
Object detection is the task of identifying both what is in an image and where it is located. YOLO (You Only Look Once) has become one of the most popular model architectures for doing it fast.
As a one-stage detector, YOLO processes the entire image in a single pass, making it ideal for real-time applications. Unlike two-stage models such as Faster R-CNN that prioritize accuracy, YOLO and similar one-stage models are optimized for speed.
The YOLO family has evolved to YOLOv12, each version introducing improvements in accuracy, efficiency, and usability. Roboflow makes it easy to use pre-trained or custom YOLO models by streamlining the entire workflow with drag-and-drop pipelines that scale to production.
Let's explore how YOLO object detection can impact your computer vision projects.
What Is Object Detection?
Imagine you’re looking at a busy street through a window. As a human, you can instantly say, “There’s a car, a bicycle, a person crossing the road, and a traffic light up ahead.” Not only do you recognize what those things are, but you also know where they are in your field of view.
That’s exactly what object detection enables computers to do, recognize and locate multiple objects in a single image. It's like teaching a computer to look at a photo and say, “I see a dog here, a ball there, and a tree over there,” while drawing boxes around each item. This capability powers many real-world technologies: self-driving cars (identifying pedestrians and traffic), surveillance systems (detecting intruders), and smartphone cameras (focusing on faces).
At its core, object detection is the joint task of classification ("what is it?") and localization ("where is it?"). Unlike basic image classification, which only tells you what is present in an image, object detection also tells you where each object is by drawing bounding boxes.
Formally, an object detector predicts a set of tuples:
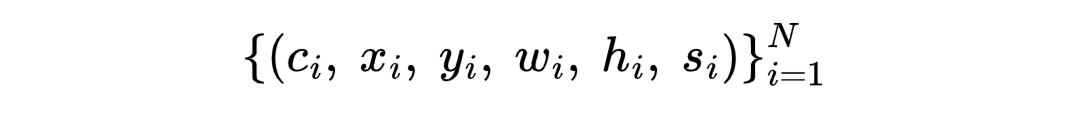
where:
- ci is the class label (e.g., "raccoon" or "car"),
- (xi, yi, wi, hi) defines the position (center x, y) and size (width, height) of the bounding box,
- si is the confidence score for the prediction.
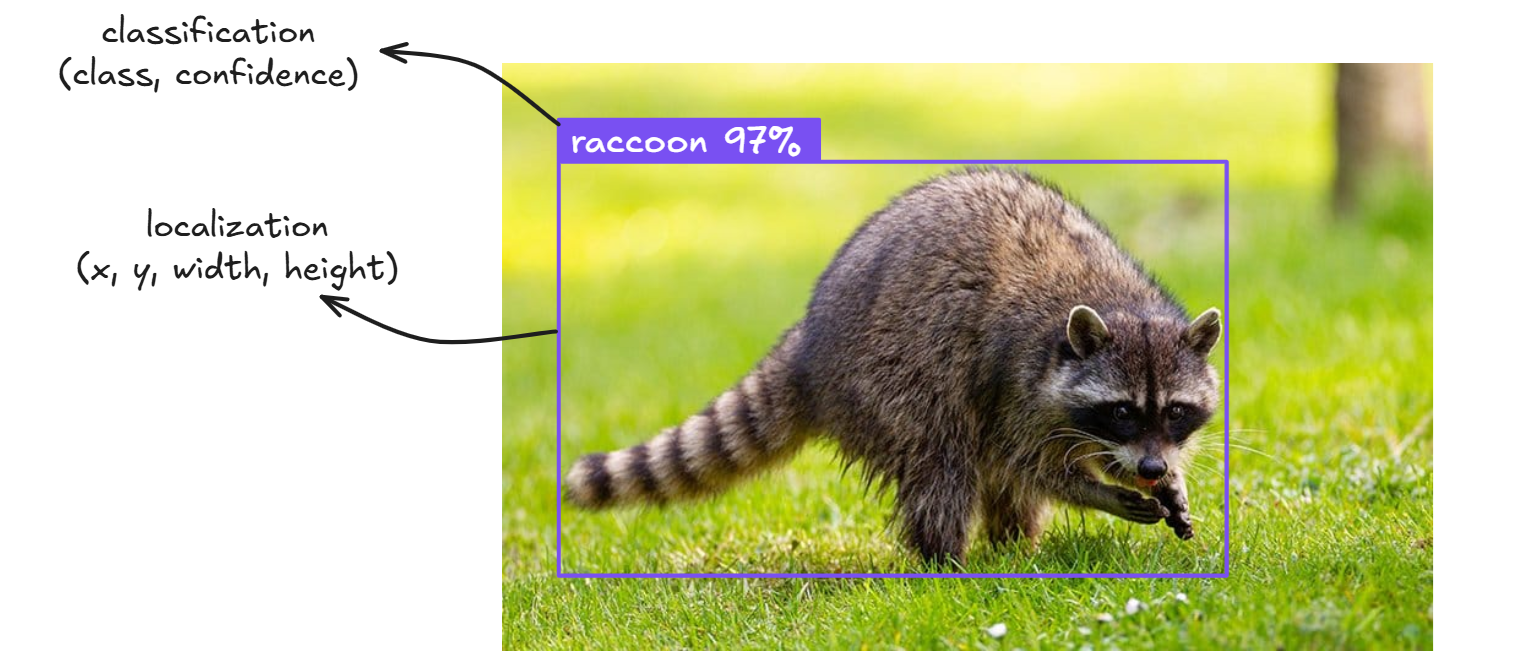
Modern detectors must overcome several challenges, such as:
- Variations in object size (scale).
- Occlusion (when objects overlap).
- Class imbalance (some classes appearing more than others).
- The need for real-time processing over potentially hundreds of frames.
In short, object detection is like the AI version of pointing and saying, "There it is!", only it can do it in milliseconds, across thousands of images, and without ever getting tired.
Types of Object Detection Models
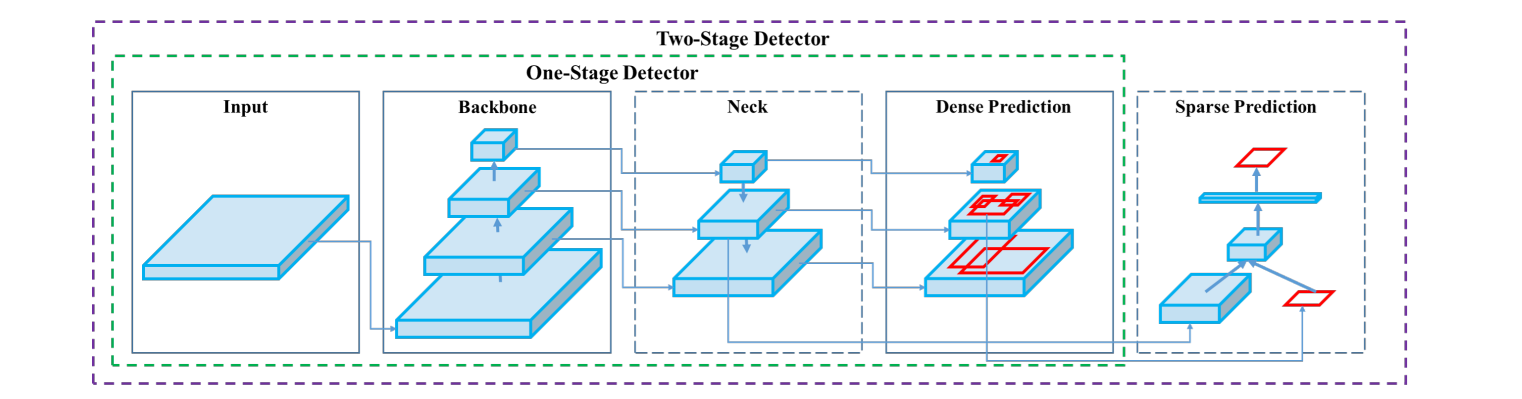
In this section we explore the main types of object detection models. The research paper, YOLOv4: Optimal Speed and Accuracy of Object Detection, describes two main types of object detection models.
The figure below shows the architecture of two types of object detection models, highlighting the difference between one-stage (single shot) and two-stage models. As depicted in figure, both types of models use a backbone for feature extraction and a neck (like FPN) for multi-scale feature enhancement.
One-stage detectors (also called single-shot detectors, e.g., YOLO, SSD) perform dense predictions directly on the feature maps, offering fast inference. Two-stage detectors (also known as region-based detectors, e.g., Faster R-CNN) first generate region proposals and then apply sparse prediction for more accurate results. The diagram clearly separates the shared and distinct components of both types.
Apart from these two types of models, there are other types of object detection models such as zero-shot object detection that we are goinig to discuss here.
One-Stage (Single-Shot) Object Detection
One-Stage object detection models process the whole image once, using a single neural‐network forward pass to predict both the object class and its bounding-box coordinates.
Because they skip any separate proposal or refinement step, they’re very fast and have low memory/CPU requirements and are perfect for real-time use on edge devices, drones, or mobile apps.
