
DINOv3 is Meta's self-supervised vision foundation model that learns general-purpose visual representations from raw images without any human annotations. Using a teacher-student distillation architecture and large-scale pre-training on datasets including LVD-1689M and SAT-493M, it produces backbones that achieve strong performance across depth estimation, object detection, and segmentation with minimal fine-tuning. The model family spans Vision Transformer variants (ViT-S through ViT-7B) and ConvNeXt variants, and you can fine-tune DINOv3 for classification tasks on Roboflow today.
Building a robust computer vision backbone from scratch requires a massive, perfectly annotated dataset: a luxury most engineering teams simply don’t have.
Enter DINOv3 - the latest model in the DINO (Distillation with No labels) series, developed by Meta. It leverages self-supervised learning (SSL) to produce strong, universal vision backbones that achieve state-of-the-art performance across diverse domains. This capability allows DINOv3 to be utilized across a wide range of computer vision tasks, achieving remarkable performance even with little or no fine-tuning.
Here is a look under the hood at how DINOv3 works, and how you can train and deploy it on Roboflow today.
What Is DINOv3?
DINOv3 is a self-supervised vision foundation model, trained entirely using self-supervised learning without any human annotations. It is designed to learn general-purpose, visual representations directly from raw images by leveraging large-scale pre-training and advanced self-supervised learning techniques.
Self-supervised learning uses techniques to generate its own supervision signals, eliminating the need for costly and time-consuming human annotations. The model learns meaningful representations, by solving tasks derived from the structure of the data itself. When trained on large-scale datasets, it can serve as a strong baseline for a wide range of computer vision tasks.
The term foundation model refers to models trained on massive amounts of data that can be applied to a wide range of tasks. In computer vision, images share common structures and features. A vision foundation model that learns general-purpose representations can be reused across many scenarios, serving as a backbone. A task-specific head can then be attached and fine-tuned using only a small amount of labeled data.
DINOv3 Weights and Code
Meta has released DINOv3 weights for several model variants, including Vision Transformers (ViT-S, ViT-S+, ViT-B, ViT-L, ViT-H+, and ViT-7B) and ConvNeXt variants (Tiny, Small, Base, and Large) pretrained on the LVD-1689M web dataset. Additionally, pre-trained weights are available for ViT-L and ViT-7B models on the SAT-493M satellite dataset. However, both datasets have not been publicly released.
The PyTorch implementation for DINOv3, including the training code, model definitions, and inference utilities is available in a public GitHub repository. DINOv3 can also be accessed and used from the Transformers Hugging Face library, allowing users to easily load pre-trained weights and use the model on downstream computer vision tasks.
DINOv3 License
DINOv3’s code and pre-trained weights are released under a custom DINOv3 License, rather than a standard open‑source license such as MIT or Apache 2.0. DINOv3’s license is a non-exclusive, worldwide, non-transferable and royalty-free limited license to use, reproduce, distribute, copy, create derivative works of, and make modifications to the DINO Materials. Commercial use is permitted. However, redistribution of DINOv3 weights, code, or derivatives, must include the DINOv3 License and comply with its terms.
DINO Evolution
Evolving from its initial breakthrough in 2021 to the massive scale of DINOv3 in 2025, this family of foundation models has continually set new benchmarks for producing sharp, highly transferable visual features across diverse tasks.
DINOv1
DINO (Self-Distillation with No Labels), introduced in 2021, is a self-supervised learning framework that employs a Student-Teacher architecture to generate and leverage its own supervisory signals. This approach enables the model to learn meaningful and intuitive feature representations without relying on labeled data.
The DINO paper shows that self-supervised vision transformers (ViTs) learn feature representations that capture semantic segmentation information, even though they are never explicitly trained for segmentation tasks. Additionally, the representations learned by self-supervised vision transformers tend to be sharper and more focused on the object of interest, as illustrated in the image below.

These feature representations prove highly effective for k-NN (k-Nearest Neighbor) classification, demonstrating that the learned feature space is well-structured and semantically organized. As illustrated in the following image, samples belonging to similar object categories are grouped closely together in the embedding space, forming well-defined and compact clusters.

In the image below, the self-attention maps of DINO for several images are shown. We observe that the model automatically learns class-specific features leading to unsupervised object segmentations.

DINOv2
The DINOv2 model, released in 2023, demonstrates that large scale self-supervised pre-training on a large amount of diverse, curated data can produce general-purpose visual features that transfer well across different image distributions and tasks without fine-tuning. It establishes a strong baseline for foundation models in computer vision, similar to the role of large language models in natural language processing.
DINOv2 builds on the DINO architecture, with both the model and dataset significantly scaled. It is trained on 142 million curated images, the output dimension is increased from 65K to 128K, and the larger model has a total of 1.1 billion parameters. Additionally, it incorporates an enhanced centering method (Sinkhorn-Knopp centering) along with a regularization term (KoLeo regularizer) that encourages diverse feature learning and uses a larger batch size of 3K during training.
Together, these improvements enable DINOv2 to produce significantly stronger and more transferable visual representations. Another improvement is the patch-level losses that force the model to learn more fine grained patch-level features, further enhancing the produced feature representations.
DINOv3
DINOv3, released in 2025, is the latest model in the DINO series. It further scales both the dataset and model size, using a curated dataset of 1.7 billion images for training and a model with 1 billion parameters. A new technique called Gram Anchoring is introduced to address the known issue of dense feature maps degrading during long training schedules.
DINOv3 achieves outstanding performance across a broad range of vision tasks, significantly surpassing previous self-supervised and weakly-supervised foundation models. It produces sharper, higher-quality dense features with reduced noise and improved semantic coherence compared to previous versions.
The image below illustrates a comparison of dense features across several vision backbones. Notably, DINOv3 generates the highest-quality feature maps, exhibiting sharper object boundaries and greater semantic clarity than all other models.

The following image shows the evolution of DINO. On the left, observe the features from DINOv1, in the center those from DINOv2, and on the right those from DINOv3. It is evident that DINOv3 produces the most clear and precise representations.

How DINOv3 Works
DINOv3 is trained using a self-supervised teacher-student architecture, in which a teacher model guides the learning of a student model without any labeled data. This approach is inspired by knowledge distillation. But adapted to operate entirely in a self-supervised setting without the need for labeled data.
Self-Supervised Learning
Self-supervised learning (SSL) is a machine learning paradigm, which leverages large amounts of unlabeled data to train models. In SSL, the loss function is designed to generate a supervision signal without relying on human-provided labels.
A key concept in SSL is pretext tasks, which are auxiliary tasks where the labels are automatically derived from the structure of the data itself, allowing the model to learn useful representations without human annotation. The goal is not to solve the given task, but to learn meaningful features in the process of solving it.
Some common pretext tasks used to train vision models include:
- Colorization: The model is given a grayscale version of an image and must predict the original colors.
- Rotation Prediction: The model is trained to recognize the degree of rotation applied to an image (e.g., 0°, 90°, 180°, 270°).
- Image Inpainting: Parts of an image are masked out, and the model must reconstruct the missing regions.
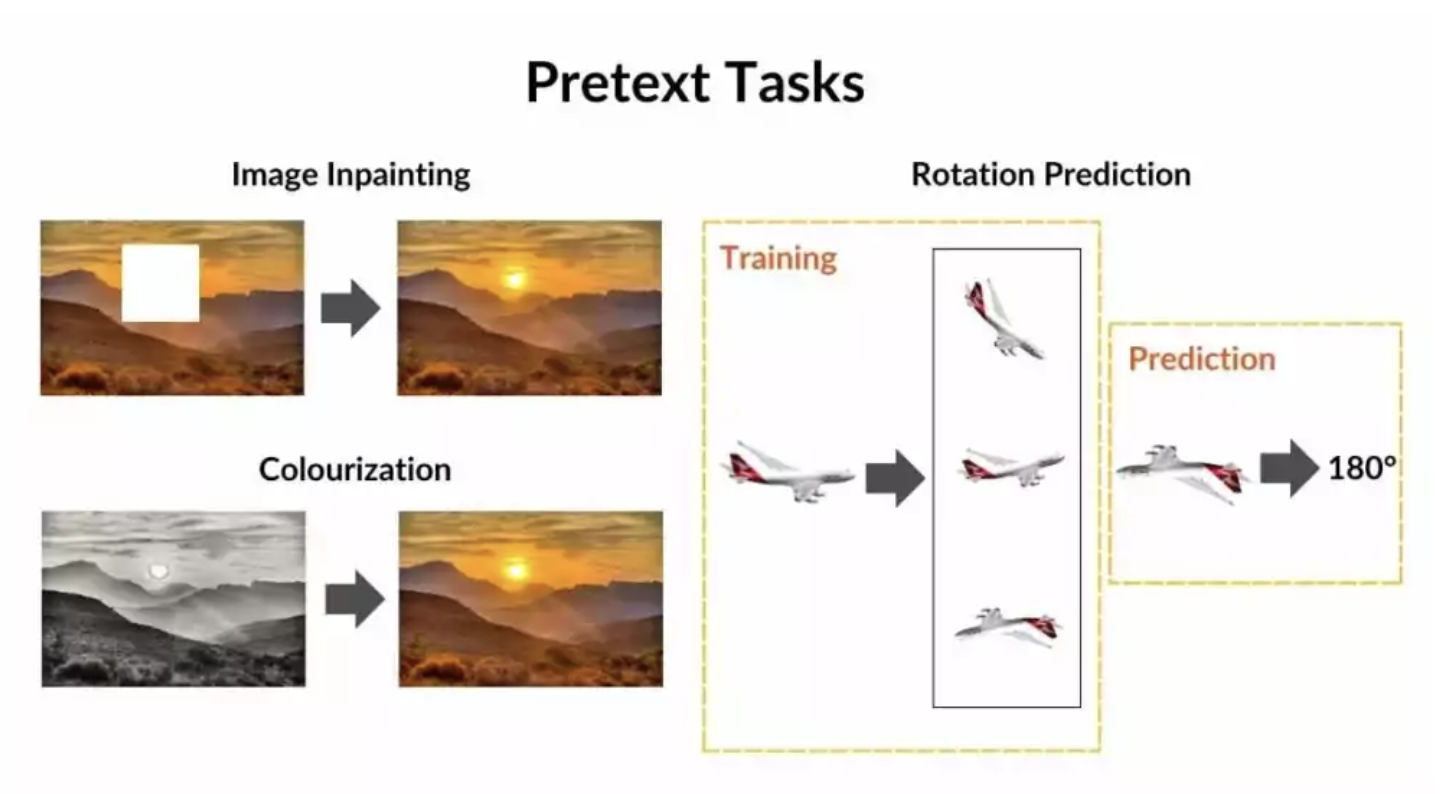
These pretext tasks serve as supervision signals that enable models to learn rich, transferable feature representations. To solve them, the model must understand object structures, textures, orientations, spatial relationships, as well as both local details and global context.
The SimCLR paper employs contrastive learning and data augmentations to generate supervision signals from images without using any labels. In contrastive learning, the model learns meaningful representations by bringing together similar data points (positive pairs) and pushing apart dissimilar ones (negative pairs).
SimCLR uses two augmented views of the same image to create positive pairs. A teacher-student framework of two identical models is utilized to extract feature representations from both views. Then, pair-wise similarities (cosine similarities across all samples in a batch) are computed. The contrastive loss function aims to bring the features of matching pairs closer in the embedding space, while pushing features of different images farther apart.
The following image illustrates the SimCLR framework. We observe that representations of two different augmented views of the same image are encouraged to be similar (attract each other), while representations of views from different images are encouraged to be dissimilar (repel each other).
