
Vision Banana performs instance segmentation by identifying and separating individual objects. Each detected object can be highlighted in a unique color according to the user prompt. Vision Banana can also understand complex natural language phrases, enabling fine-grained segmentation beyond simple category labels.

3. Referring Expression Segmentation
Vision Banana can understand and reason about natural language prompts, including but not limited to descriptions of object appearances, descriptions of actions, objects that have uncommon usage, and multilingual text content. These capabilities require robust and comprehensive visual understanding. You can see this complex reasoning in action below, where the model successfully isolates objects based on highly specific, free-form descriptions.

4. Monocular Metric Depth Estimation
The model's zero-shot capabilities also extend into 3D space, translating single, flat images into highly accurate depth maps.
In the following image, the two columns on the left are the input images and the depth visualization images generated by Vision Banana. The depth images are decoded back to metric depth values. Combining them with the camera intrinsics enables accurate reconstruction of the 3D scene. The two columns on the right are random views of the reconstructed scene. Note that camera intrinsics are not needed in predicting the depth itself.

The following image from Vision Banana paper shows an example in which an image is captured using a consumer cellphone. Vision Banana generates a depth estimation image, where the depth value at the position marked by the green star is decoded as 13.71 meters. The author subsequently measures the actual distance using Google Maps and finds it to be 12.87 meters. This example demonstrates the remarkable accuracy of Vision Banana depth estimation.

5. Surface Normal Estimation
When benchmarking surface normal estimation against state-of-the-art models like Lotus-2, Vision Banana captures significantly finer-grained details.

The Evaluation: Beating Specialists at Their Own Game
The zero-shot benchmark data speaks for itself. Vision Banana either rivals or directly beats state-of-the-art specialists across the board. For 2D visual understanding, it surpasses Segment Anything Model 3 on semantic and referring segmentation and achieves performance comparable to DINO-X on instance segmentation.
For 3D visual understanding, it outperforms Depth Anything 3 on metric depth estimation, as well as the leading surface normal estimation model, Lotus-2. In visual generation, Vision Banana inherits the capabilities of Nano Banana Pro and achieves comparable performance on both text-to-image generation and image editing tasks.
Notably, all results are achieved under a zero-shot transfer setting, no benchmark data is used during pretraining or fine-tuning, making the performance even more remarkable.
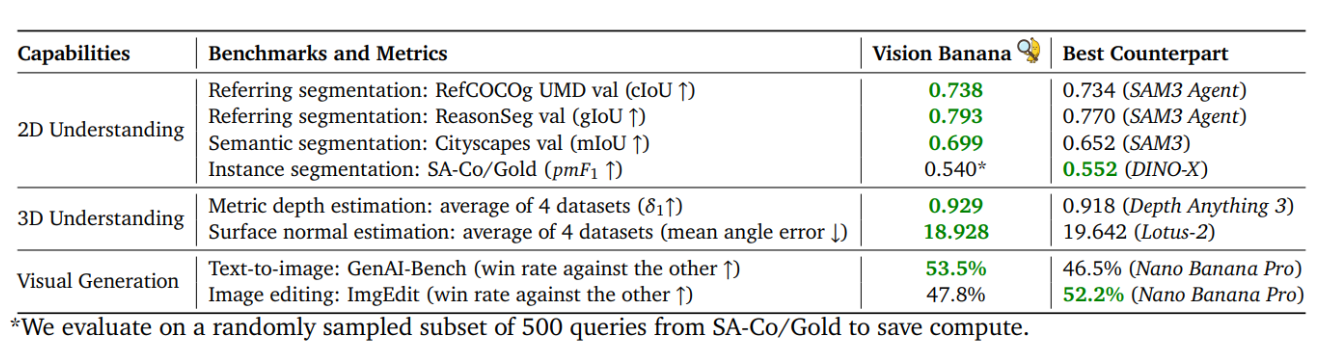
The results discussed above are also illustrated in the following plots.