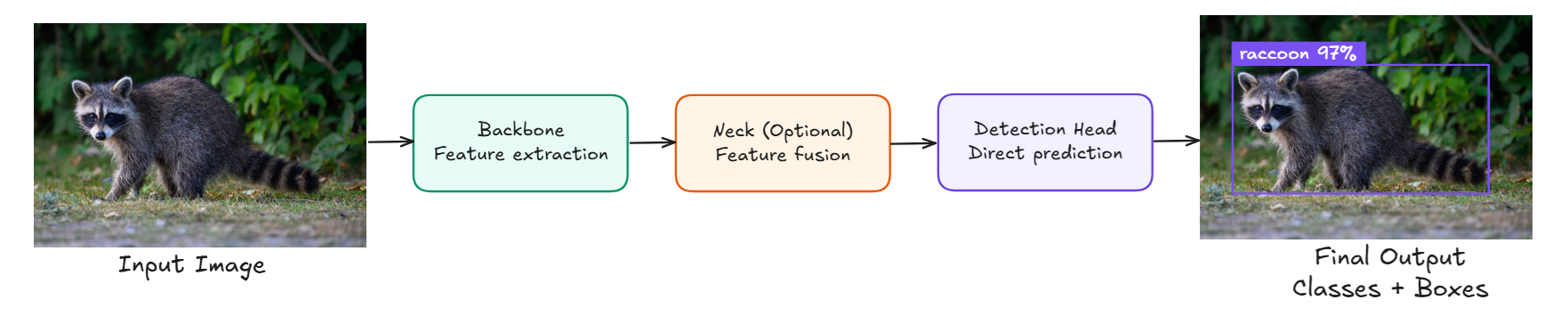
- Strengths: High throughput (30–200 FPS on a GPU), simple end-to-end training, small models for embedded deployment.
- Limitations: Typically miss very small or heavily overlapping objects and may give slightly lower average precision than two-stage systems.
Examples: YOLO (v1–v12), SSD, RetinaNet, EfficientDet.
Two-Stage Object Detection Models
Two-stage object detection models run the image through two passes.
- Region-proposal stage: a first network (e.g., a Region Proposal Network) quickly narrows the search space by generating candidate boxes.
- Refinement/classification stage: a second, heavier network classifies each proposal and fine-tunes its box coordinates.
The extra refinement step boosts accuracy especially for small, cluttered, or partially occluded objects but costs compute and latency.

- Strengths: State-of-the-art accuracy, better small-object recall, flexible training for imbalanced datasets.
- Limitations: Slower, larger memory footprint, harder to deploy on resource-constrained devices.
Examples: R-CNN, Fast R-CNN, Faster R-CNN.
Zero-Shot Object Detection Models
Zero-shot object detection models can find and label objects in the image without training a custom model. Zero-shot detection models take one or more text prompts (e.g., "solar panel", "dog") and return bounding boxes around matching objects in an image, without requiring any additional training on those classes
Typical workflow:
- Train a vision-language backbone (e.g., CLIP, GLIP, Grounding DINO) on “seen” classes that have both images and text captions.
- At inference, supply any text prompt such as “safety helmet,” “red apple,” or “a dog”.
- Model scores every region against that prompt and returns boxes whose image–text similarity is above a threshold.
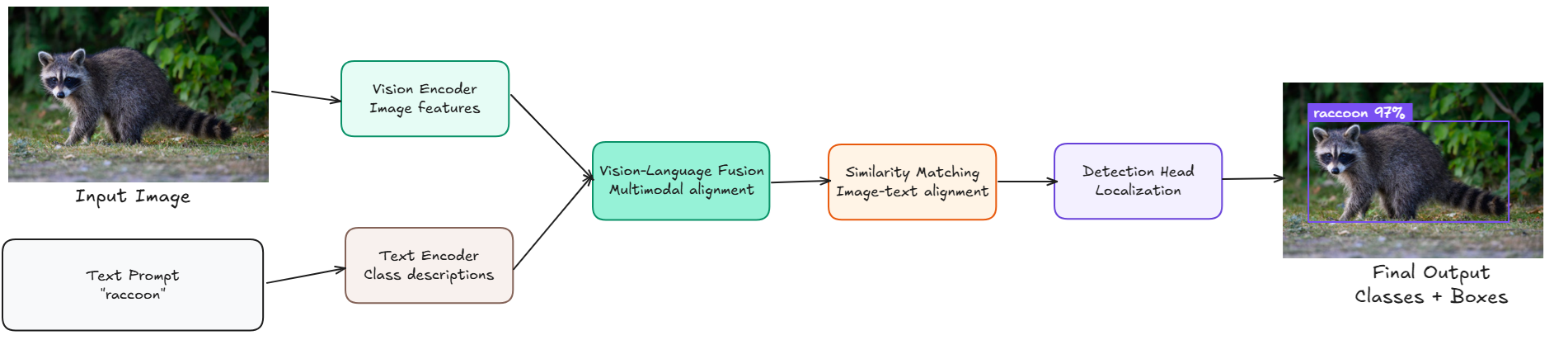
- Strengths: Instantly supports new classes without collecting new boxes; great for rapid prototyping, open-vocabulary search, or long-tail classes.
- Limitations: Lower precision than fully supervised detectors, sensitive to wording of prompts, generally heavier backbones and higher GPU VRAM.
Examples: Grounding DINO, DETIC, OWL-ViT, OWLv2.
What Is the YOLO Architecture?
YOLO is a single-shot (one-stage) object detection architecture that performs object localization and classification in a single forward pass through a single neural network.
Unlike earlier methods like R-CNN or Faster R-CNN, which work in multiple steps (e.g., proposing regions first, then classifying them), YOLO takes a radically different approach by treating object detection as a regression problem, directly mapping pixels to bounding boxes and class probabilities.
Introduced in 2016 by Joseph Redmon, YOLO has since evolved into a family of models, all designed to improve accuracy while maintaining high speed. YOLO’s unified architecture enables it to reason globally about the entire image, leading to fewer false positives and more robust detections, even across different domains.
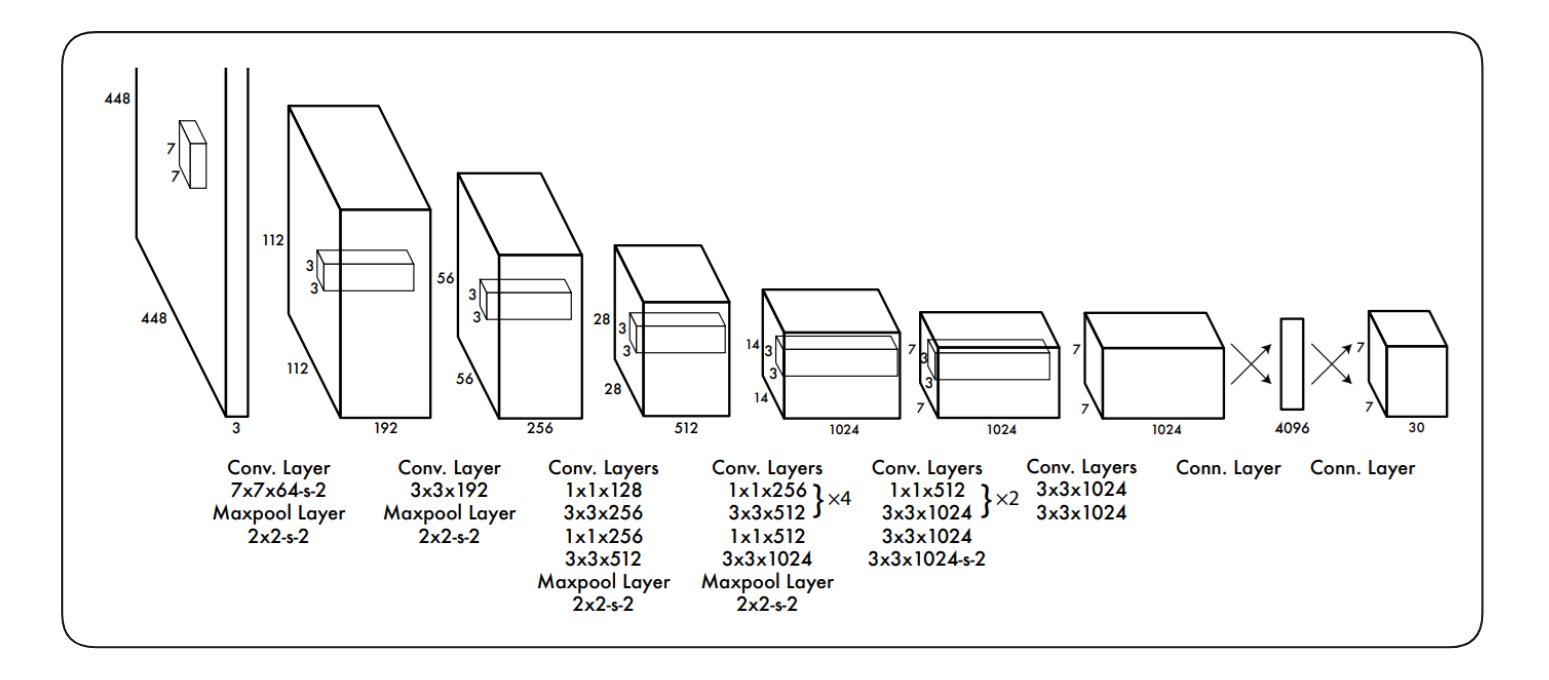
The YOLOv1 architecture consists of 24 convolutional layers followed by 2 fully connected (FC) layers, designed to extract spatial features from the input image and predict bounding boxes and class probabilities in a single forward pass. It starts by taking a 448×448 RGB image as input. This image passes through a series of 24 convolutional layers, which gradually reduce the spatial size while learning features like edges, textures, and object parts. The convolutional layers include alternating 1×1 and 3×3 filters, which help reduce the number of parameters while maintaining learning capacity. There are also max pooling layers after some blocks to downsample the image, shrinking it from 448×448 to 7×7. After all the convolutional layers, the output is flattened and passed through a fully connected (dense) layer with 4096 neurons, which combines the learned spatial features.