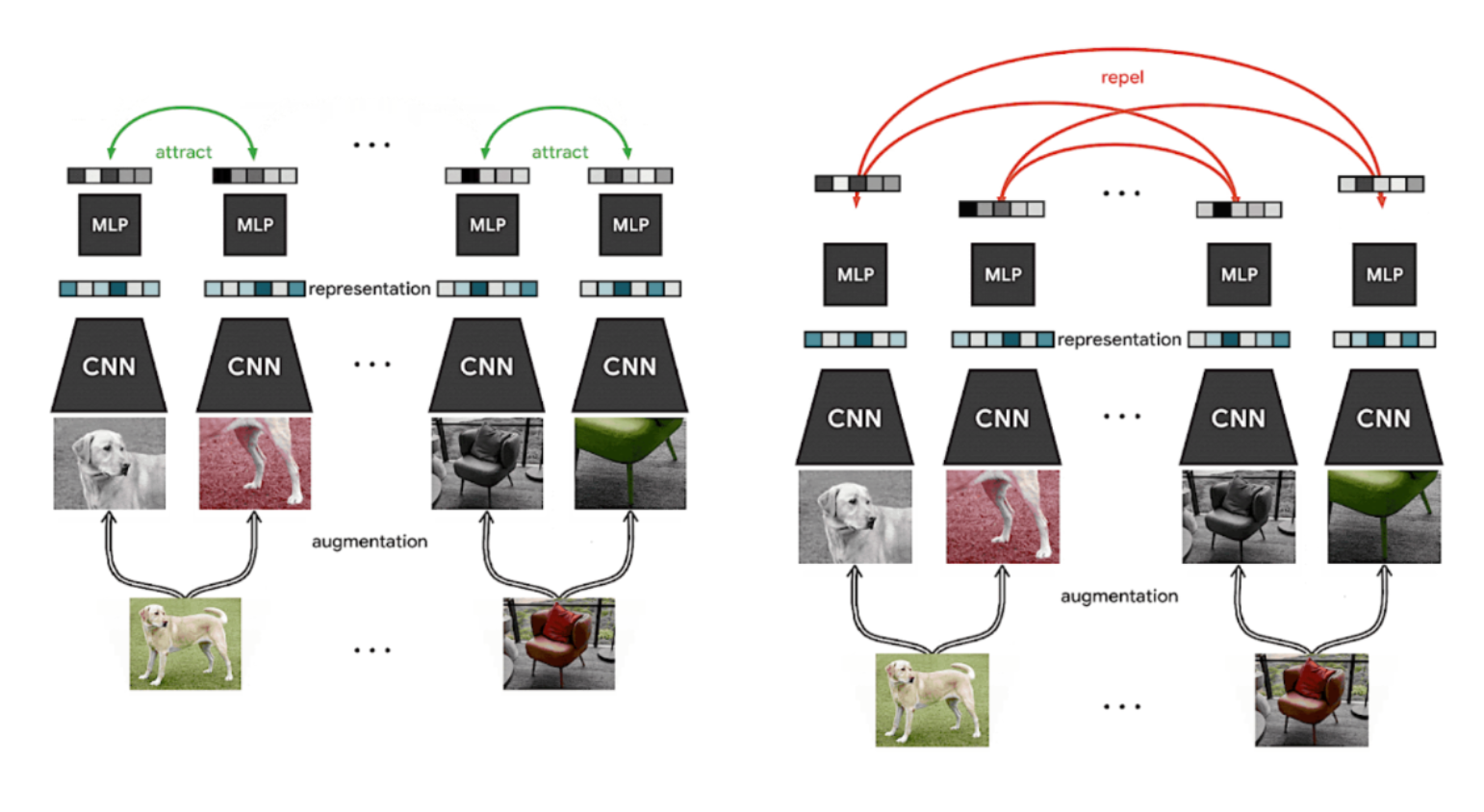
One limitation of contrastive learning is that it requires many negative samples to create meaningful representations. This typically necessitates large batch sizes, making the approach computationally expensive. To address this issue, DINO adopts a teacher-student architecture. But replaces contrastive loss with a cross-entropy loss, thereby eliminating the need for a large number of negative samples.
DINOv3 Teacher-Student Architecture
DINO utilizes the same architecture introduced in the BYOL paper. But with a different loss function, along with some additional improvements. Specifically, it replaces BYOL's MSE (Mean Squared Error) loss with a cross-entropy loss.
Additionally, it eliminates the need for an extra prediction head, resulting in the same design for student and teacher networks. Each model consists of a vision transformer backbone followed by a projection head implemented as a multilayer perceptron, which is discarded after training.
The teacher-student architecture is inspired by knowledge distillation, where a pre-trained, typically larger teacher model transfers its knowledge to a smaller, more efficient student model. However, in BYOL and DINO, both networks share the same architecture, and the teacher is not pre-trained but instead learned jointly with the student.
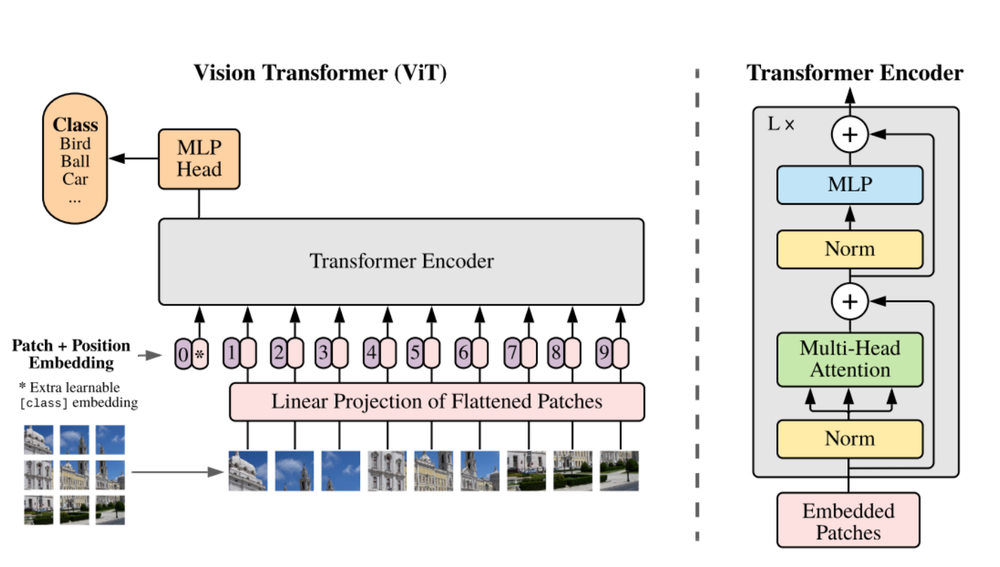
In the image below, the architecture of the vision transformer is illustrated. The input image is first divided into fixed-size patches, which are flattened and linearly projected into patch embeddings. Positional embeddings are added to preserve spatial information. The resulting embeddings are then processed by a standard transformer encoder.
Through self-attention, each token can attend to all others, allowing it to capture information from the entire image rather than only its local neighborhood. In ViT, multi-head attention is utilized, with multiple self-attention heads operating in parallel, allowing the model to attend to different relationships between image patches simultaneously.
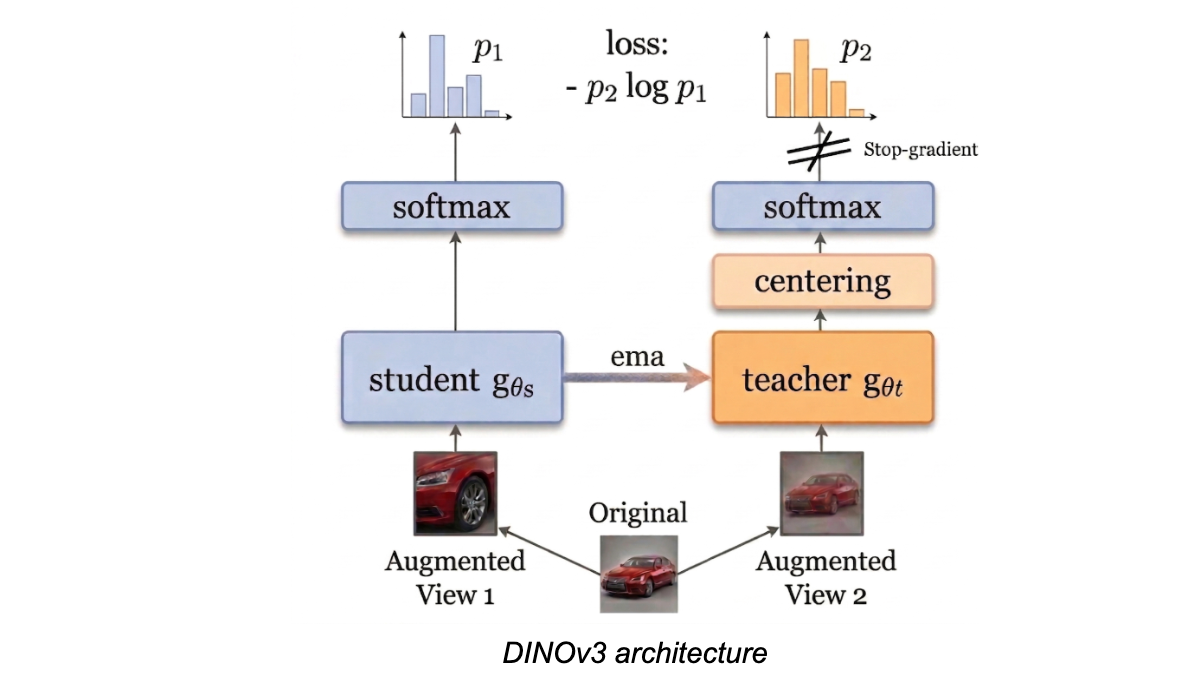
As mentioned above, DINOv3 consists of two identical ViTs, known as the teacher and the student models. Each model receives as input one random augmented view of the original image. Their outputs are passed through a softmax activation function to produce a probability distribution of each prediction. The cross-entropy loss is then used to align the predicted probability distribution of the student to that of the teacher.
During training, only the student network is updated via backpropagation, while a stop-gradient operation is applied to the teacher to prevent direct weight updates. Instead, the teacher’s parameters are updated using an exponential moving average (EMA) of the student’s parameters, enabling the teacher to provide stable targets throughout training.
At the beginning of training, the student is updated more rapidly, while the teacher evolves more gradually due to the exponential moving average mechanism. As a result, the teacher provides a stable target for the student. The teacher’s weights are updated using EMA according to the following formula:
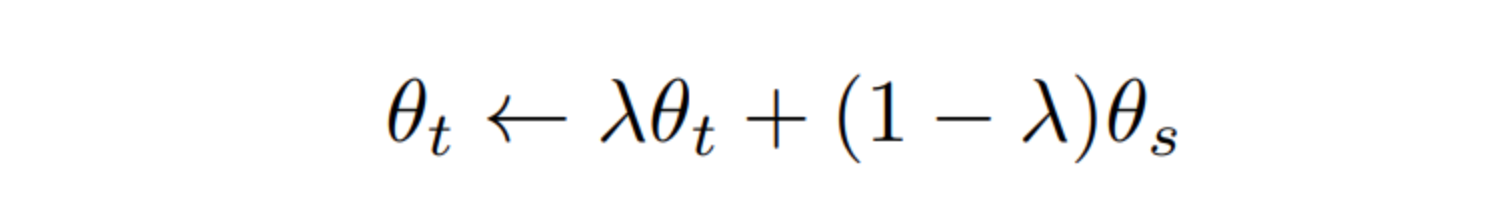
The hyperparameter λ controls the update rate of the teacher and follows a cosine schedule from 0.996 to 1 during training. This means that the teacher is updated more at the beginning, and its updates gradually become smaller as training progresses. As λ approaches 1, the teacher’s weights change more slowly, meaning they remain largely stable and only incorporate small updates from the student model.
Because the teacher is not pre-trained, but softmax requires a fixed number of classes to operate, the output dimension is set to a very large value (65K). This allows the model to represent many feature concepts, without relying on predefined classes. As a result, it can discover more fine-grained structures and more specific visual concepts.
For instance, a traditional model trained on ImageNet in a supervised manner, may learn a general representation for cats. Whereas DINO can learn to represent more detailed attributes such as a cat’s face, tail, whiskers and ears separately. For this reason, self-supervised features are often more detailed and informative than those learned through traditional supervised learning.
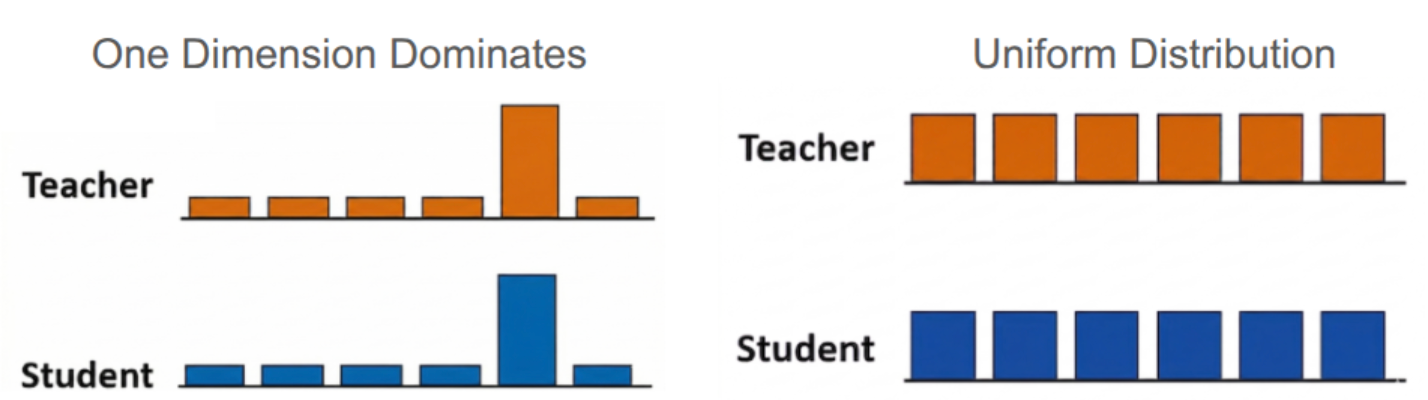
One problem with this architecture is model collapse, where the network converges to a trivial solution by outputting the same constant representation for every input, regardless of content. In such cases, a single dimension may dominate the distribution, leading to uninformative representations.
