
Vision-Language-Action (VLA) models combine a camera feed and a natural language instruction into a single system that outputs robot motion, replacing separate perception and control pipelines. This architectural shift lets robots generalize to conditions they were not explicitly trained for, which scripted and classical control systems cannot do. The post explains how VLAs work, where they still fall short (mid-task recovery, on-device inference at scale), and how training data quality, including annotation tooling, dataset diversity, and active learning loops, determines how well a deployed VLA handles real-world variation.
A robot arm is halfway through a pick-and-place task when someone moves the bin two inches to the left. It misses. It tries again. It misses again. The line stops.
That is not a sensor failure or a calibration issue. That is the fundamental problem with how robots have been built: they are trained for exact conditions, and the moment those conditions shift, even slightly, they fall apart. They can see. They can move. What they cannot do is reason about what they are seeing and decide what to do next.
By 2030, nearly 13 million robots will be in circulation globally. Most of them are still built the old way. Vision-Language-Action models are the first serious attempt to change that at the model level. A VLA takes in a camera feed and a language instruction and outputs motion. The reasoning and the acting happen in the same system, not in separate pipelines stitched together. That architectural decision changes what these robots can handle.
It is why warehouses are already testing them, why humanoid robotics companies are building on top of them, and why the fields of surgical robotics and autonomous driving are watching closely. The underlying bet is the same across all of them: a robot that can reason about what it sees will generalize in ways that scripted systems never could.
This article breaks down how VLAs work, what they still get wrong, and where the data powering them makes all the difference.
Quick Background: Where VLAs Come From
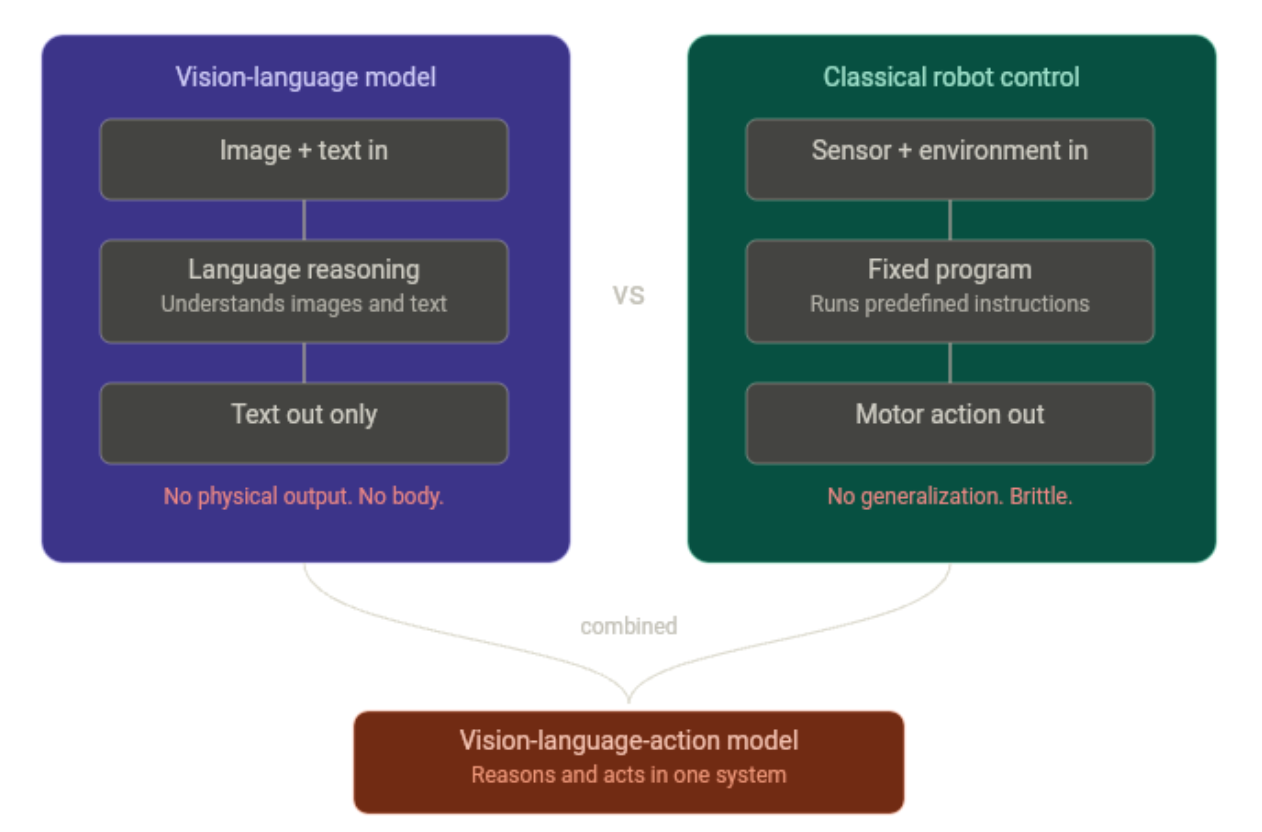
For a long time, two things were true simultaneously, and nobody had fully connected them.