Finally, the output layer reshapes the result into a 7×7×30 tensor, where each of the 49 grid cells predicts 2 bounding boxes and 20 class probabilities. Each bounding box prediction contains 5 values (x, y, width, height, confidence). This single network handles the full task of object detection, from understanding the image to locating and identifying objects, all in one pass.
How Does YOLO Work?
YOLO follows a simple but powerful pipeline for detecting multiple objects in an image. The process begins by resizing the input image to 448 × 448 pixels. Next, a single convolutional neural network is applied to the resized image to generate detections. Finally, these detections are filtered by applying a threshold based on the model's confidence scores.

The following are the main processes in YOLO:
- Input Preprocessing: The input image is resized to 448×448 pixels for consistency.
- Grid Division: YOLO divides the image into a 7×7 grid. Each grid cell is responsible for detecting objects whose center falls inside that cell.
- Feature Extraction: A convolutional neural network with 24 convolutional layers followed by 2 fully connected layers is used to extract features from the image.
- Prediction: Each grid cell predicts 2 bounding boxes. Each bounding box includes x, y, width, height, confidence. Each grid cell predicts the class probabilities for 20 different object categories. The final output is a 7×7×30 tensor (7×7 grid × [2 boxes × 5 values + 20 classes]).
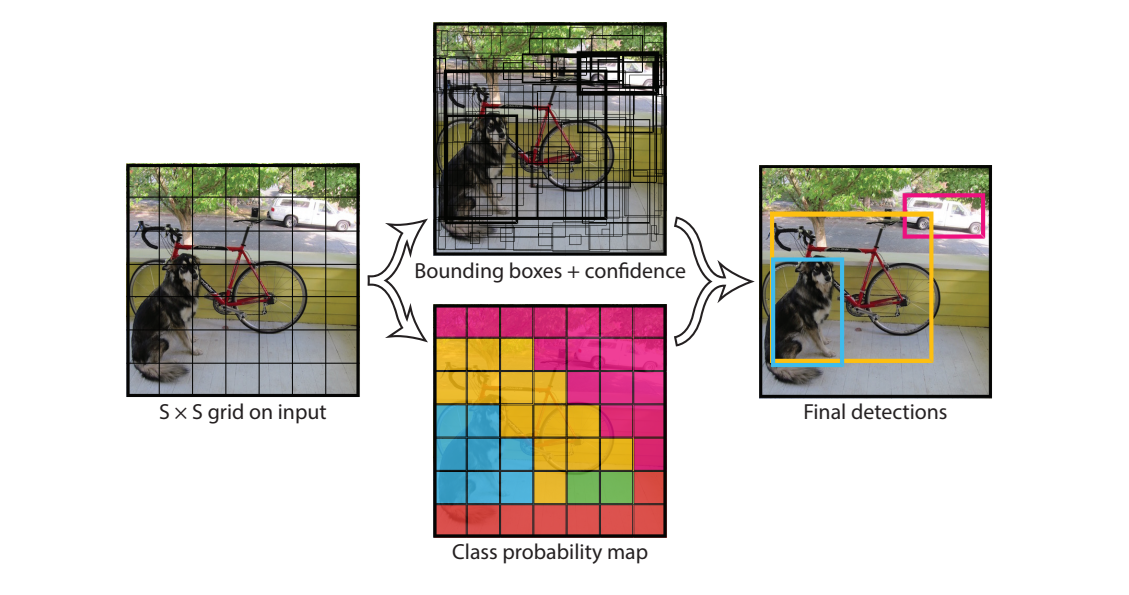
- Post-processing: Class scores are computed by multiplying class probabilities with box confidence. Non-Maximum Suppression (NMS) is used to eliminate overlapping boxes and produce the final detections.
This entire process is done in one single forward pass, which is why YOLO is called a single-shot detector.
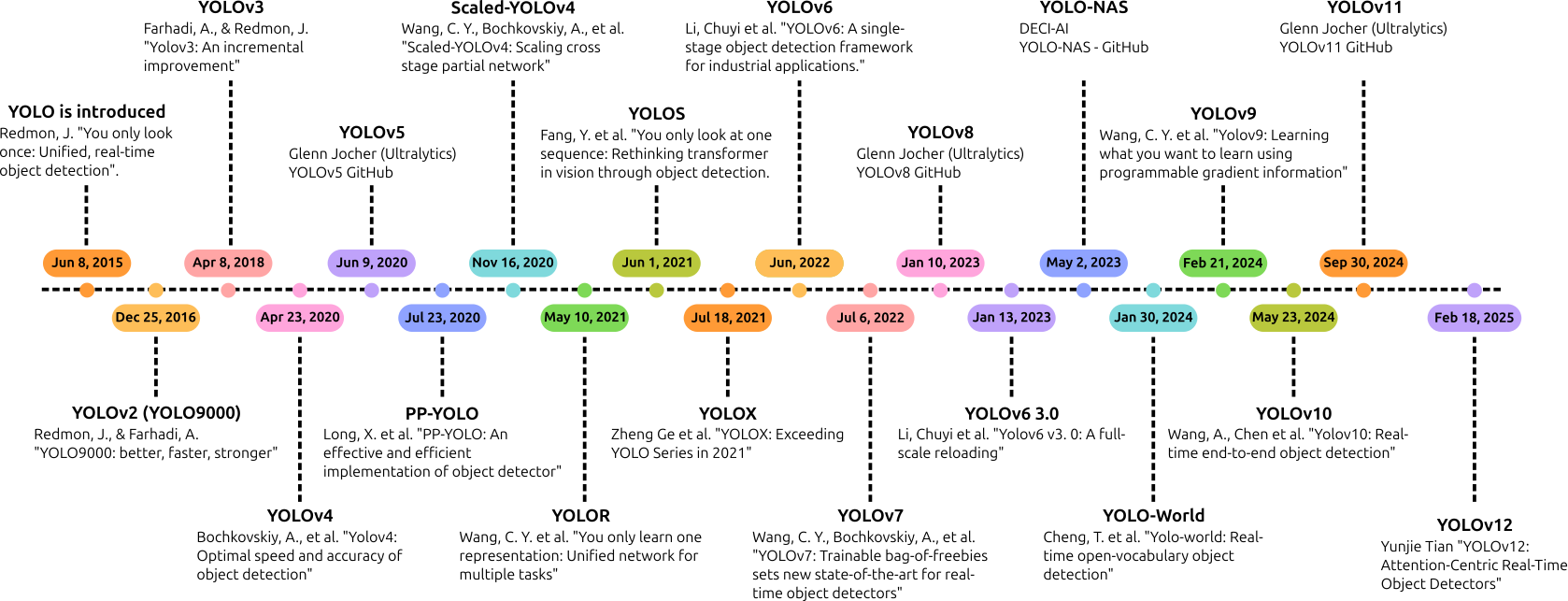
Overview of YOLO Family of Models
Let’s explore how the YOLO family has evolved from v5 through the brand-new v12. Each release has chased the same north star, real-time accuracy on commodity hardware, but has done so with a different mix of architectural tweaks, training tricks, or task expansions.