To mitigate this, DINO applies centering before the softmax operation by subtracting a running mean (computed as an exponential moving average of the batch mean) from the teacher’s outputs. This encourages the predictions to be more evenly distributed across dimensions.
Another potential issue is collapse to a uniform distribution across all outputs, which also does not produce useful representations. DINO addresses this by lowering the softmax temperature, which sharpens the output distribution. This sharpening increases the probability of the most activated dimensions and helps prevent the model from producing uniform predictions.
Finally, DINO utilizes multi-crop training, where multiple views of the same image are generated at different scales during training: two large global crops and several smaller local crops. The student processes all crops, while the teacher processes only the global views. This mechanism encourages the student to align local representations with global ones, helping the model capture both fine-grained details and overall image context.
For example, given an image of a cat, a local crop might contain only the cat's eye, while a global crop shows almost the entire cat. The student must learn that the eye patch corresponds to the same object as the full image, encouraging understanding of both local details and global structure. By utilizing local crops, the model also learns to focus on the object of interest rather than background or irrelevant context.
Large Scale Pre-training
DINOv2 and DINOv3 show that self-supervised learning can benefit from large scale pre-training on curated data. Data curation is the process of carefully selecting, filtering, and organizing data to ensure high quality and diversity, while removing noisy, redundant, or irrelevant samples that could hurt the learned representations. A key finding from both works is that data quality is as important as scale. A smaller, curated dataset consistently outperforms a larger but noisier one, challenging the common assumption that more data is always better.
In DINOv3, data curation starts from a pool of approximately 17 billion web images, from which three datasets are created. The first dataset is created by applying hierarchical k-means clustering over DINOv2 embeddings. The second is generated by using retrieval-based curation to find images similar to existing curated datasets, covering concepts relevant to downstream tasks. The third incorporates raw publicly available datasets to further optimize model performance.
Overall, this multi-stage curation pipeline ensures a diverse, high-quality training set that enables DINOv3 to learn more robust and transferable visual representations.
DINOv3 Additional Enhancements
A problem observed in DINOv2 representations is the degradation of feature quality over time. As training progresses, the learned features become less localized and the similarity maps become increasingly noisier, leading to a decline in segmentation performance. However, more training iterations can still improve classification performance.
The following image illustrates the cosine similarity between different image patches produced by DINOv2.
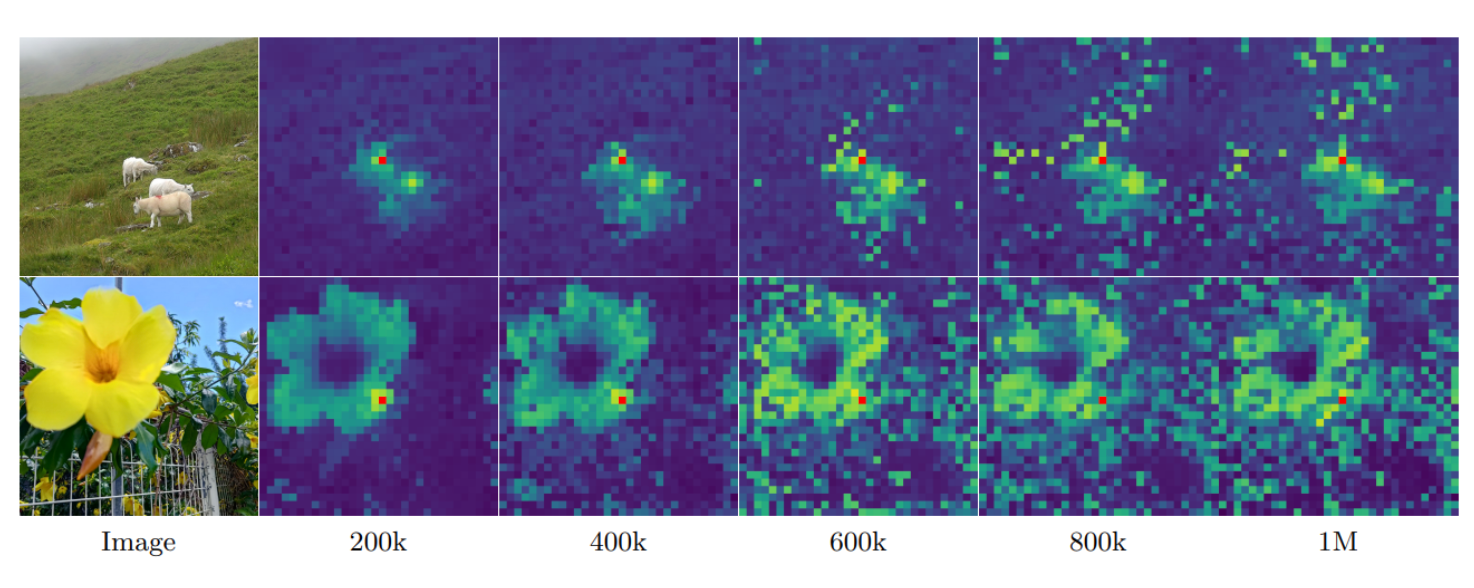
To mitigate the aforementioned issue, DINOv3 introduces the Gram Anchoring technique. A gram matrix is computed for both the teacher and the student, containing pairwise similarities between patch features. A gram loss is then applied to encourage the student’s gram matrix to resemble that of the teacher. This constraint helps preserve spatial relationships between local patches, resulting in sharper feature representations with better semantic coherence.
In the image below, we can observe that after applying Gram Anchoring, the feature representations become less noisy and more spatially precise, better preserving segmentation quality.

Additionally, DINOv3 utilizes a high-resolution fine-tuning stage that adapts the pre-trained model to handle images beyond standard training resolutions, sharpening spatial detail and improving local feature fidelity. This stage makes DINOv3 resolution agnostic. The model learns to generalize across varying resolutions at inference time. As a result, DINOv3 can process real-world inputs ranging from standard to high-resolution images without any architectural modifications, preserving fine-grained details that fixed-resolution models would otherwise lose due to aggressive downsampling.
DINOv3 Family of Models
DINOv3 includes a family of models designed to accommodate different computational budgets and application requirements. The smaller variants are obtained through knowledge distillation from the large ViT-7B model, allowing them to retain a substantial portion of the performance of the larger model while significantly reducing latency and computational cost.
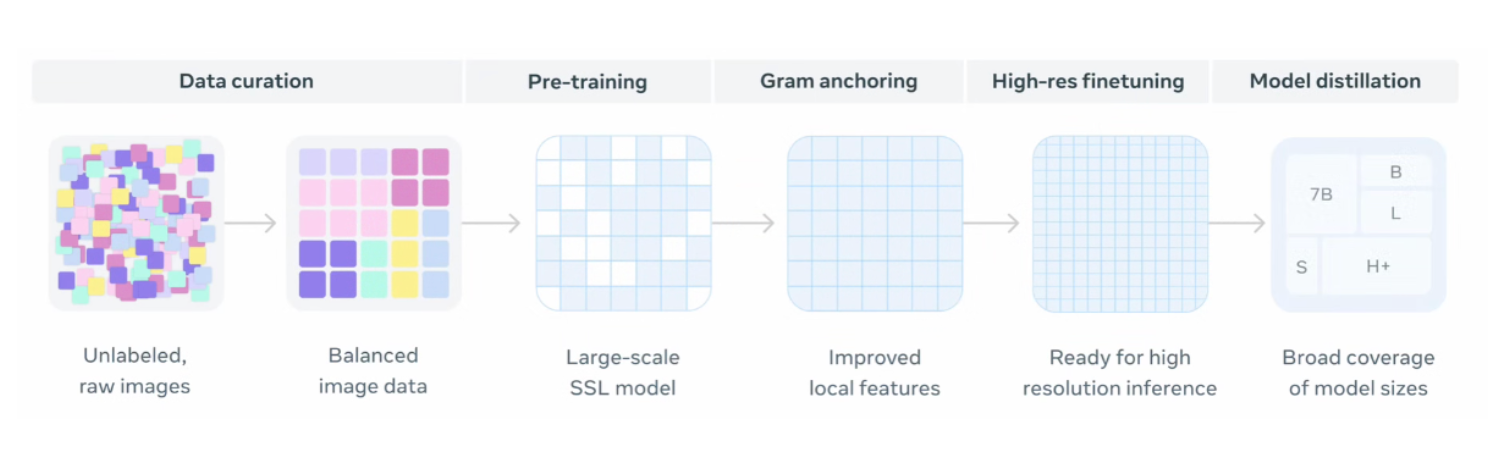
This image below illustrates the DINOv3 training pipeline, which begins with data curation, transforming large amounts of unlabeled raw images into a balanced dataset. The curated data is then used to pre-train a large-scale self-supervised learning model, followed by the Gram Anchoring technique, which improves local feature representations. The model then undergoes high-resolution fine-tuning and finally model distillation is applied to produce a family of models of different sizes, enabling deployment across a wide range of scenarios.
What DINOv3 Can Do
DINOv3 can be used for a wide variety of computer vision downstream tasks with minimal fine-tuning. The DINOv3 backbone is kept frozen and a task-specific head is added on top. Only this head requires training for a limited number of epochs.
The image below shows that features are extracted from the frozen DINOv3 model, which serves as the backbone. These general purpose features are then passed to task-specific heads, referred to as task adapters, which can be used for different tasks.
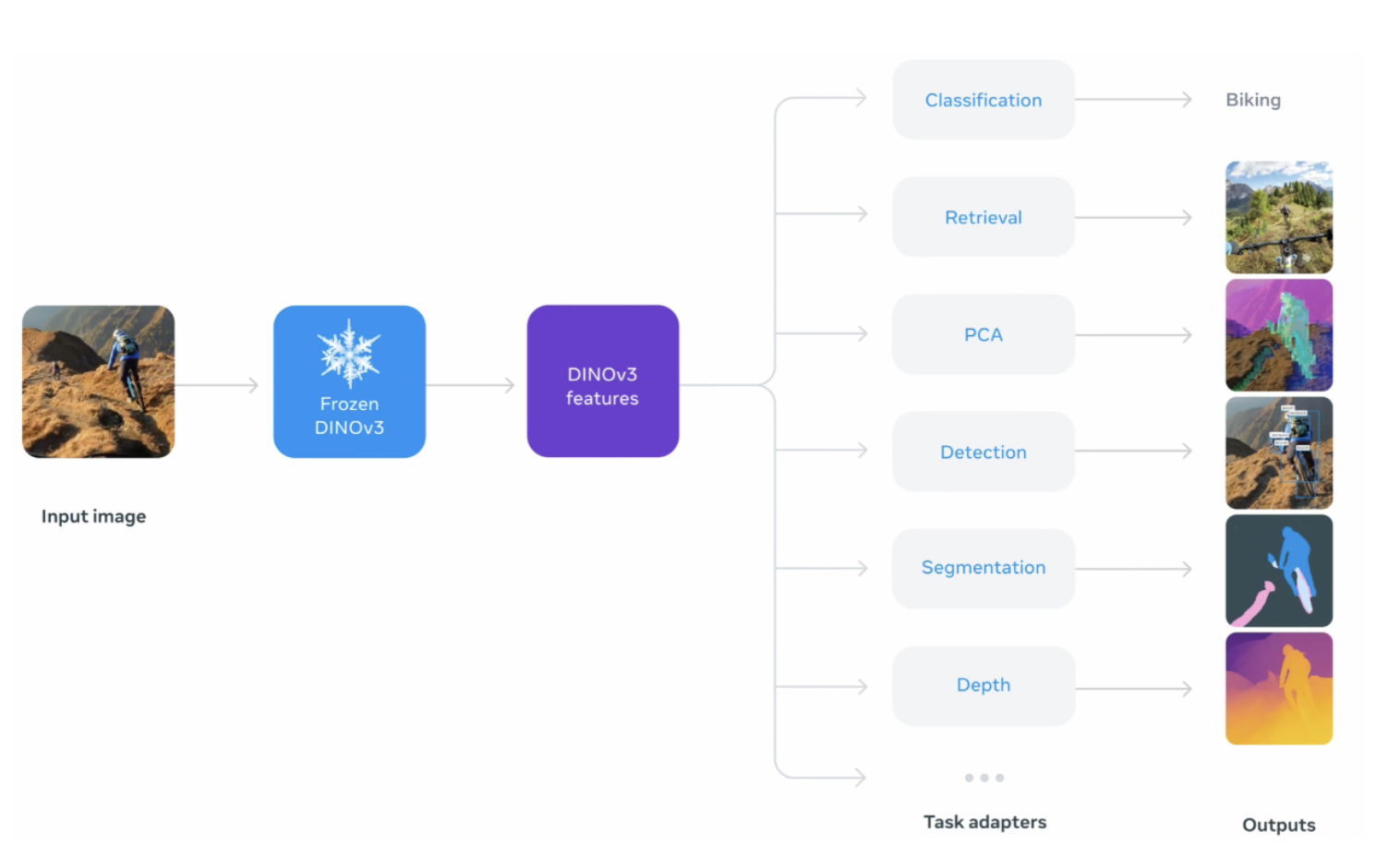
DINOv3 excels in the following computer vision tasks:
- Image classification: DINOv3 can be used to assign a single label to an entire image based on its learned global representation.