Vision-language models were getting remarkably capable. GPT-4V, Gemini, LLaVA: these models could look at an image, understand what was in it, and reason about it in natural language. You could show one a cluttered desk and ask what was missing, and it would give you a sensible answer. What it could not do was reach out and move anything:
- The reasoning happened entirely inside the model
- No outputs to motors, no connection to the physical world
- Strong at understanding. Useless at doing.
Classical robot control, on the other hand, had been quietly working for decades. Industrial arms in factories, pick-and-place systems in warehouses: reliable, fast, and precise. But brittle in a specific way. Each system was trained or programmed for one task, in one environment, under one set of conditions. The problems showed up the moment anything changed:
- Shift the lighting, and the performance dropped
- Move an object a few centimeters, and it misses
- Introduce something unseen, and the whole thing collapsed
There was no generalization because there was no understanding. Just pattern matching.
The insight that produced VLAs was straightforward in hindsight. Take the reasoning capacity of a vision-language model and give it a new output modality, not text, but action. Train it end-to-end on robot demonstrations. The first results showed it actually transferred. The model's ability to understand scenes and follow instructions carried over into physical tasks in ways that pure imitation learning never had.
What Is a Vision Language Action Model?
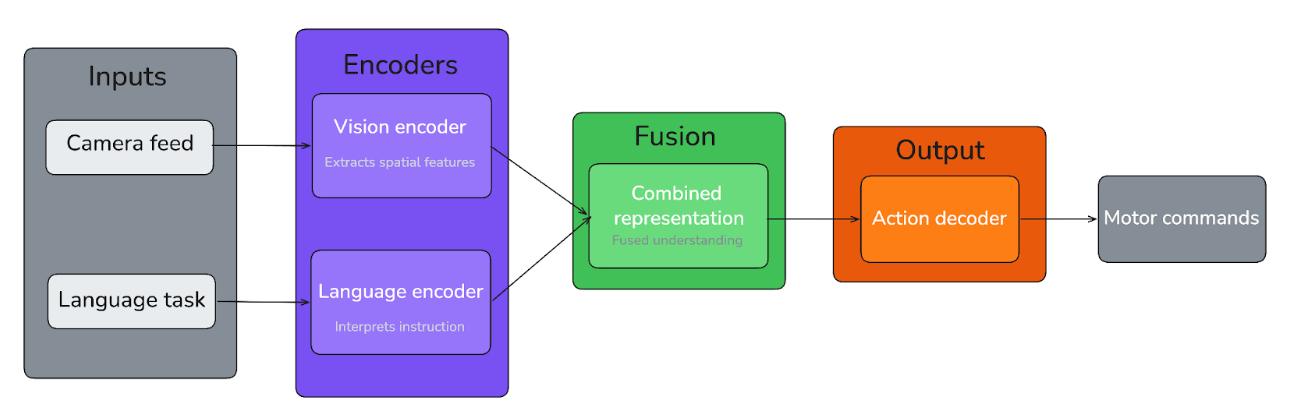
A Vision-Language-Action (VLA) model is a type of artificial intelligence designed to simultaneously process visual information, understand natural language, and output physical or digital actions.
At its core, a VLA does three things in a single forward pass: it sees, it understands, and it acts. A camera feed goes in, a language instruction goes in, and motor commands come out. There is no separate perception module handing off to a planner, handing off to a controller. The whole loop runs inside one model. A VLM is a brain with no body. A VLA gives it one.