YOLOv5
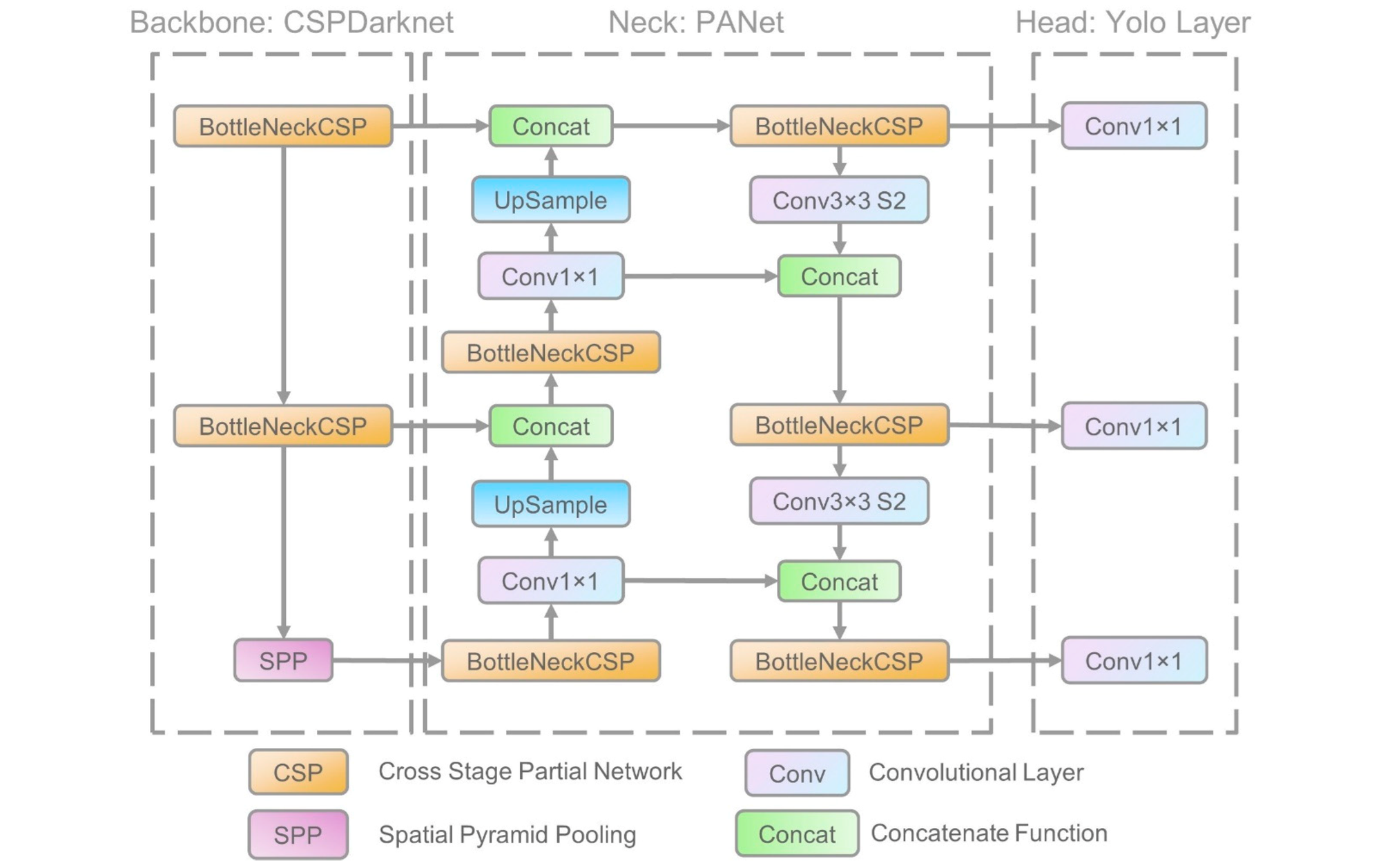
YOLOv5 is a PyTorch-native real-time object detection model, designed for ease of use and rapid deployment. It includes multiple model sizes, supports a full training-inference-export pipeline, and emphasizes efficiency on a broad range of hardware. YOLOv5 is a single-stage object detector that performs fast and accurate detection using three main components:
- Backbone: Uses CSPDarknet to extract rich features from the input image. It combines convolutional layers, residual connections, and Cross Stage Partial (CSP) modules to reduce computation while maintaining accuracy.
- Neck: Combines FPN (Feature Pyramid Network) and PANet (Path Aggregation Network) structures to fuse features from different scales. This helps YOLOv5 detect small, medium, and large objects more effectively.
- Head: Applies anchor-based detection heads at three scales to predict bounding box coordinates (x, y, w, h), objectness score and class probabilities.
Key Features:
- Anchor-free head: Removes dependence on predefined anchors, improving flexibility and detection performance.
- Optimized accuracy-speed balance: Engineered for fast inference without sacrificing mAP, ideal for applications like robotics, autonomous vehicles, and video analytics.
- Model variants: Provides a suite of pretrained variants (n/s/m/l/x versions), each designed for different resolution, speed, and accuracy requirements.
- Full-stack workflow: Seamlessly handles training, validation, inference, and export through unified Python API and CLI commands.
YOLOv6
YOLOv6 is a production-focused object detection model originating from Meituan. It balances high-speed inference with state-of-the-art accuracy, making it ideal for real-time applications in both server and edge environments.
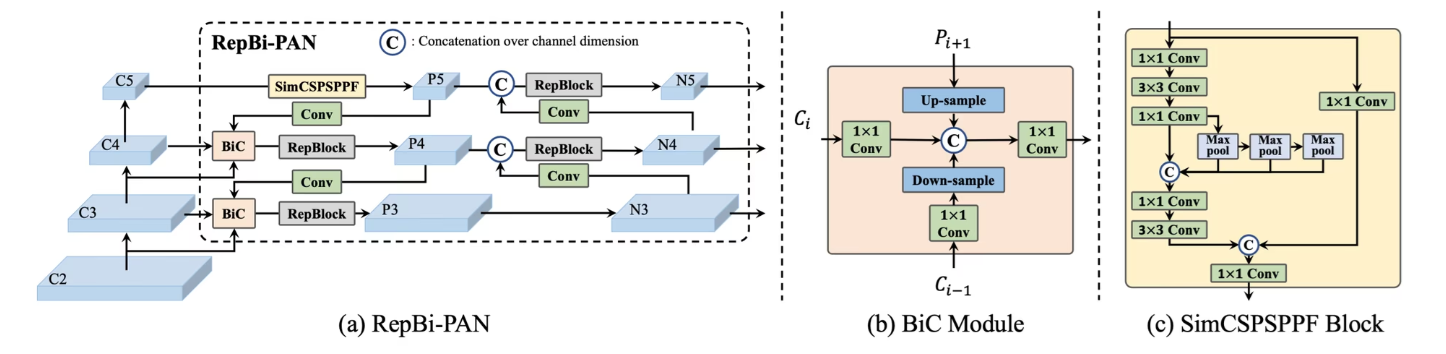
YOLOv6 Network Design includes three main parts: Backbone, Neck, and Head.
- Backbone: YOLOv6 uses RepBlocks (from RepVGG) for smaller models due to their strong feature representation and efficient inference. For larger models, it uses a revised CSPStackRep Block, which combines the benefits of Cross Stage Partial connections and RepBlocks for better parameter efficiency and scalability.
- Neck: The architecture adopts the PANet-style topology (from YOLOv4/v5) to fuse features across scales. YOLOv6 enhances this structure into RepPAN by inserting RepBlocks or CSPStackRep blocks, improving multi-scale feature fusion.
- Head: YOLOv6 introduces a simplified and optimized Efficient Decoupled Head that separates classification and regression tasks for better accuracy and faster inference, while keeping the architecture lightweight.
YOLOv6 improves accuracy and efficiency by combining RepVGG-style blocks, PANet-like necks, and decoupled heads, all while considering inference cost.
Key Features:
- Bi-directional Concatenation (BiC) module: Enhances localization by merging feature maps in both directions within the neck boosts performance with minimal impact on speed.
- Anchor-Aided Training (AAT): Leverages anchor-based training benefits while maintaining anchor-free inference efficiency.
- Improved backbone & neck designs: Adds an extra stage to both backbone and neck, delivering cutting-edge accuracy on COCO.
- Self-distillation: Employs a teacher-style auxiliary regression during training to enhance smaller models, then removes it at inference to preserve.
- Flexible operational modes: Fully supports inference, training, validation, and export workflows backed by PyTorch API and CLI.
YOLOv7
YOLOv7 is a state-of-the-art real-time object detection model that achieves an exceptional speed-accuracy balance, surpassing all previously known real-time detectors in the 5–160 FPS range. It holds the highest reported COCO AP (56.8%) at ≥30 FPS on a V100 GPU, while being trained from scratch without pre-trained weights.
YOLOv7 uses an Extended Efficient Layer Aggregation Network (E‑ELAN) backbone that boosts feature diversity via grouped convolutions, channel expansion, shuffle, and merge operations while preserving gradient paths.