- Fine-grained image classification: This task aims to identify images between visually similar subcategories, such as different species of birds or dog breeds. This is possible because DINOv3 features capture subtle visual details.
- Object detection: DINOv3 can localize and identify multiple objects within an image. Its patch-level features help in predicting bounding boxes and class labels for each object.
- Semantic segmentation: This task assigns a class label to every pixel in an image. By leveraging the fine-grained features of DINOv3, the model can accurately distinguish between different objects and regions, producing precise boundaries and detailed spatial understanding. Notably, DINOv3 also learns feature representations that inherently encode semantic segmentation structure even before a dedicated segmentation head is added, a characteristic commonly observed in self-supervised transformers.
- Depth estimation: DINOv3 can predict relative or absolute depth from a single image. Its features encode spatial structure, helping infer how far objects are from the camera.
- Video tracking: Consistent feature embeddings enable DINOv3 to track objects across video frames, even under challenging scenarios such as occlusion, overlap, or changes in object appearance.
- Instance retrieval: DINOv3 can retrieve visually similar images from a dataset based on a query image. A query image is an input image provided to the model as a reference for searching similar examples. The fine-grained features learned by DINOv3 enable effective similarity matching.
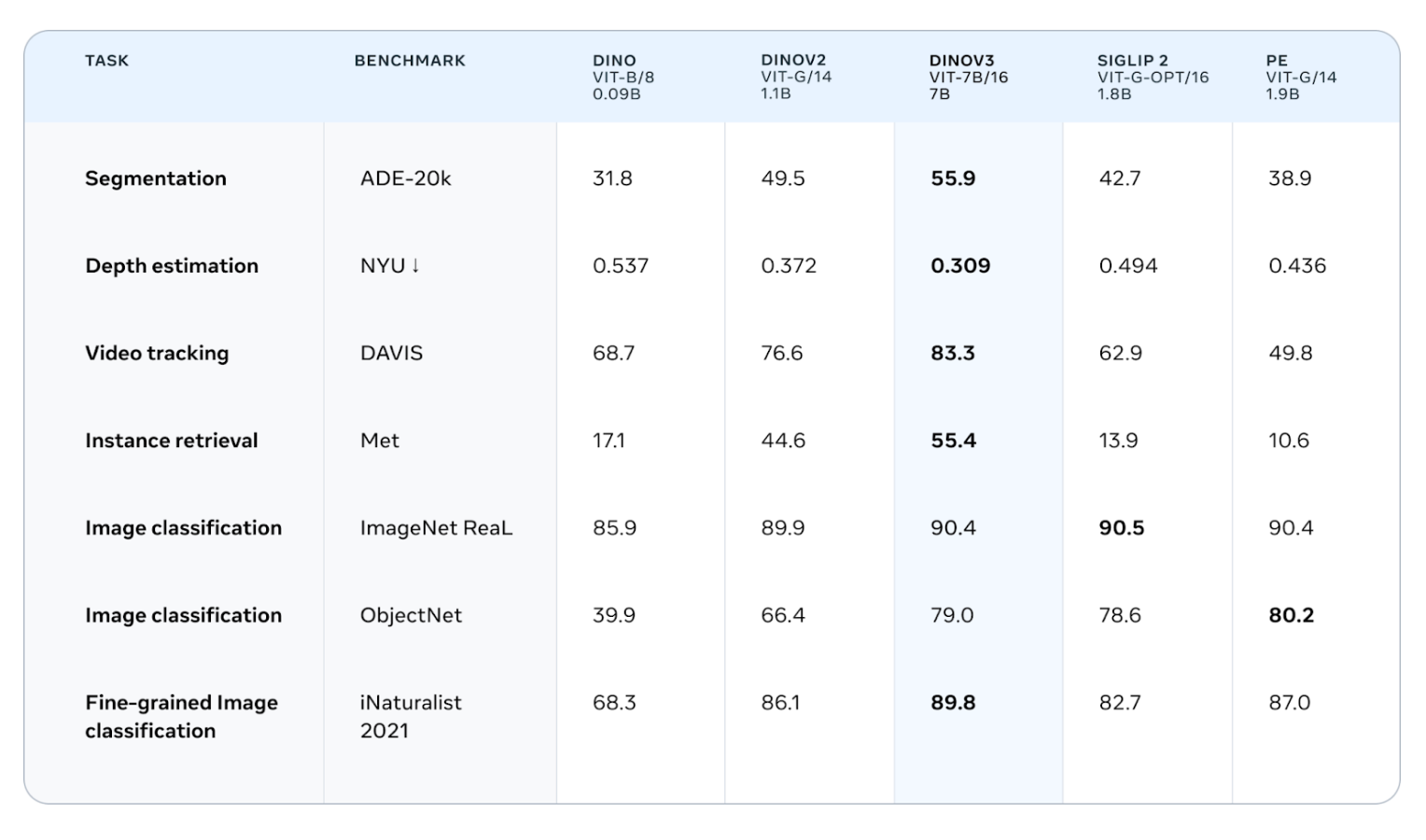
DINOv3 has set a new state-of-the-art in vision foundation models. It is the first time a model trained with SSL outperforms weakly-supervised models across a broad range of tasks. The following table reports DINOv3’s performance across multiple datasets and vision benchmarks.
How to use DINOv3 with Roboflow
You can train the DINOv3 model for classification on Roboflow today. In order to do this you will need a Roboflow account and a Roboflow classification dataset.
You can create a new Roboflow dataset by following the steps below. More information can be found one the Create a Project and Upload Images, Videos, and Annotations pages.
Create a Roboflow Dataset
Step 1: Create a new project.
Step 2: Enter a project name, choose classification type and click the Create Public Project button.
Step 3: Upload images.
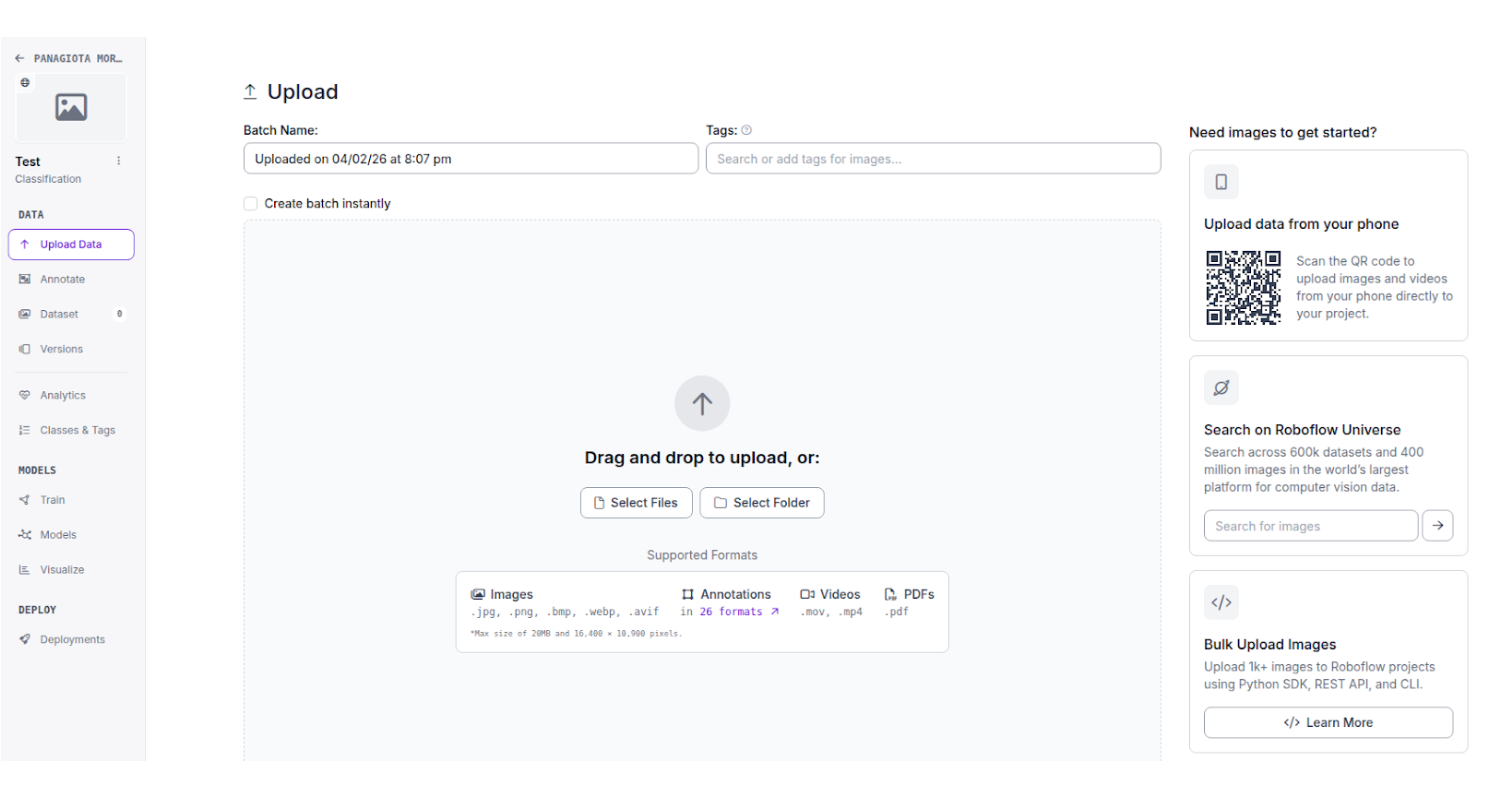
Fork an Existing Roboflow Dataset
Alternatively, you can fork an existing dataset from Roboflow Universe. More information can be found on the Fork a Universe Dataset page.
In this example, we will use this dataset, containing images of 30 different types of agricultural crops.
Step 1: Find the project and fork the dataset.
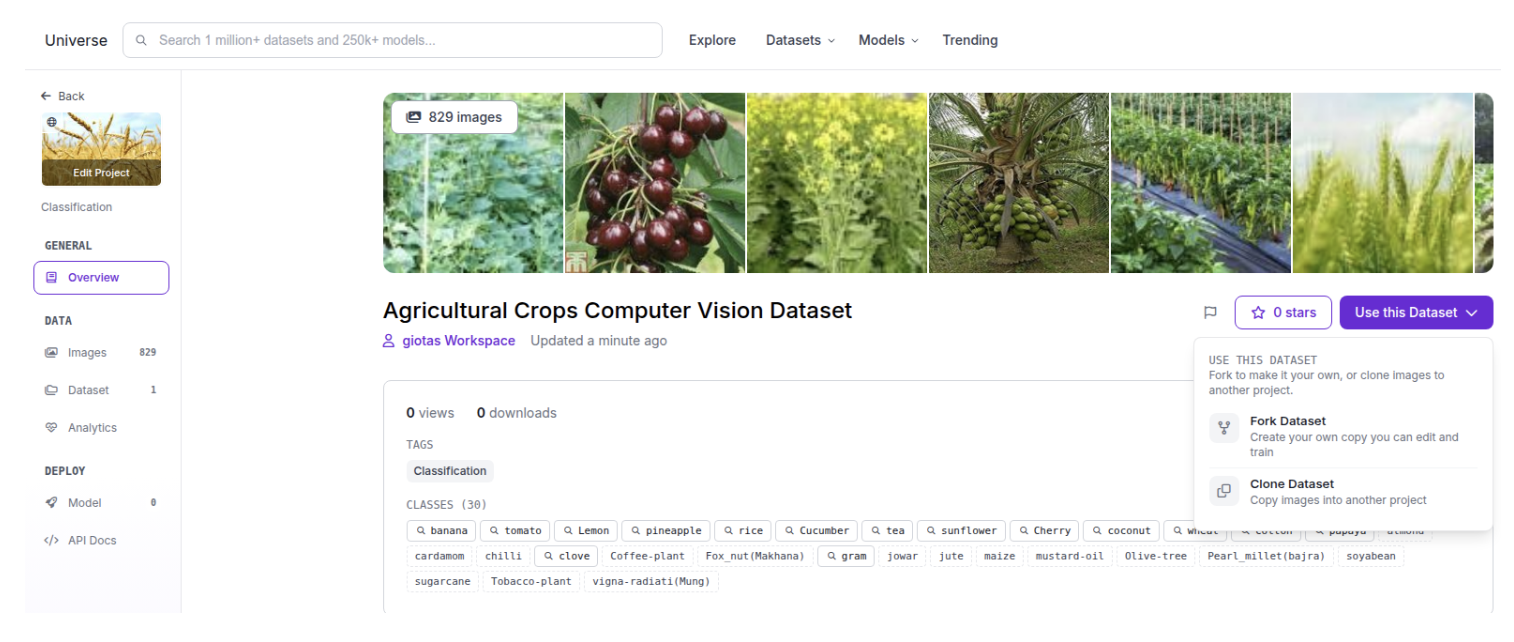
Step 2: Click on the Fork Dataset button.