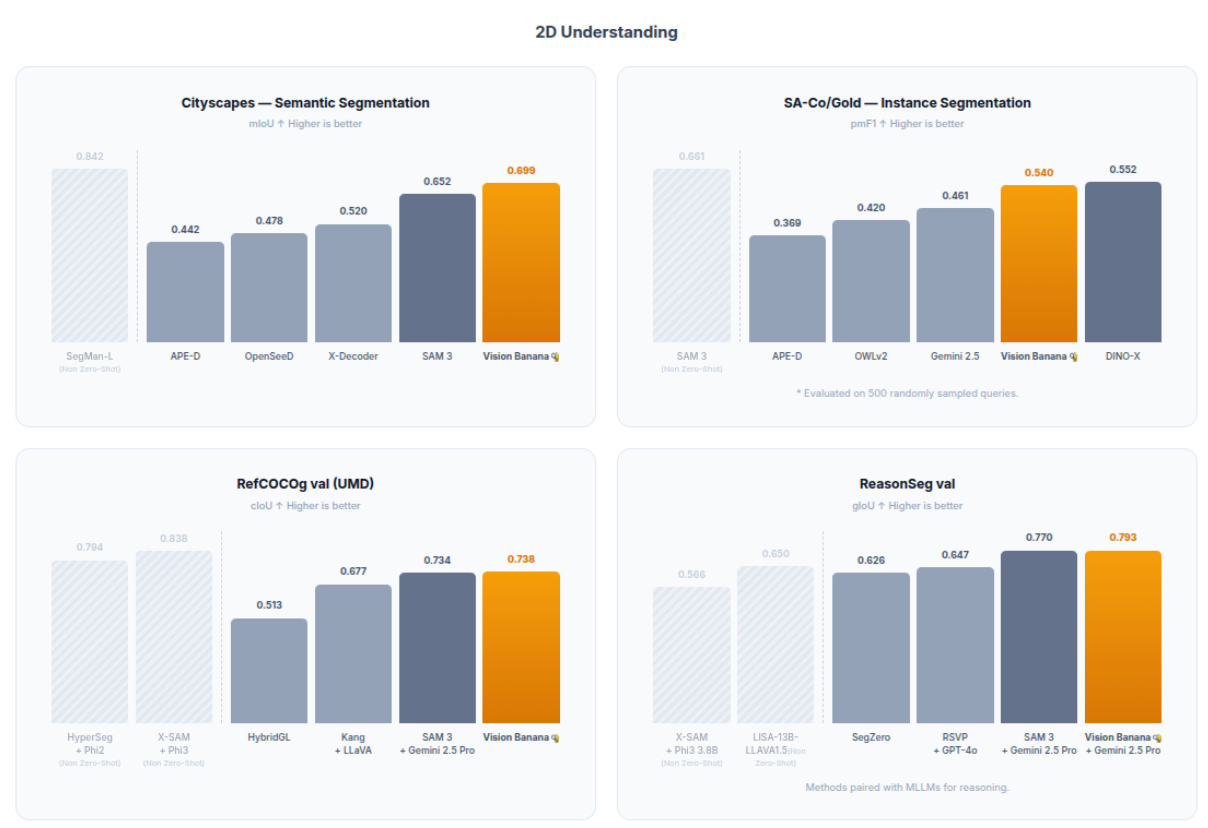
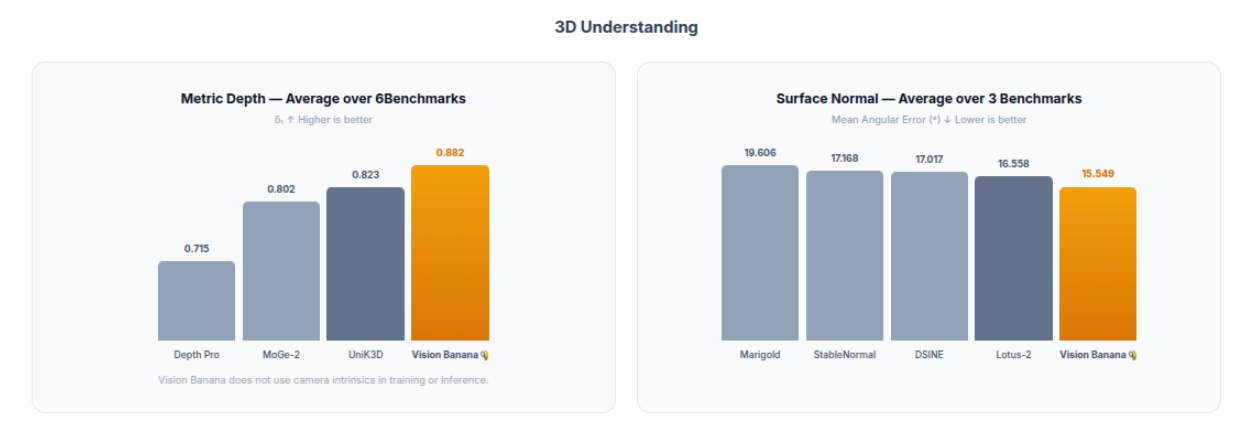
Why This Changes Pipeline Design
What makes this architecture so effective for production pipelines?
- Unified Model for Image Generation and Visual Understanding: A single model can perform segmentation, monocular metric depth estimation, and surface normal estimation, while remaining fully capable of generating high-quality, realistic images.
- Minimal Fine-tuning Required to Unlock Specialized Vision Capabilities: After generation pretraining, Vision Banana is adapted with only a small amount of image-prompt pairs via instruction-tuning.
- Outperforming Specialized Models: Remarkably, a generalist model outperforms specialists at their own tasks. Vision Banana surpasses SAM 3, the current gold standard for segmentation, and Depth Anything 3, the leading dedicated depth estimation model, outperforming both within a single generalist architecture.
- RGB Image Parametrization: Vision Banana parametrizes all vision task outputs as RGB images, allowing a single image generator to solve several vision tasks. No task-specific heads, no separate models, only the prompt changes.
- No Camera Parameters Required for Metric Depth Estimation: Vision Banana estimates metric depth with high accuracy from a single image, requiring no camera parameters, making it practical for real-world use on any camera.
Why Vision Banana Is Novel
Vision Banana paves the way for a new generation of general-purpose computer vision models.
In production computer vision pipelines for robotics, autonomous driving, and industrial inspection, it is common to chain multiple specialized models together: one for segmentation, one for depth, one for surface normals, each with its own weights and maintenance overhead.
Vision Banana points toward a different direction: a unified model, queried with different prompts, handling all of these tasks within a single architecture. This reduces system complexity, eliminates the overhead of maintaining separate models, and makes training more efficient.
Key Insights:
- Image Generation Pretraining Plays a Similar Role to LLM Pretraining: Both produce a strong generalist foundation model that can be adapted to a wide range of specialized downstream tasks with minimal additional fine-tuning.
- Image Generation Can Serve as a Universal Interface: Generative vision pretraining may be the missing piece for true foundational vision models that perform both visual generation and understanding.
- Vision Tasks Formatted as Image Generation Tasks: Vision tasks can be parametrized as image generation problems, allowing a single image generator to solve segmentation, depth estimation, and surface normal tasks without any task-specific architecture.
- Efficient and Less Time Consuming Setting: Training a single generalist model for multiple vision tasks is significantly more efficient than training and maintaining separate specialized models, saving time, computational resources and engineering effort.
While lightweight, specialized models like RF-DETR will continue to dominate edge deployments where millisecond latency and compute limits are the priority, the architecture of cloud-based vision pipelines is actively changing. Vision Banana shows potential for movement towards single, unified foundation models that can handle the entire visual spectrum, just by changing the text prompt.