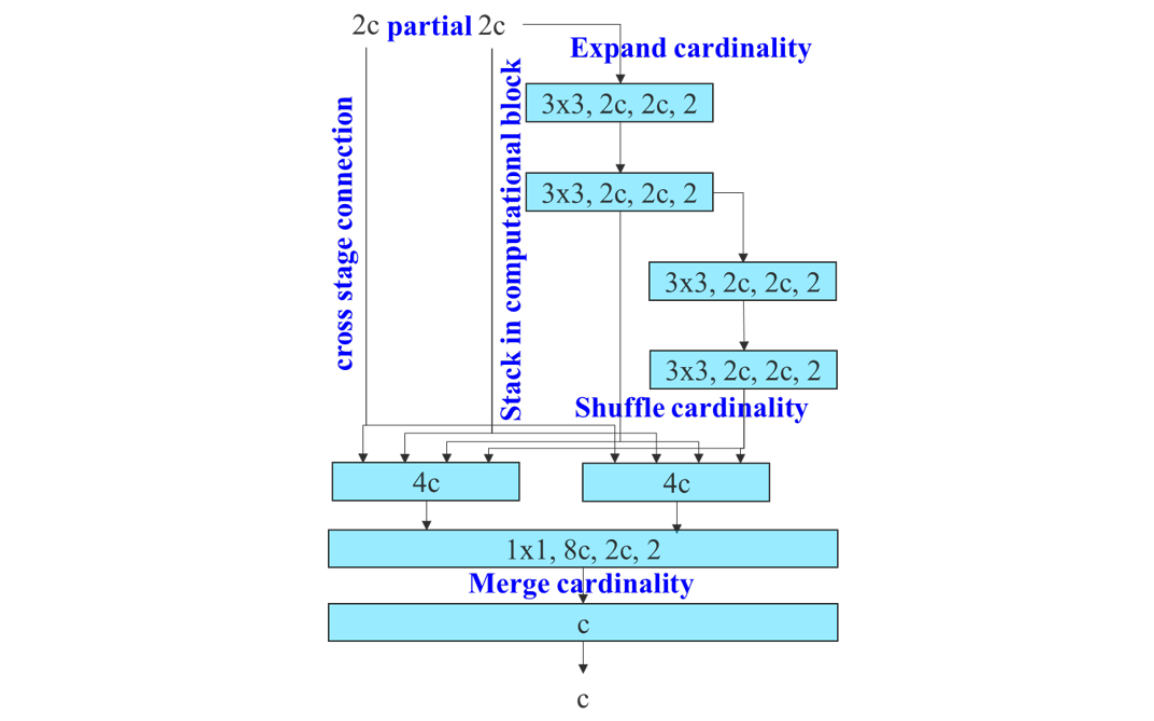
It uses compound model scaling to adjust both depth and width harmoniously in concatenation-based blocks and ensure efficient parameter utilization.
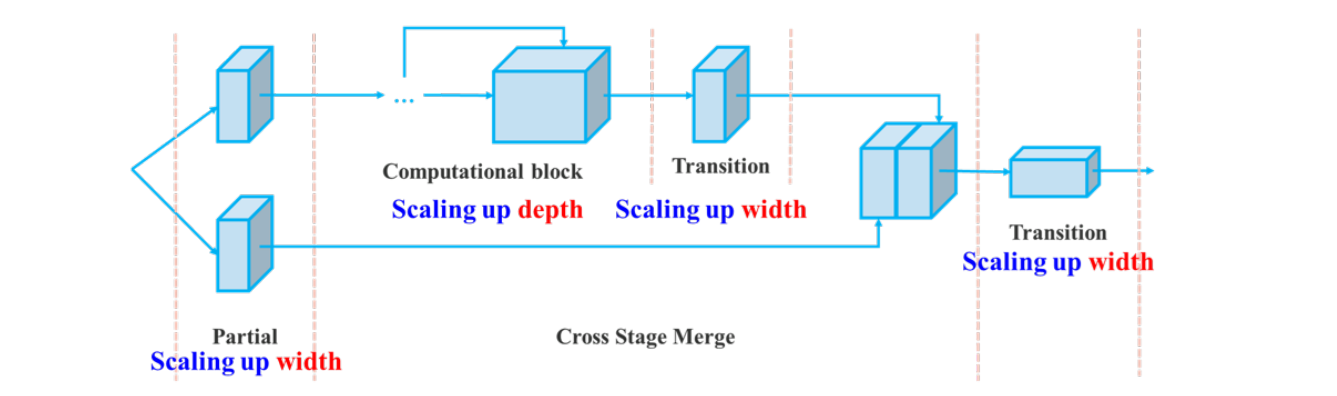
YOLOv7 integrates a “trainable bag‑of‑freebies” strategy including re‑parameterized convolutions and a coarse‑to‑fine label assignment mechanism to improve accuracy during training without increasing inference cost. These innovations enable YOLOv7 to achieve state‑of‑the‑art real‑time performance on COCO benchmarks.
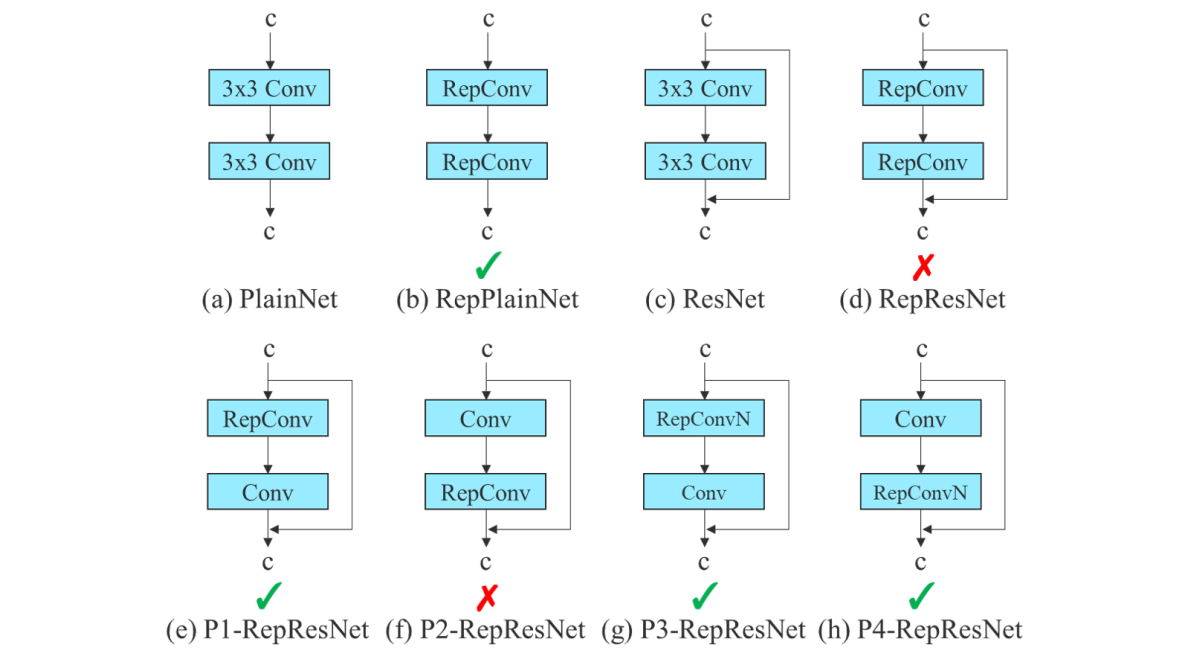
Key Features:
- Model Re-parameterization: Implements training-time modules that can be fused at inference for enhanced performance without runtime cost.
- Dynamic Label Assignment: Introduces a coarse-to-fine lead-guided method for assigning targets during training across multiple output branches.
- Extended & Compound Scaling: Efficiently scales network depth, width, and resolution, enabling variants from tiny to large while maximizing utilization of parameters and FLOPs.
- Efficiency: Focuses on training-time optimizations without adding inference cost to reduce parameter count (40%), computation (50%), and improve both speed and accuracy.
YOLOv8
YOLOv8 is a next-generation real-time computer vision model designed for seamless deployment across multiple tasks including detection, segmentation, classification, pose estimation, and oriented bounding boxes while maintaining a cutting-edge accuracy-speed balance.