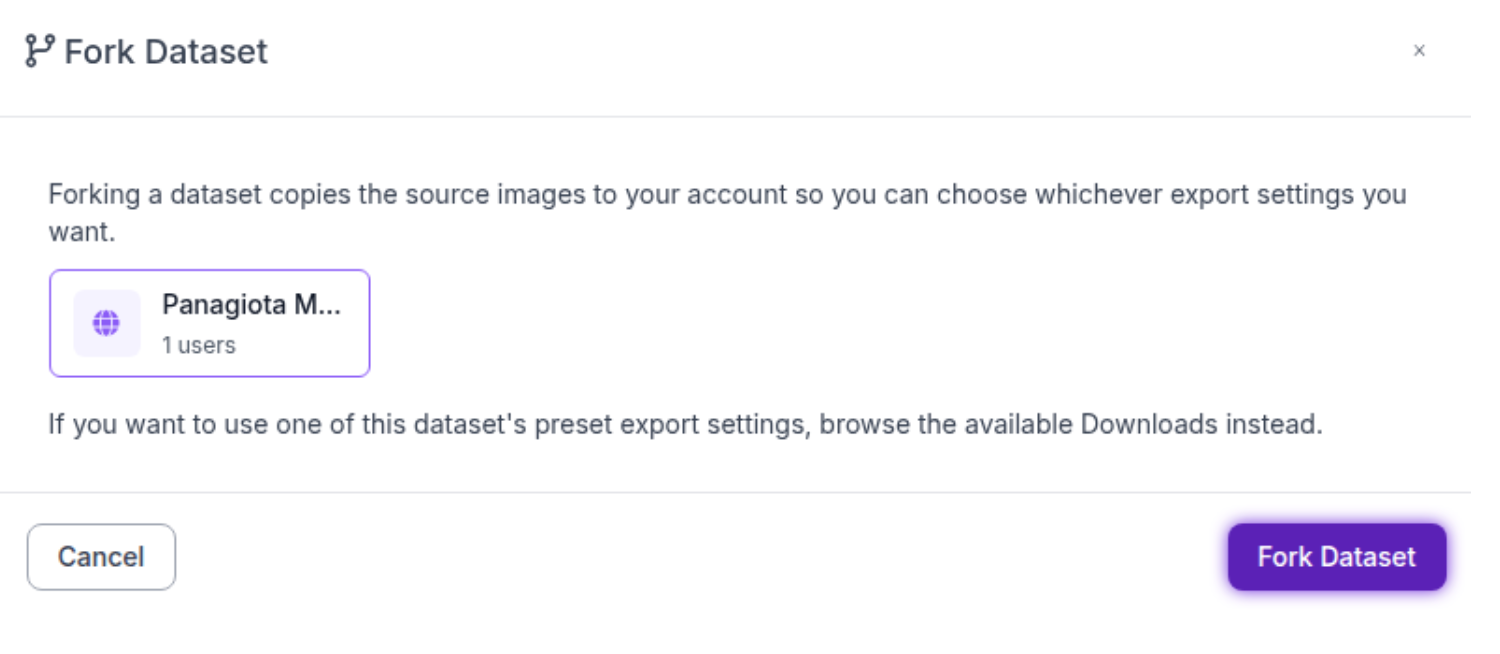
Train DINOv3 with Roboflow
Now that we have created a classification dataset, we can use it to train the DINOv3 model.
Step 1: Choose model architecture.
Both Small and Base variants are available, but we will use the Small variant for faster training and inference.
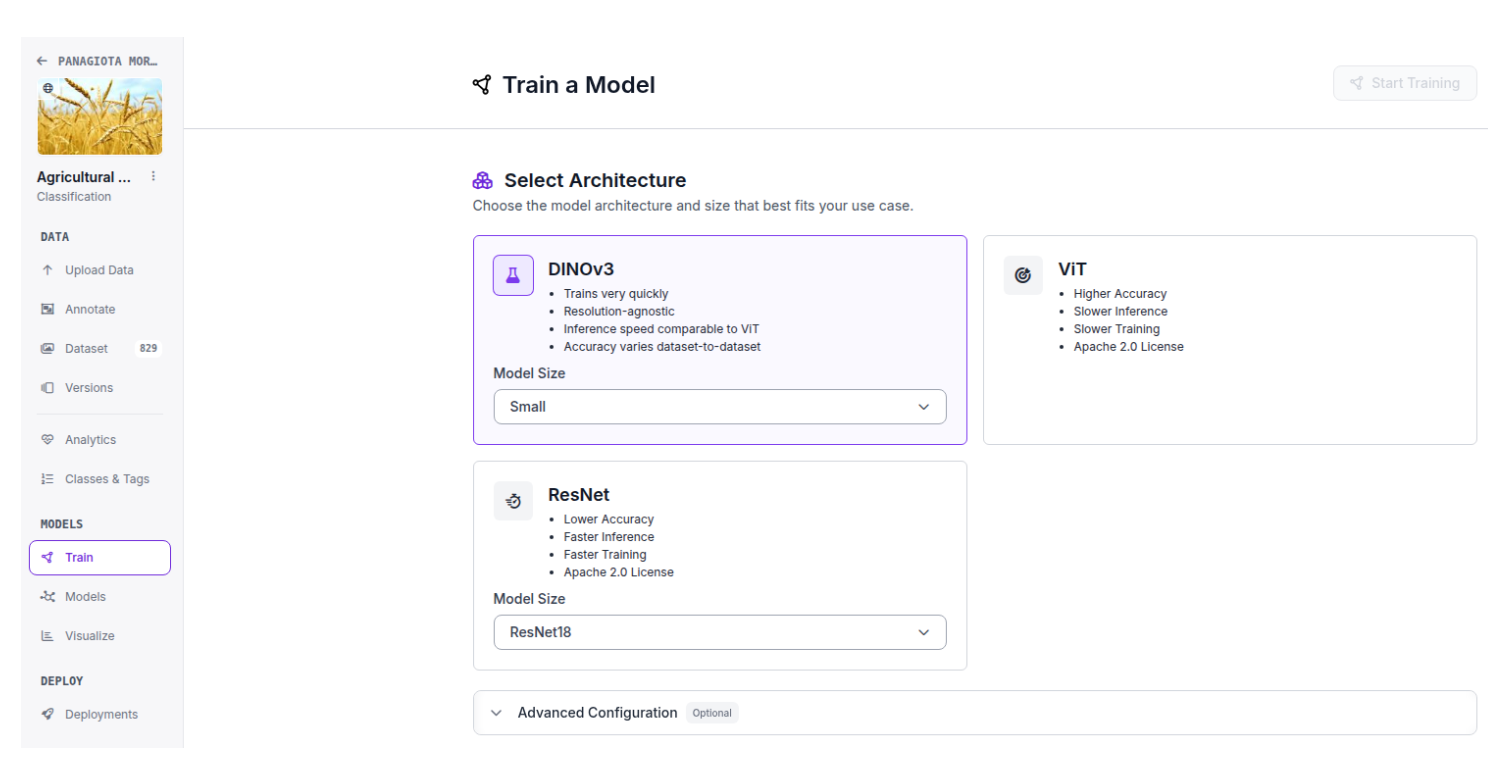
Step 2: Select number of epochs.
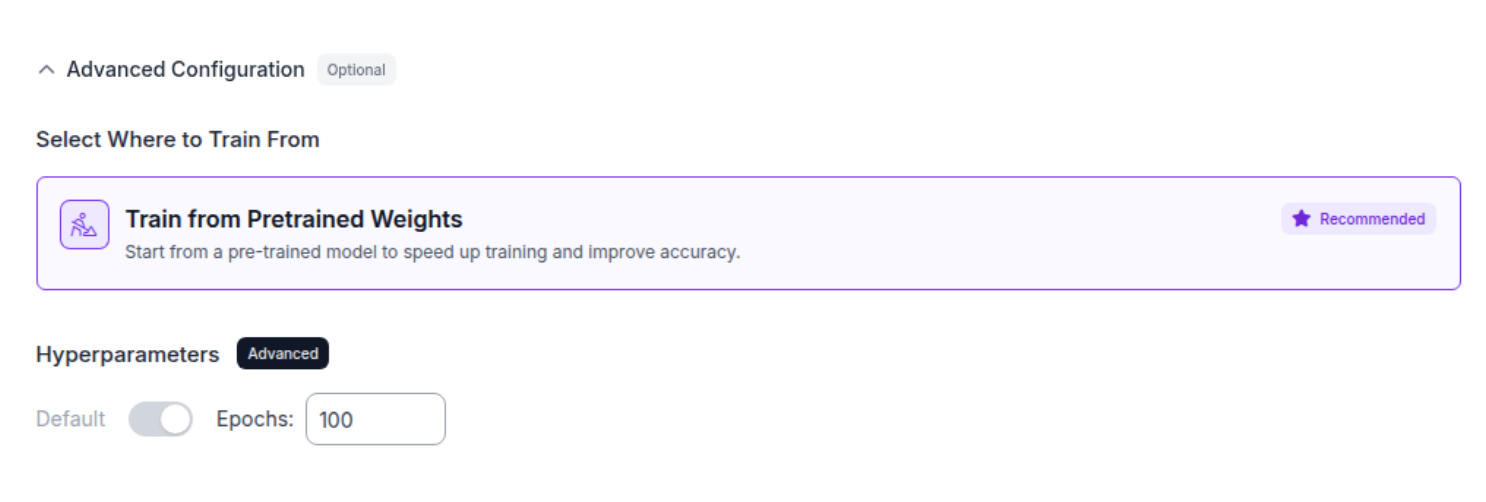
It is important to keep the default option, train from pretrained weights, as this allows the model to leverage its existing knowledge and begin training from a strong starting point. This approach, known as transfer learning, is especially important in computer vision, since all images share common low-level features such as edges, textures and shapes.
We choose 100 epochs because our dataset is relatively small, to ensure sufficient training and prevent overfitting.
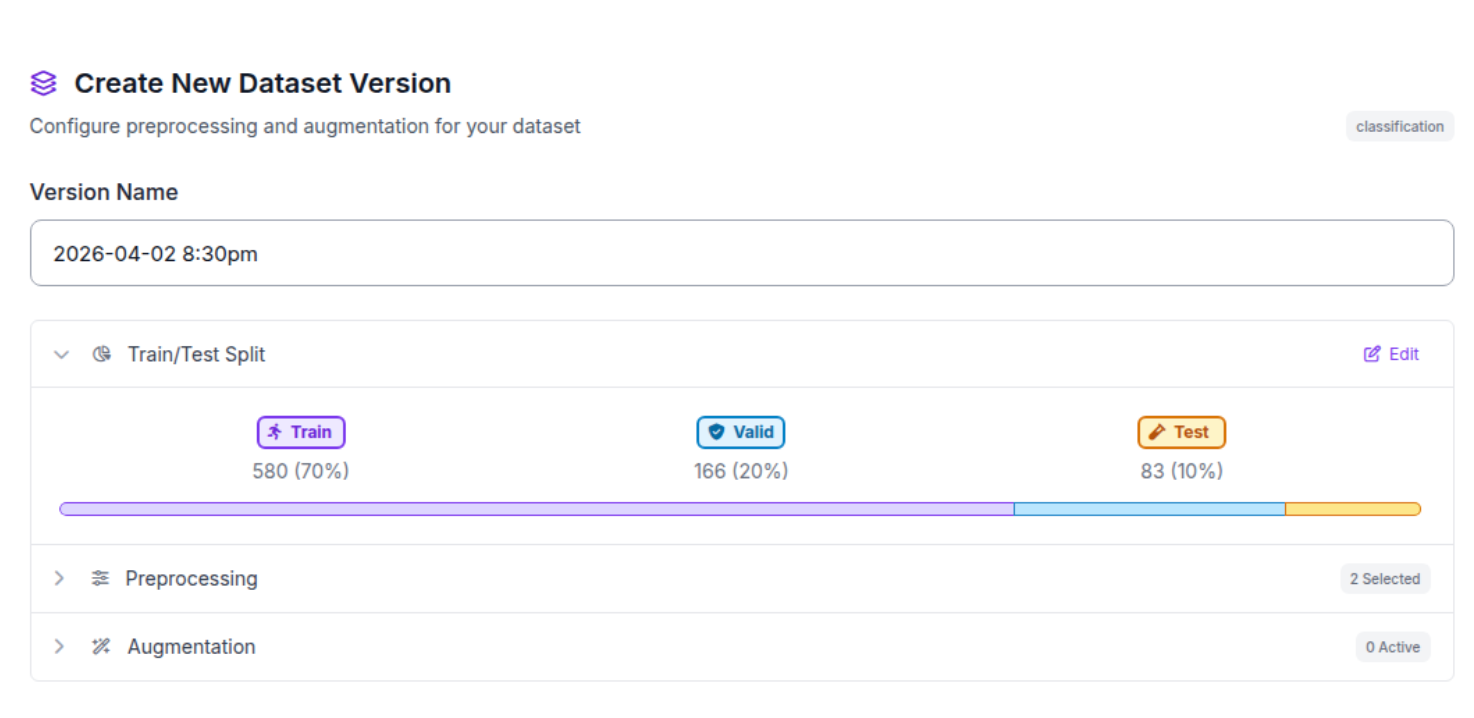
Step 3: Dataset split, Preprocessing, Augmentations.