Vision Banana Deployment, Limitations, and Availability
What is Vision Banana?
Vision Banana is a unified model introduced by Google DeepMind that both generates RGB images and performs visual understanding tasks within a single architecture, controlled entirely through text prompts.
Which tasks can Vision Banana perform?
Vision Banana covers three categories of tasks: 2D understanding (semantic, instance, and referring expression segmentation), 3D understanding (metric depth estimation and surface normal estimation), and image generation and editing.
What is Nano Banana Pro and how does it relate to Vision Banana?
Nano Banana Pro is Google DeepMind's latest image generation model, part of the Gemini 3 series. Vision Banana is built on top of this model via instruction-tuning, inheriting all its generation capabilities while adding visual understanding on top.
What is instruction-tuning and why does it matter?
Instruction-tuning is a lightweight fine-tuning process that teaches a pretrained model to follow specific instructions without retraining from scratch. It matters because only a small amount of task-specific data is needed, and the model's original capabilities are preserved.
How is Vision Banana different from specialized models and vision foundation models?
Specialized models can handle only one task at a time, with task-specific architectures and training objectives. Foundation models like DINO have a shared backbone but still use task-specific heads. Vision Banana uses a single model with shared weights, no task-specific architecture and a single prompt to control the task.
How does Vision Banana compare to SAM 3 and Depth Anything 3?
Vision Banana outperforms both, surpassing SAM3 on segmentation and Depth Anything 3 on metric depth estimation. What makes this remarkable is that these are models built exclusively for those tasks, while Vision Banana handles both within a single generalist architecture.
How does Vision Banana compare with DINO?
These models serve different purposes. DINO is primarily a feature extractor. Vision Banana is a generative model that produces task-specific outputs directly. On instance segmentation, where a direct comparison is possible, Vision Banana approaches DINO-X performance but does not surpass it, a strong result for a generalist model not designed specifically for that task.
Does this mean we no longer need specialized models?
Lightweight specialized models remain faster, cheaper, and better understood in production. But Vision Banana challenges the assumption that specialization is necessary for strong performance. For applications that chain multiple specialized models together, such as robotics, autonomous driving and industrial inspection, a single generalist model offers a compelling alternative, significantly reducing complexity and maintenance overhead.
Could this approach work for other tasks like object detection?
The approach is task-agnostic. Any vision output that can be encoded as an RGB image could be tackled using the same framework. Object detection and other tasks are natural extensions, though not yet demonstrated in the paper.
Does Vision Banana work on video?
The paper focuses on static images. Video is a possible next step given that Nano Banana Pro supports video generation.
How can I use Vision Banana outputs in my pipeline?
All outputs are encoded as RGB images and can be decoded back into usable formats, metric depth values, surface normal vectors, or segmentation masks. Decoding varies by task. Semantic segmentation masks are straightforward since colors are explicitly defined in the prompt. Instance segmentation requires clustering pixels by color to identify individual instances, since colors are dynamically assigned. Depth maps require applying the inverse of the color-to-distance mapping used during generation. Surface normals are decoded by converting each channel back from the 0–255 RGB range to the −1 to 1 range.
What are the limitations?
One limitation is that output quality depends on prompt quality. Poorly specified prompts can lead to inaccurate or unexpected outputs. A second concern is latency and computational cost. As a generative model, Vision Banana is expected to be significantly slower and more computationally demanding than lightweight specialist models, though exact inference latency and costs are not discussed in the paper.
Is Vision Banana publicly available?
Vision Banana is not available yet. It has been introduced as a research model and is not available as a public API release. However, the base model, Nano Banana Pro, is available through the Gemini API and Google AI Studio.
Written by Panagiota Moraiti
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (May 1, 2026). Vision Banana: Google DeepMind's Generalist Model. Roboflow Blog: https://blog.roboflow.com/vision-banana/