The architecture that makes this possible typically involves a vision encoder processing the camera input, a language encoder interpreting the instruction, and an action decoder translating the combined representation into movement. How that action decoder is built is where things start to diverge across different approaches:
- Autoregressive models tokenize actions the same way they tokenize words, predicting movement step by step as a sequence
- Diffusion-based decoders treat action generation as a denoising process, producing smoother and more continuous motion
- Hybrid architectures pair a VLM backbone for high-level reasoning with a separate low-level controller for execution
A few VLA models worth knowing:
- Gemini Robotics is Google DeepMind's VLA built on top of Gemini 2.0, with physical actions added as a new output modality for directly controlling robots. The latest iteration, Gemini Robotics 1.5, thinks before taking action and can explain its reasoning in natural language, making its decisions more transparent.
- SmolVLA is Hugging Face's answer to the accessibility problem: a compact 450M parameter open-source VLA that runs on consumer hardware, pretrained entirely on community-shared datasets. Despite its size, it achieves performance comparable to models that are ten times larger.
- π0 (pi-zero) from Physical Intelligence is one of the most cited open-weights baselines in the field, combining a pretrained VLM backbone with a diffusion action head and trained across a wide range of dexterous manipulation tasks.
The VLA Data Engine
VLA models are only as good as the visual data they are trained on. The architecture can be elegant, the backbone pretrained on billions of images, the action decoder carefully tuned, and the model will still fail in deployment if the training data did not represent the environments it will actually operate in. This is the bottleneck that does not get enough attention.
Collecting robot demonstration data is slow and expensive, and the quality of the annotations applied to that data determines whether the model learns something generalizable or something brittle. Roboflow sits at that upstream decision point.
Annotation Tooling
Annotation quality starts with the right tooling. Roboflow Annotate supports AI-assisted labeling through foundation models like SAM and Grounding DINO, which means teams can label robot environment imagery faster without sacrificing precision.
For VLA pipelines specifically, where image-instruction alignment matters, the ability to annotate at scale without introducing systematic errors is not a convenience; it is a requirement. Inconsistent labels early in the pipeline produce inconsistent behavior late in deployment, and that is a hard problem to fix further down the pipeline.
Dataset Health
Dataset health is not optional. Before a dataset version is used for training, Roboflow's Health Check surfaces class imbalance, annotation density heatmaps, and dimension distribution issues. A warehouse robot trained on a dataset where objects only appear at eye height will struggle the moment a bin ends up on the floor. Catching that in the dataset, rather than after deployment, is exactly the kind of upstream decision that prevents downstream failures.
Building in Diversity
Diversity in training data is what generalization actually looks like. Roboflow supports 16 augmentation types applied at the dataset version level: brightness shifts, rotational variance, occlusion simulation, and noise, all of which directly address the brittleness problem that VLAs are designed to solve. A model trained on augmented, diverse data has seen more of the variation it will encounter in the real world before it ever reaches a physical robot.
Active learning
Active learning closes the loop. Through Roboflow Workflows, teams can route low-confidence predictions from deployed models back into the labeling pipeline automatically. For robotics, where edge cases are frequent and distribution shift is constant, this matters. The model surfaces what it does not understand, and the dataset improves to meet it. Roboflow's HITL guide walks through exactly how to set this up.
The decisions made in Roboflow: what to label, how to augment, and what to fix before training are the decisions that determine what a VLA can and cannot handle once it is running on a physical robot.
Vision Language Action Models Conclusion
VLA models are a real shift in how robots are built. Reasoning and acting in the same system, and generalization that classical control never came close to. Real progress. But not finished progress.
Mid-task recovery is still the hard part. A VLA handles unexpected variation better than anything before it. But when something actually goes wrong - a grasp that slips, an object that shifts mid-pick - getting back on track is still a weak point. Running a model large enough to reason well on the robot itself, in real time, is also still more aspiration than solved problem.
Where things are heading is pretty clear though: smaller models, on-device inference, and open weights. The open source ecosystem is moving faster than most people expected.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Apr 14, 2026). Vision-Language-Action (VLA) Models for Robotics. Roboflow Blog: https://blog.roboflow.com/vision-language-action-models/