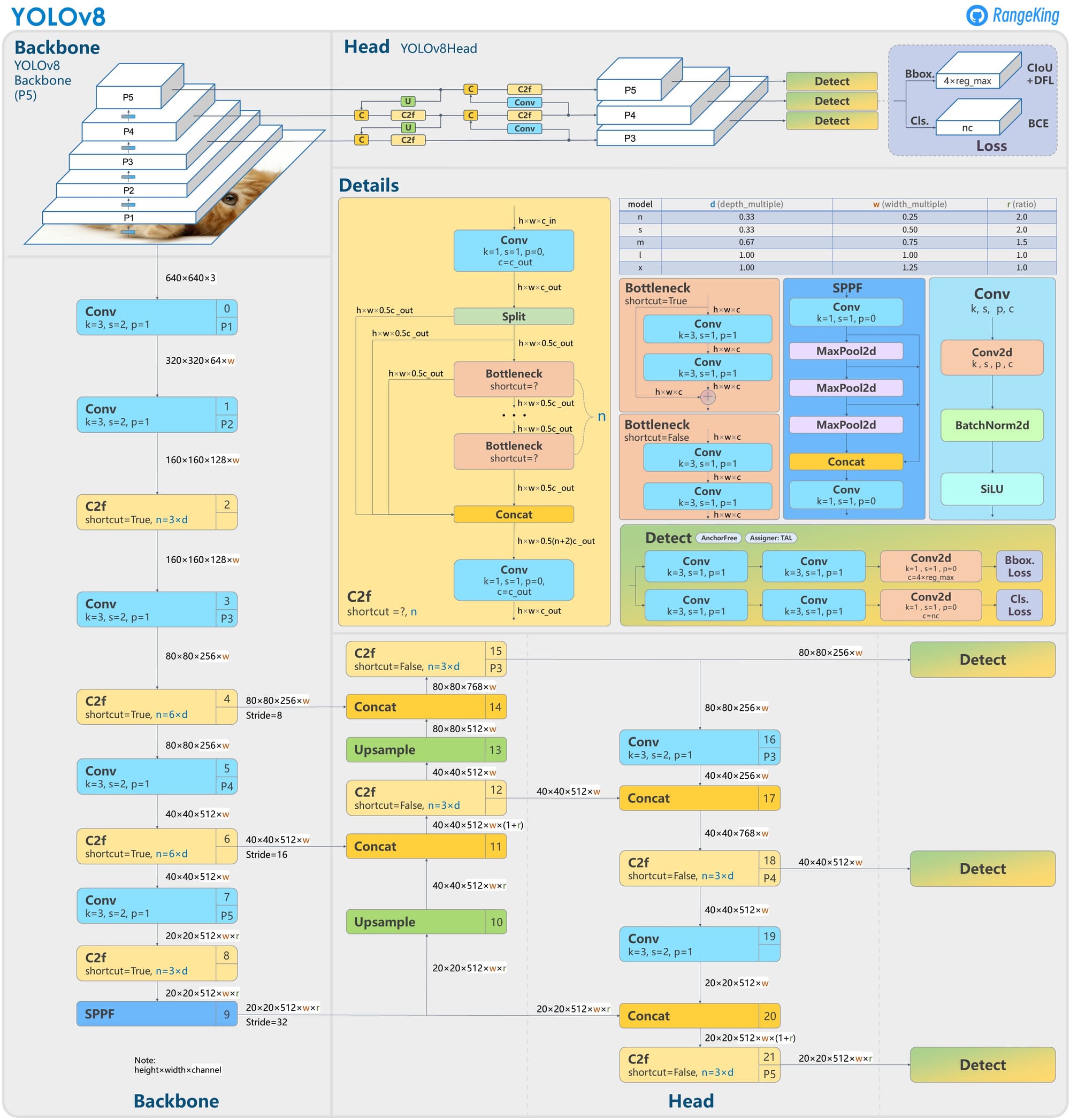
Key Features:
- Advanced backbone & neck architectures: Utilizes modern backbone and neck designs, enhancing multi-scale feature representation to boost detection performance.
- Anchor-free split head: An anchor-free detection head optimized for accuracy and speed benefits from eliminating predefined anchor boxes.
- Optimized accuracy-speed tradeoff: Designed to operate efficiently in real time while delivering high mAP across tasks, ideal for deployment on diverse hardware.
- Multi-task model family: Offers specialized pretrained variants such as yolov8n/s/m/l/x for detection, segmentation, keypoints (pose), oriented detection, and classification with uniform support for training, validation, inference, and export workflows.
YOLOv9
YOLOv9 is a next-gen real-time object detection model that advances both efficiency and accuracy. It introduces two core innovations, Programmable Gradient Information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN) which are designed to preserve critical information through the network and improve performance across all model sizes.
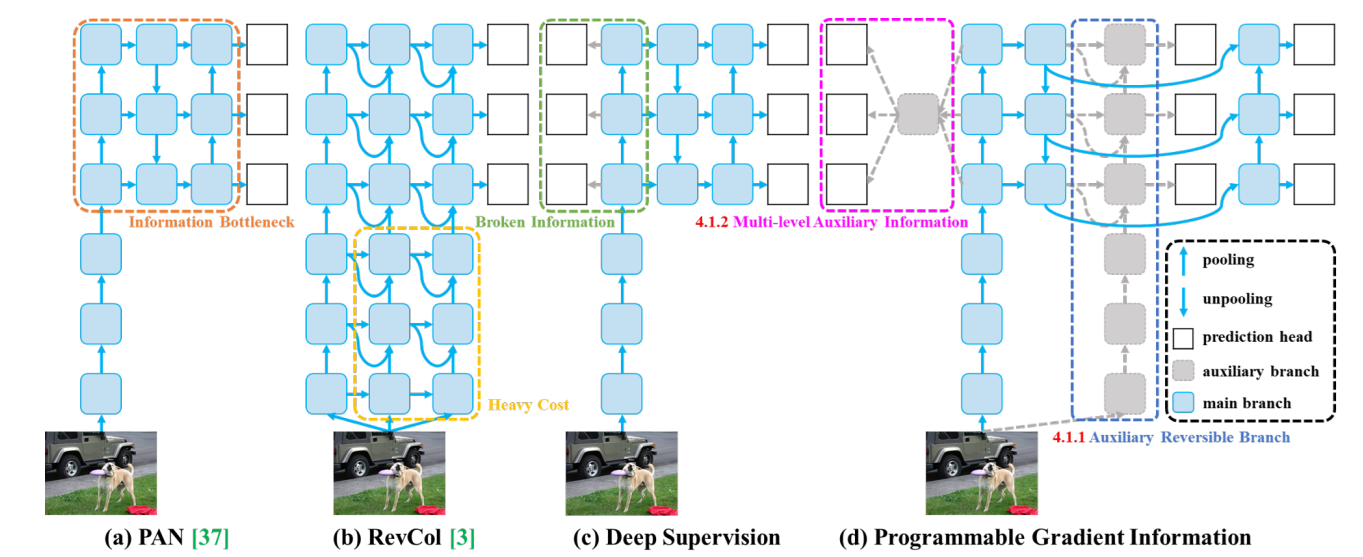
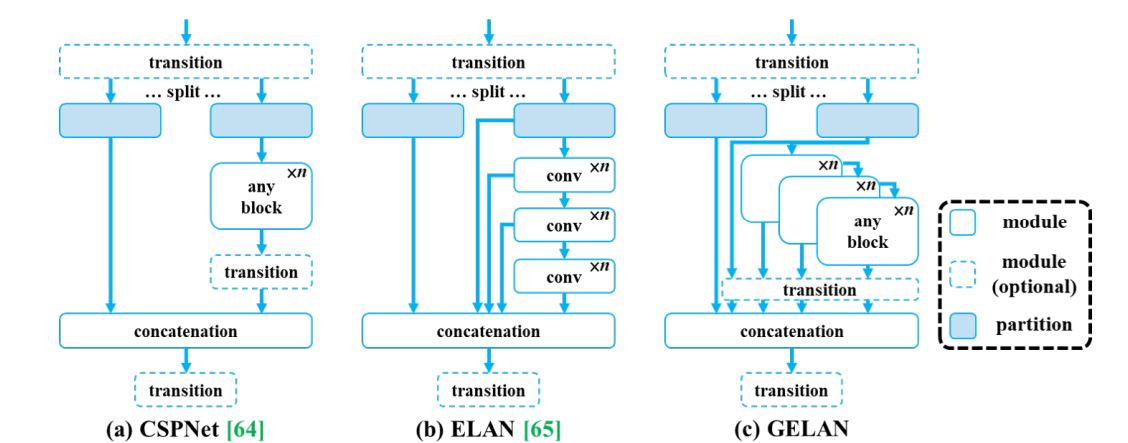
Key Features:
- Programmable Gradient Information (PGI): PGI is YOLOv9's solution to the common problem of information degradation in deep networks. By creating pathways that preserve essential data across layers, PGI improves gradient quality and enhances overall model performance for object detection tasks.
- Generalized Efficient Layer Aggregation Network (GELAN): GELAN serves as YOLOv9's intelligent backbone architecture that gets more work done with fewer resources. By smartly organizing and connecting network layers, GELAN enables the model to adapt to various use cases while delivering consistently fast and accurate results.
- Variants for Every Use Case: Offers five model sizes such as yolov9t, yolov9s, yolov9m, yolov9c, and yolov9e balancing parameters, FLOPs, and mAP to suit diverse needs, from mobile to server-grade tasks.
- Segmentation Variants: yolov9c-seg and yolov9e-seg models extend capabilities to instance segmentation, maintaining state-of-the-art accuracy.
YOLOv10
YOLOv10 is a groundbreaking real-time, end-to-end object detection model developed by Tsinghua University. It eliminates Non-Maximum Suppression (NMS) at inference by introducing dual assignment during training, enabling a cleaner architecture and faster deployment.