We will keep the default dataset split, disable resizing in preprocessing, and apply no augmentations.
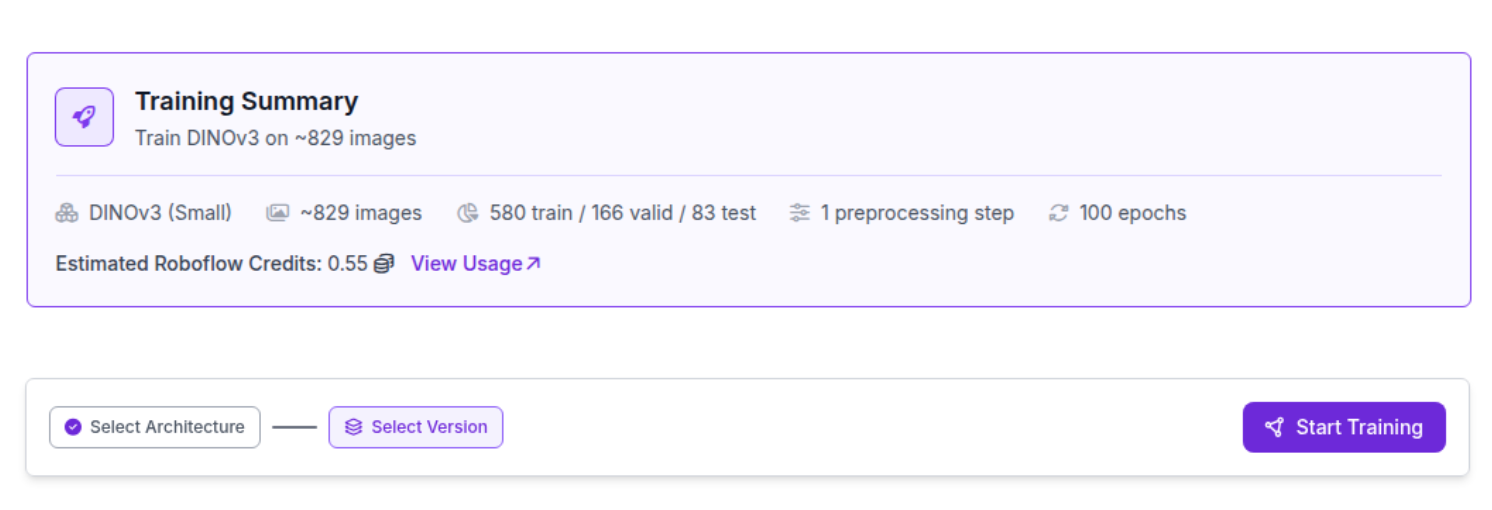
Step 4: Start training.
Finally, we click Start Training.
We will receive an email notification once the training is complete.
I received the following email:

Test DINOv3 with Roboflow
In your project you can click on Models and observe the training results.
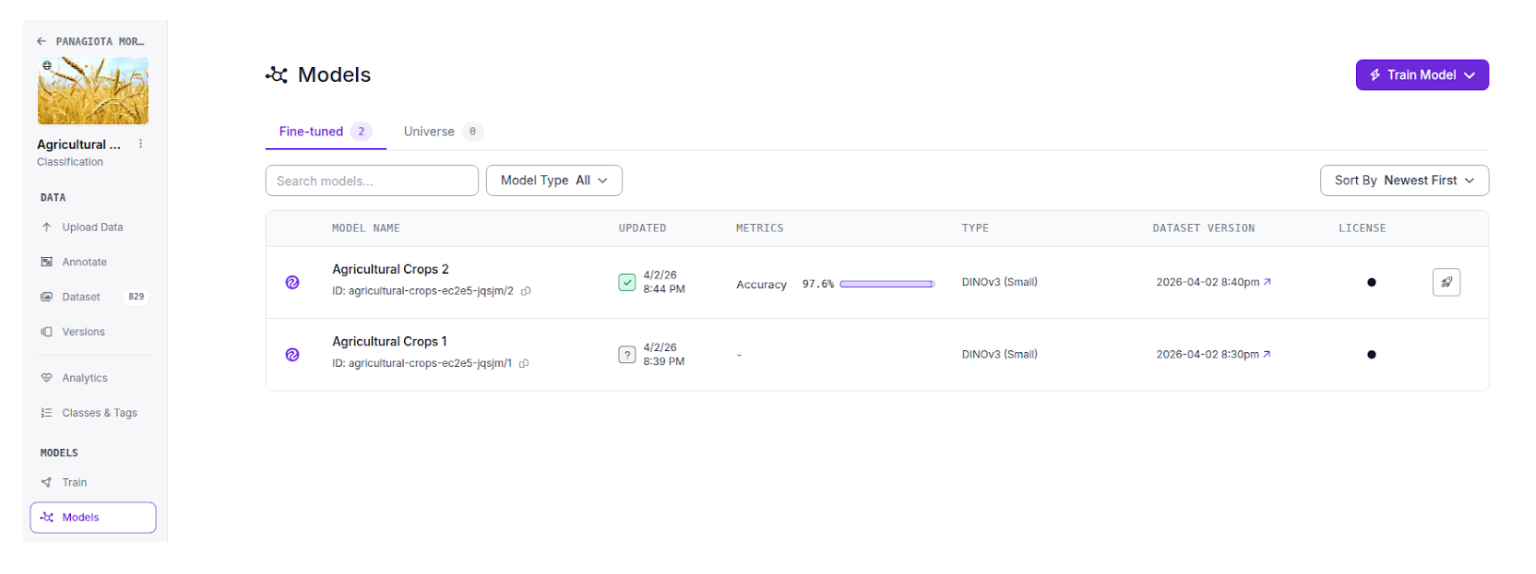
Click on visualize to test your model on your own images.
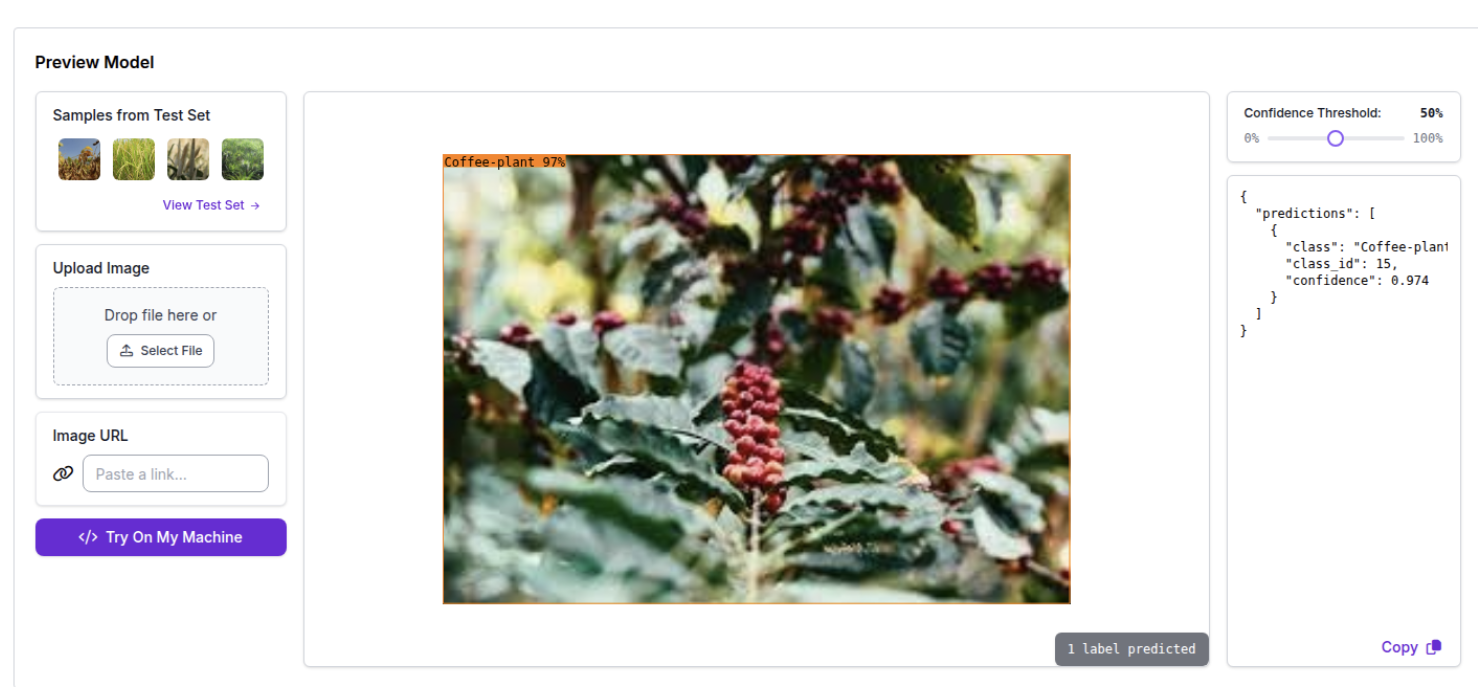
Below we can observe the performance of DINOv3 on several images downloaded from Google. The model demonstrates strong classification capabilities, often achieving confidence levels exceeding 97%.



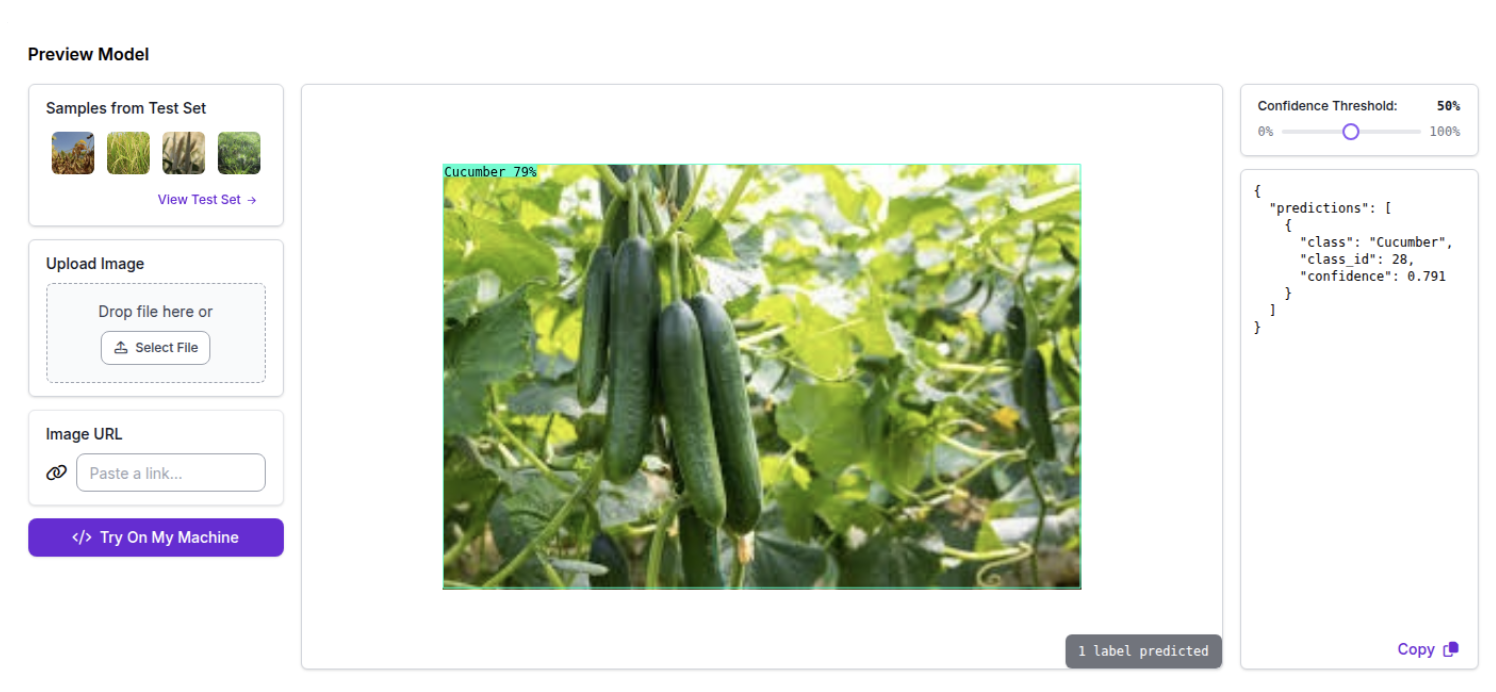
In the following images, the model finds the task more challenging, possibly because some of the samples deviate from the training distribution.