YOLOv10 enhances previous YOLO designs with four core components:
- Enhanced CSPNet Backbone: Optimized feature extraction with improved gradient flow and reduced computational overhead
- PAN-based Neck: Aggregates and fuses multiscale features from different network levels
- Dual-Head Design:
- One-to-Many Head (training): Generates multiple predictions per object for richer learning signals
- One-to-One Head (inference): Produces single optimal predictions, eliminating NMS requirements for faster processing
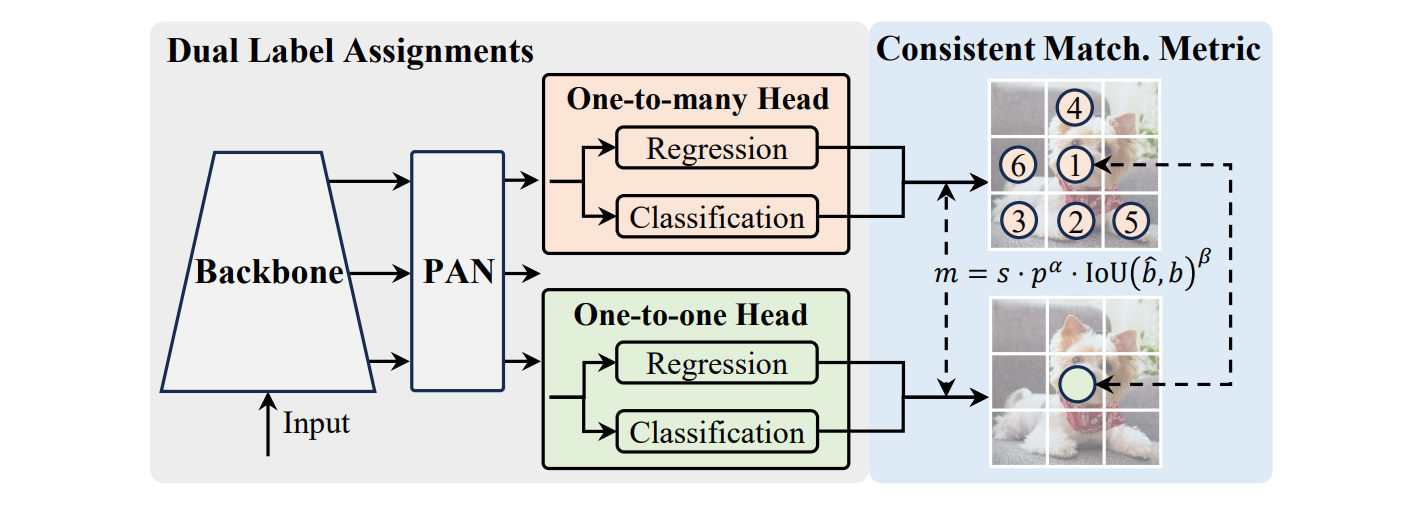
Key Features:
- Faster Processing: Removes the slow NMS (Non-Maximum Suppression) step by using a smart dual-head system, making detection much quicker.
- Smart Design Optimization: Every component is carefully tuned for the best balance of speed and accuracy, including:
- Lighter prediction heads
- Efficient downsampling methods
- Streamlined network blocks
- Better Performance: Uses larger convolution filters and selective attention mechanisms to see objects more clearly while keeping computational costs lowScalable Model Variants: Offers a range of models YOLOv10n, YOLOv10s, YOLOv10m, YOLOv10b, YOLOv10l, and YOLOv10x to suit deployments from low-power devices to high-throughput servers.
- Broad Export Support: Compatible with TorchScript, ONNX, OpenVINO, TensorRT, CoreML, TF SavedModel, TF Lite, Edge TPU, and TF.js formats.
YOLOv11
YOLOv11 is the latest generation, optimized for versatile real-time computer vision applications. It delivers best-in-class accuracy and efficiency, using significantly fewer parameters than its predecessors while supporting an expanded range of tasks.
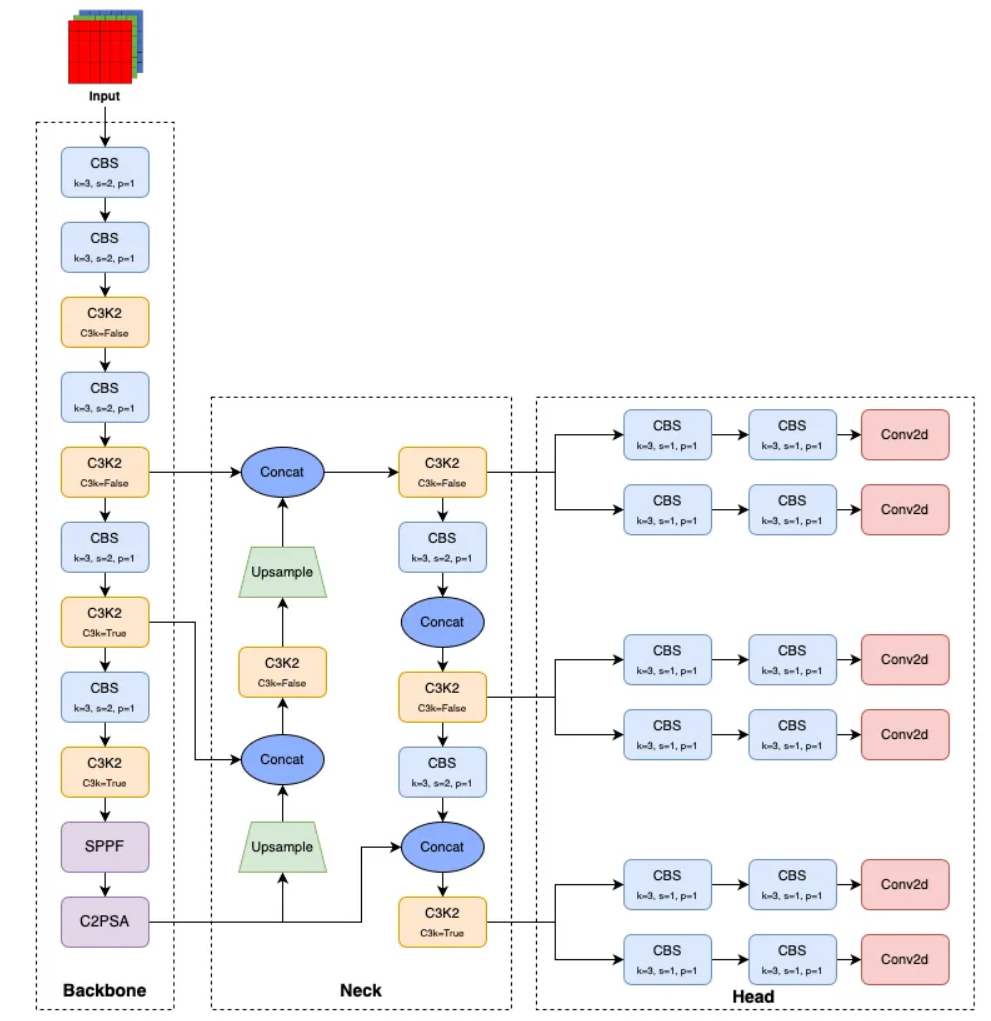
Key Features:
- Enhanced Backbone & Neck: Refined architectural components improve feature extraction and fusion, enabling more precise detection and generalization across tasks.
- Efficiency-First Design: Architectural and training optimizations make YOLOv11 faster and smaller, e.g., the yolo11m variant achieves higher COCO mAP than yolov8m using 22% fewer parameters.
- Lightweight and Accurate: Maintains a strong balance. Smaller models like yolo11n/s are agile for edge deployment, while yolo11l/x deliver high accuracy for server-side or cloud applications.
- Multi-Task Versatility: It offers unified support different vision tasks such as object detection, instance segmentation, image classification, pose estimation, oriented bounding boxes (OBB).
- Full Development Workflow: Each variant (n/s/m/l/x) fully supports all modes i.e. training, validation, inference, and export (including formats like ONNX, TensorRT, etc.)
YOLOv12: Attention-Centric Object Detection
YOLOv12 introduces a cutting-edge, attention-centric architecture that departs from purely convolutional designs while maintaining real-time speeds. It achieves state-of-the-art detection accuracy through efficient attention innovations and optimized feature aggregation.