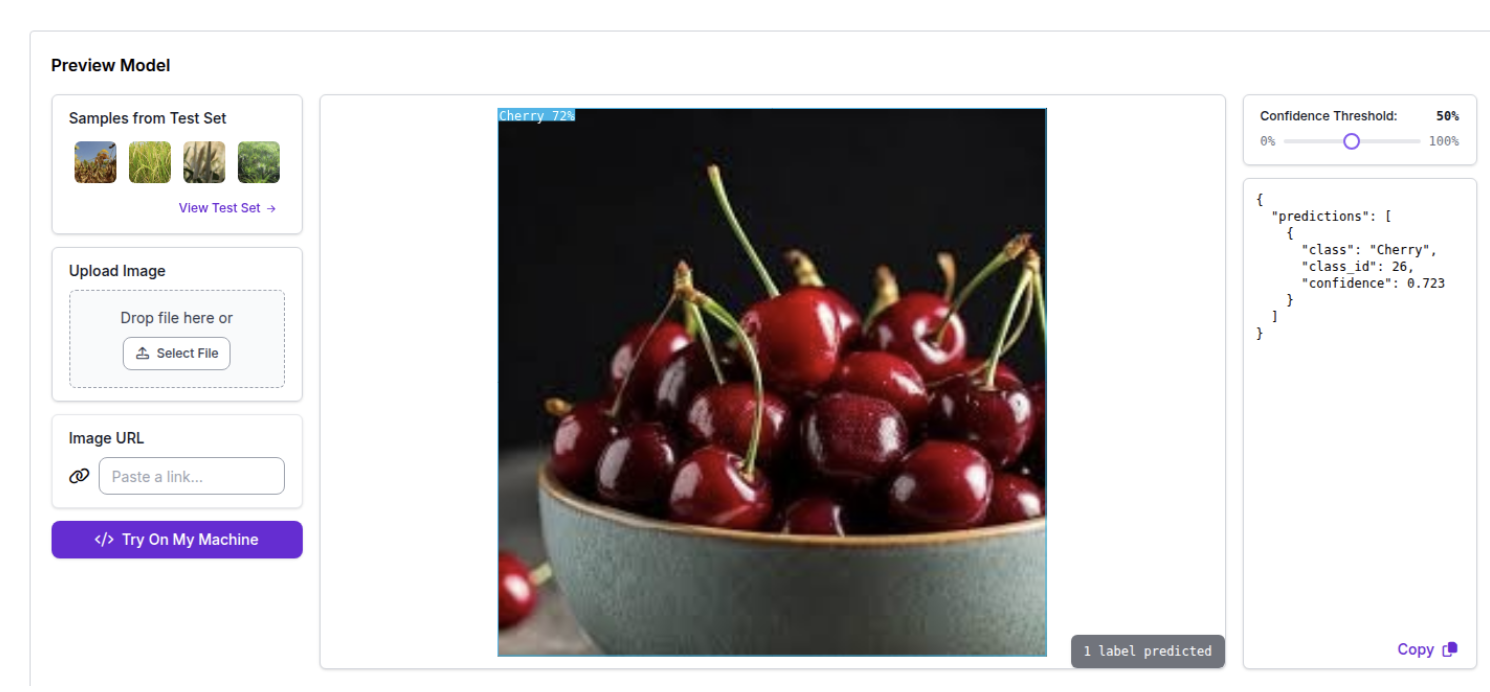
Even though the model has only been trained to detect cherries on trees, it successfully detects cherries in a bowl. This is an example of out-of-distribution generalization.
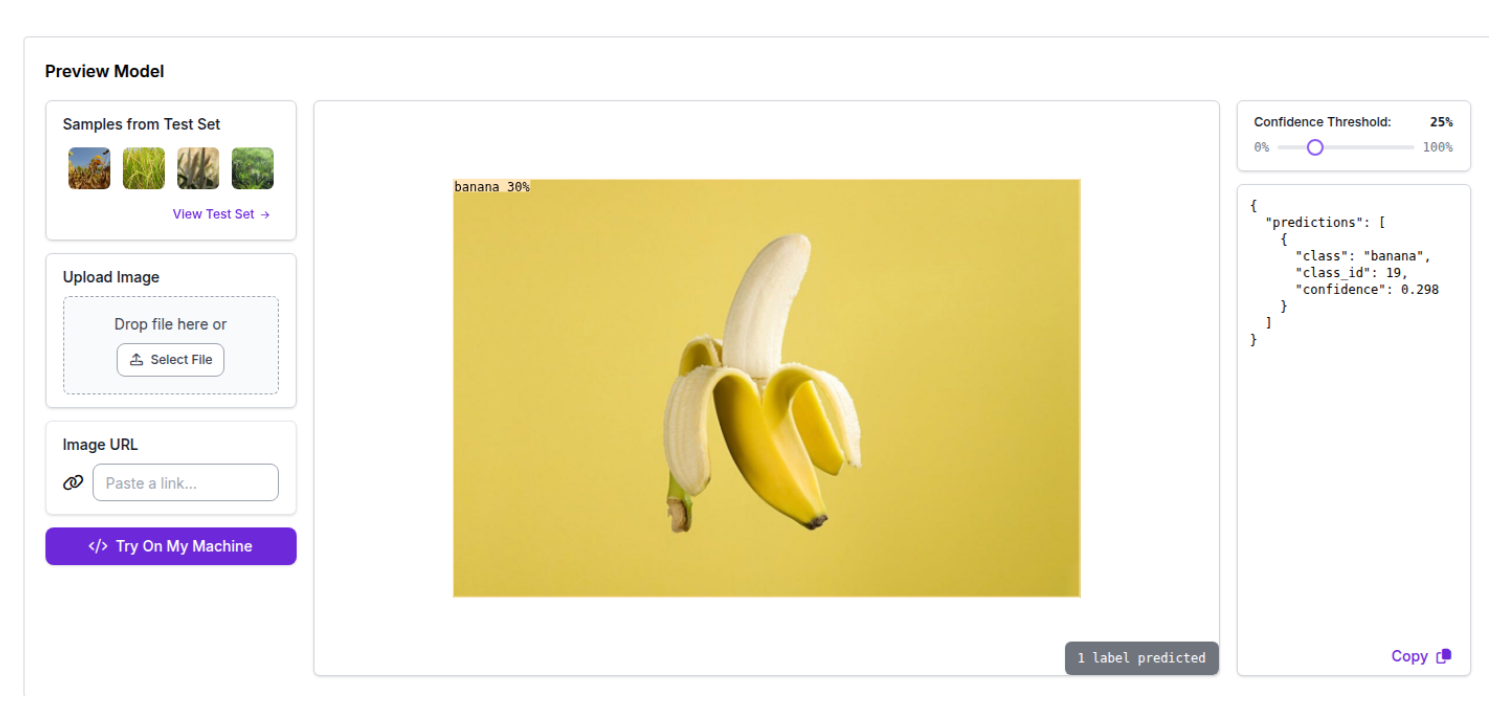
The model was unable to assign a class to the following AI-generated image of a banana. This is likely because it is not familiar with images depicting a single yellow banana, as it was primarily trained on clusters of bananas on trees, often in their green, unripe state.
However, when we decrease the confidence threshold the banana is classified correctly, but with lower confidence. Indicating that the model still exhibits some degree of generalization.
Due to its large-scale pre-training, DINOv3 demonstrates strong few-shot and zero-shot capabilities.
DINOv3 Evaluation Metrics
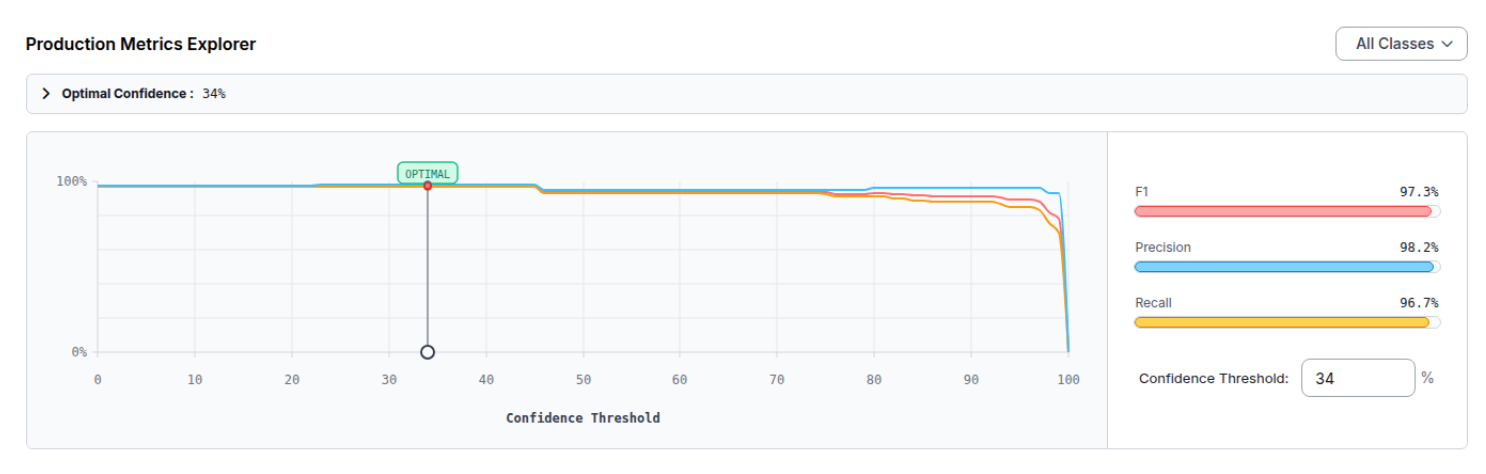
You can click on the model name to view the evaluation results, which include a comprehensive analysis of the classes most frequently misclassified by the model.
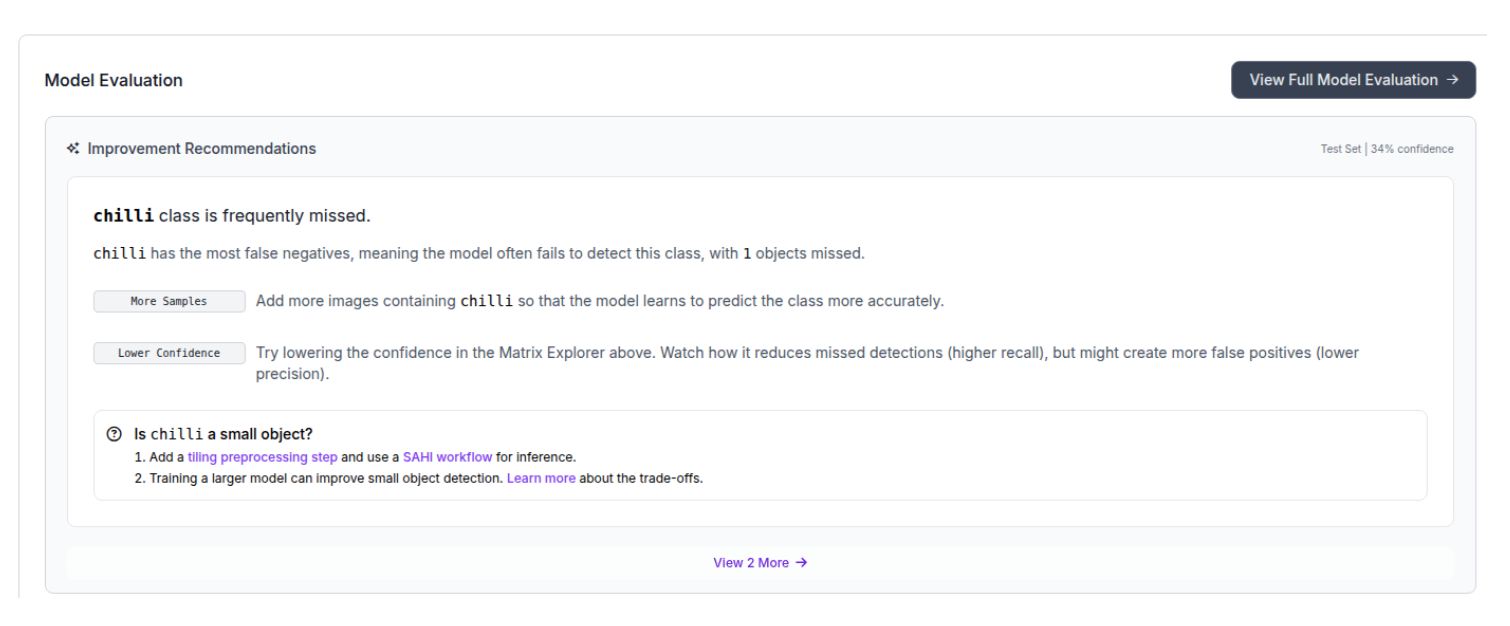
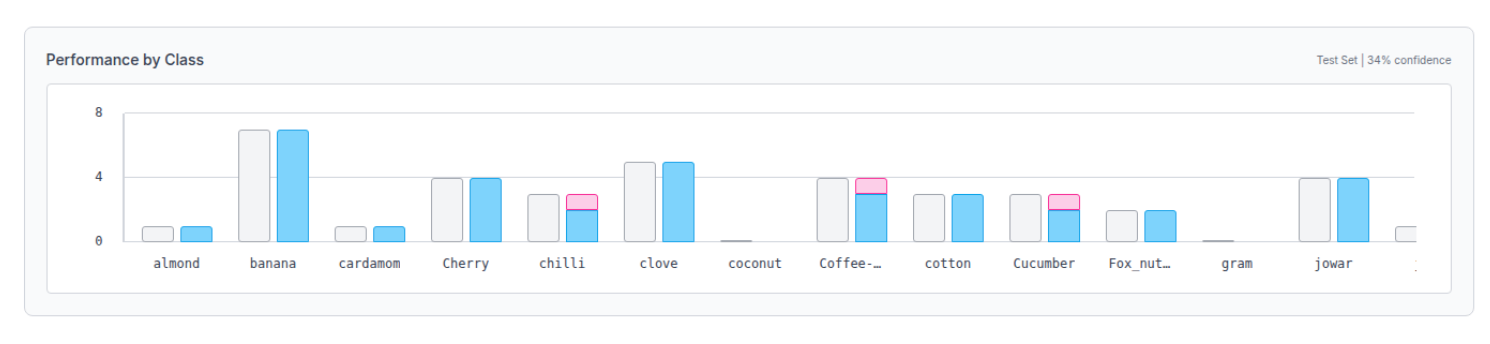
A per-class performance plot is shown.
Additionally, the optimal confidence threshold, along with the precision, recall, and F1 metrics, are reported.
Deploy DINOv3 with Roboflow Workflows
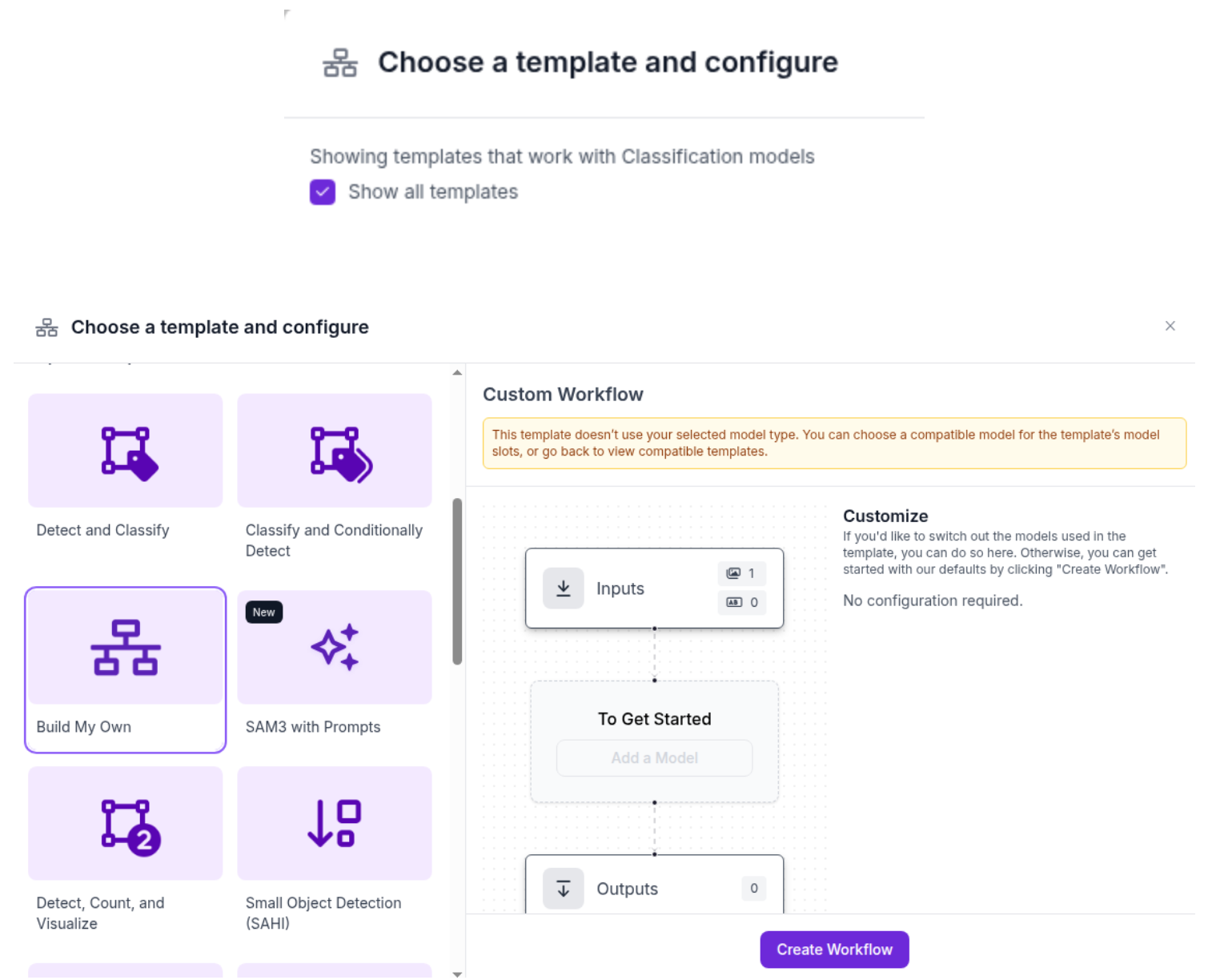
You can click on the rocket icon to deploy your model.

Select the box to reveal all templates available and choose the ‘Build My Own’ template.
You can use the workflow agent to guide you and plan your workflow.
You can find the workflow of our trained model in this link. Fork the workflow, click run and upload your images to test the DINOv3 model.
DINOv3 on Google Colab
You can use Google Colab here to run the workflow.
Install the required Inference SDK Library, which enables you to interact with an Inference Server over HTTP - hosted either by Roboflow or on your own hardware.
!pip install inference-sdk
You can click on Deploy to see and copy the generated code from your workflow into your notebook.
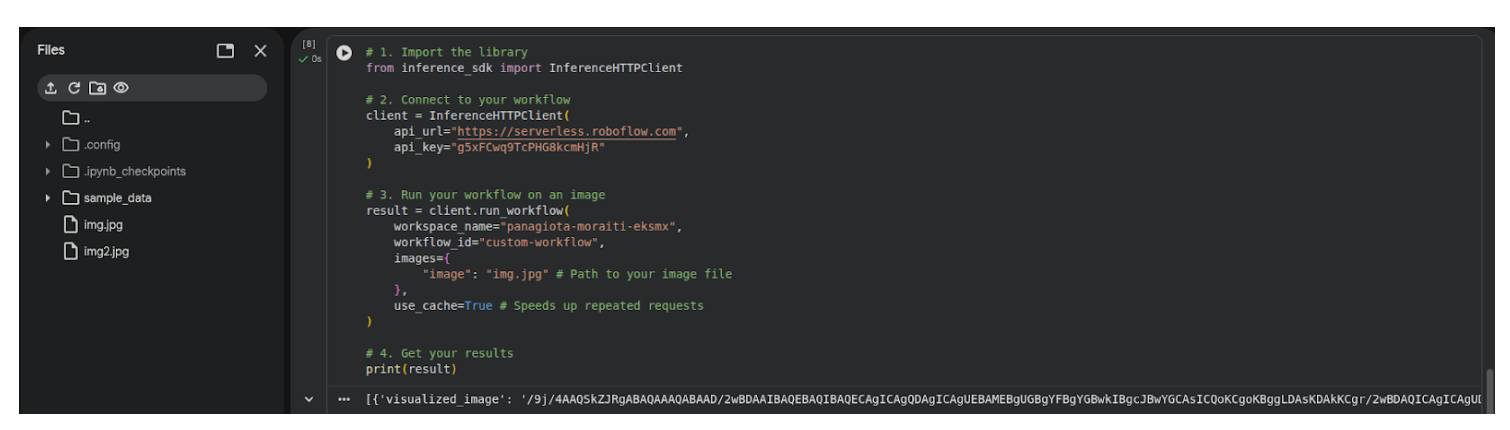
Upload an image to Google Colab files, inside the notebook. Add your image name in the corresponding field.
1. Import libraries.
from inference_sdk import InferenceHTTPClient
import cv2
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
2. Connect to your workflow.
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key=""
)
3. Run your workflow on an image.
result = client.run_workflow(
workspace_name="",
workflow_id="custom-workflow",
images={
"image": "img.jpg"
},
use_cache=True # Speeds up repeated requests
)
4. Extract predicted label and confidence.
output = result[0]["predictions"]
label = output["top"]
confidence = output["confidence"]
text = f"{label} ({confidence:.2%})"
5. Load the original image.
img = np.array(Image.open("img.jpg"))
img_bgr = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
6. Draw label.
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1.5
thickness = 4
color = (255, 255, 255)
pad = 10
(tw, th), baseline = cv2.getTextSize(text, font, font_scale, thickness)
# Background rectangle for readability
cv2.rectangle(img_bgr, (pad, pad), (pad + tw + 10, pad + th + baseline + 10), (0, 0, 255), -1)
# Text on top
cv2.putText(img_bgr, text, (pad + 5, pad + th + 5), font, font_scale, color, thickness)
7. Show the result.
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(8, 6))
plt.imshow(img_rgb)
plt.axis("off")
plt.title(text)
plt.show()
The loaded images are displayed in the lower-left area and the result is printed after the current cell.
DINOv3 Conclusion
DINOv3 is a powerful model with great capabilities across many computer vision tasks. Its general purpose feature representations enable it to generalize across domains and input resolutions, making it well-suited for both industrial applications and academic benchmarks with no or limited dataset-specific fine-tuning.
State-of-the-art models in several computer vision tasks utilize DINO as a backbone, especially DINOv2. These include DA (Depth Anything), RF-DETR (Roboflow Detection Transformer) and VGGT (Visual Geometry Grounded Transformer).
VGGT is a 3D scene understanding model that leverages DINOv2 features to achieve state-of-the-art results in multiple 3D computer vision tasks, such as camera parameter estimation, multi-view depth estimation, dense point cloud reconstruction and 3D point tracking.
Depth Anything is a monocular depth estimation model that leverages DINOv2 features for strong zero-shot generalization across diverse scenes. Depth Anything V3 extends the series by predicting spatially consistent geometry from an arbitrary number of visual inputs, with or without known camera poses, while retaining a vanilla DINOv2 encoder as its backbone. This model sets a new state-of-the-art across camera pose estimation, any-view geometry, visual rendering and monocular depth estimation, outperforming all previous models.
RF-DETR is a real-time object detection model that leverages a DINOv2 backbone to achieve state-of-the-art results in real-time object detection, delivering competitive accuracy at high inference speeds.
DINOv2 features extend beyond static scene understanding to predicting how a scene evolves over time. This is known as world modeling, which aims to predict future outcomes given control actions. DINO-Foresight and DINO-world both leverage DINOv2 features as a semantic latent space to forecast future scene states, avoiding the computational cost of raw pixel reconstruction. World modeling is particularly useful in autonomous driving and robotics, where anticipating future scene states is critical for safe and efficient decision-making.
The DINO family has proven to be a foundational framework in modern computer vision, with DINOv2's rich semantic representations achieving state-of-the-art results across depth estimation, object detection, 3D scene understanding and world-modeling. Its ability to produce powerful general-purpose features with limited task-specific supervision makes it one of the most impactful frameworks to date. DINOv3 pushes the boundaries even further, delivering state-of-the-art performance across a wide range of vision tasks with minimal fine-tuning.
You can train DINOv3 model for classification on Roboflow today.
Written by Panagiota Moraiti
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Apr 8, 2026). DINOv3: An Advanced Self-Supervised Vision Foundation Model by Meta. Roboflow Blog: https://blog.roboflow.com/train-dinov3/