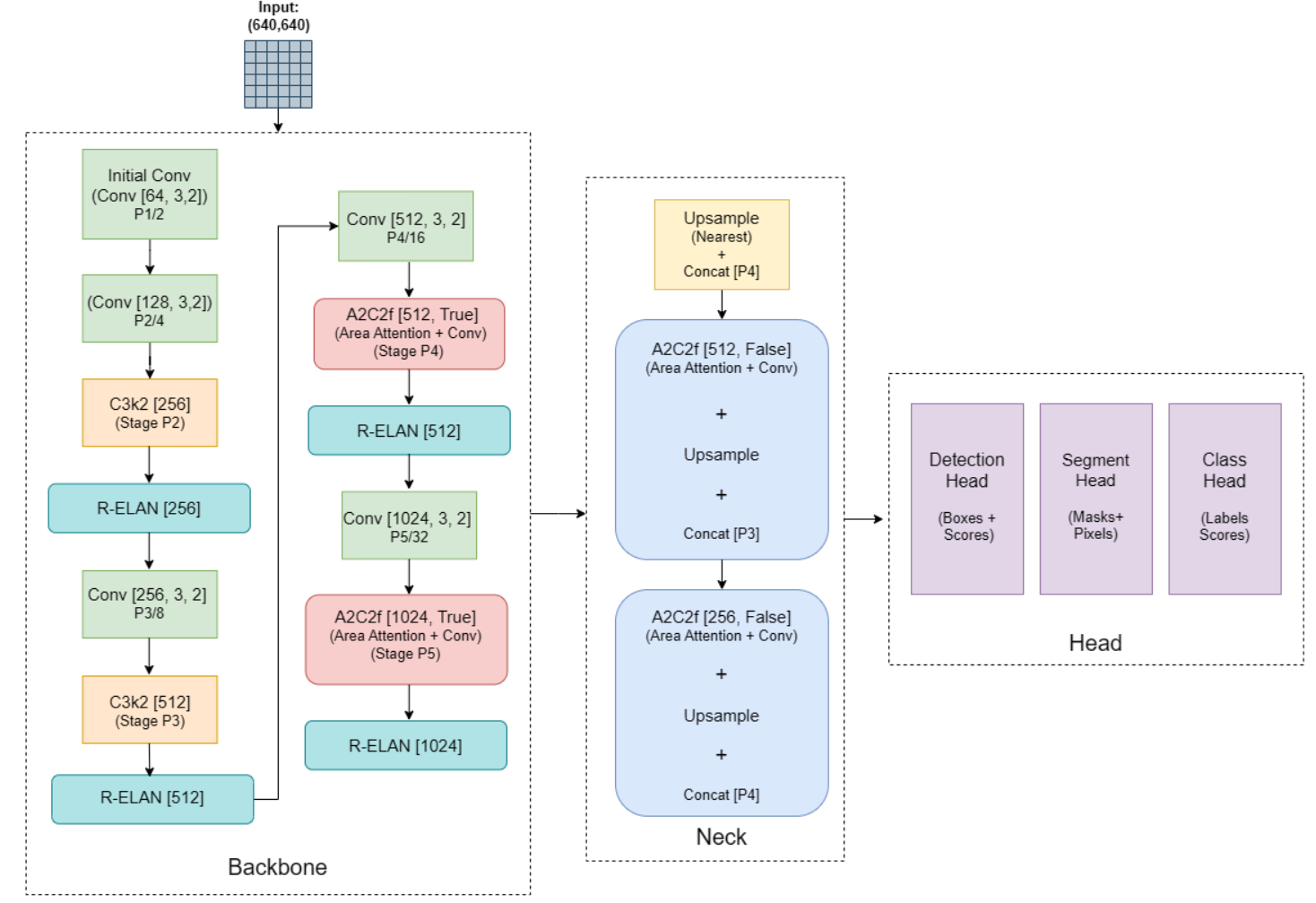
Key Features:
- Area Attention Mechanism: Divides feature maps into multiple regions (default 4), applying localized self‑attention to maintain large receptive fields at lower computational cost.
- Residual ELAN (R‑ELAN): An improved ELAN-based aggregation module featuring block-level residual scaling and a bottleneck-like structure to enhance optimization in attention-rich models.
- Optimized Attention Architecture: Includes efficient FlashAttention support, removal of positional encoding, tuned MLP ratios (1.2–2 vs. typical 4), reduced block depth, selective convolution usage, and a 7×7 separable “position perceiver” convolution for implicit positional reasoning.
- Task Versatility: Supports multiple vision tasks such as object detection, instance segmentation, classification, pose estimation, and oriented bounding boxes (OBB) all with full pipeline support (train/val/infer/export).
- Efficiency & Performance: Delivers higher mAP with fewer parameters.
How to use YOLO with Roboflow
Roboflow is an authorized licensor of YOLO models, meaning it has official rights to distribute, deploy, and support YOLO models (YOLOv5, YOLOv8, YOLOv11, YOLOv12) within its platform. This partnership ensures seamless integration of YOLO models into Roboflow’s dataset, training, and deployment workflows.
There are different ways to use YOLO family of models in Roboflow. Let’s explore them.
Train YOLO Models on Custom Datasets
Training or fine-tuning YOLO models on a custom dataset in Roboflow is simple and flexible, offering two main methods.
- Roboflow Train: A no-code solution within the Roboflow web interface where users can upload and annotate images, then click “Custom Train” to automatically launch a cloud-based training job using best-practice settings.
- Custom Notebook: The second method involves using a Jupyter notebook, where users can download their dataset in YOLO format and run custom training scripts using YOLO (e.g., yolo task=detect mode=train). This approach gives full control over parameters like epochs, image size, and model variant which make it ideal for developers who want to experiment or optimize performance manually.
Using Roboflow to train YOLO Models
A cloud-based, one-click auto training system offered inside Roboflow’s web UI. You upload and annotated dataset and click “Custom Train”, Roboflow handles training on optimized GPUs.
Following are the steps to train YOLO model using Roboflow auto-train.
Step #1: Create an object detection project.
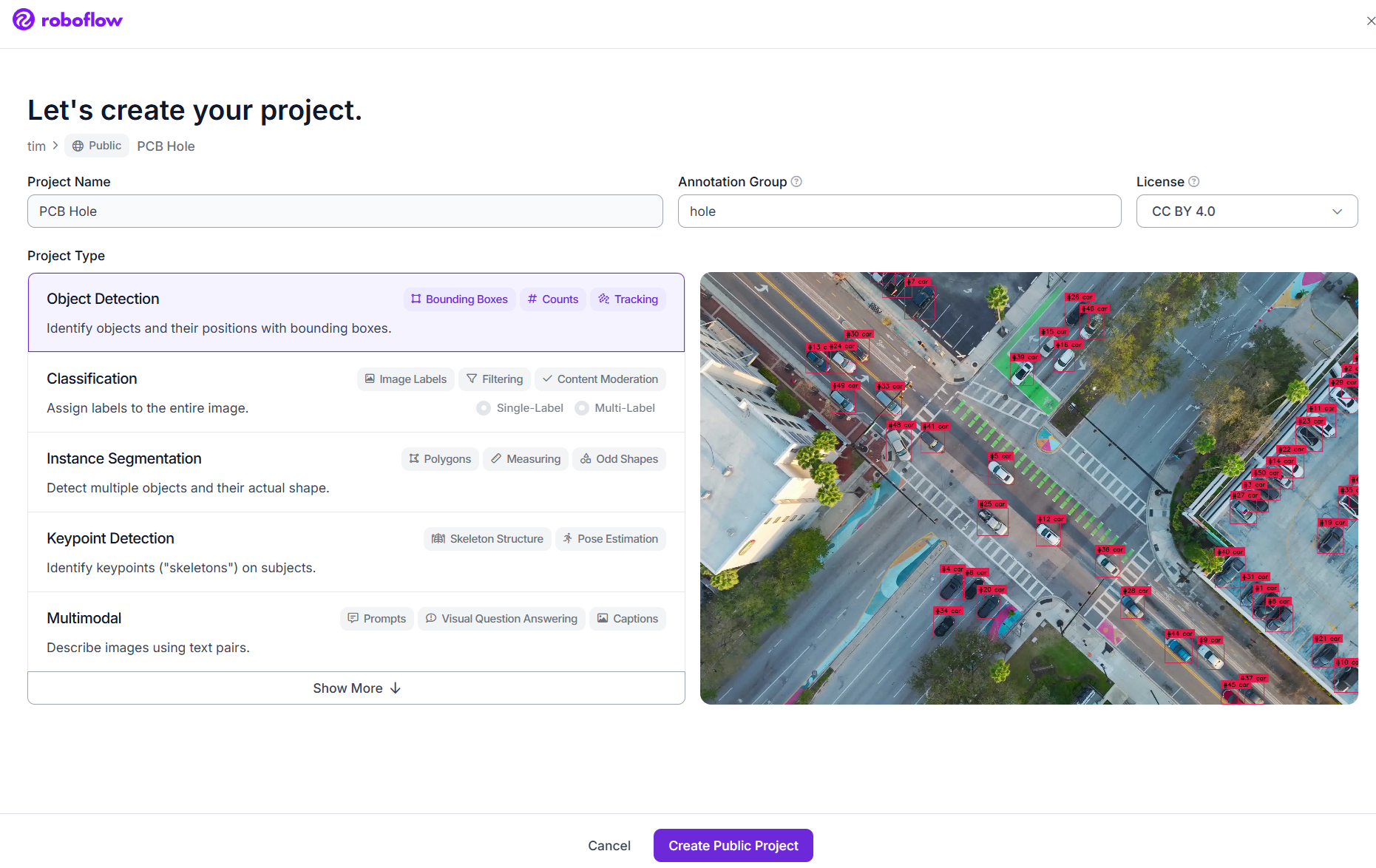
Step #2: Upload and annotate your images in Roboflow. In this example, we will train an object detection model to identify manufacturing defects by detecting holes on printed circuit boards (PCBs).
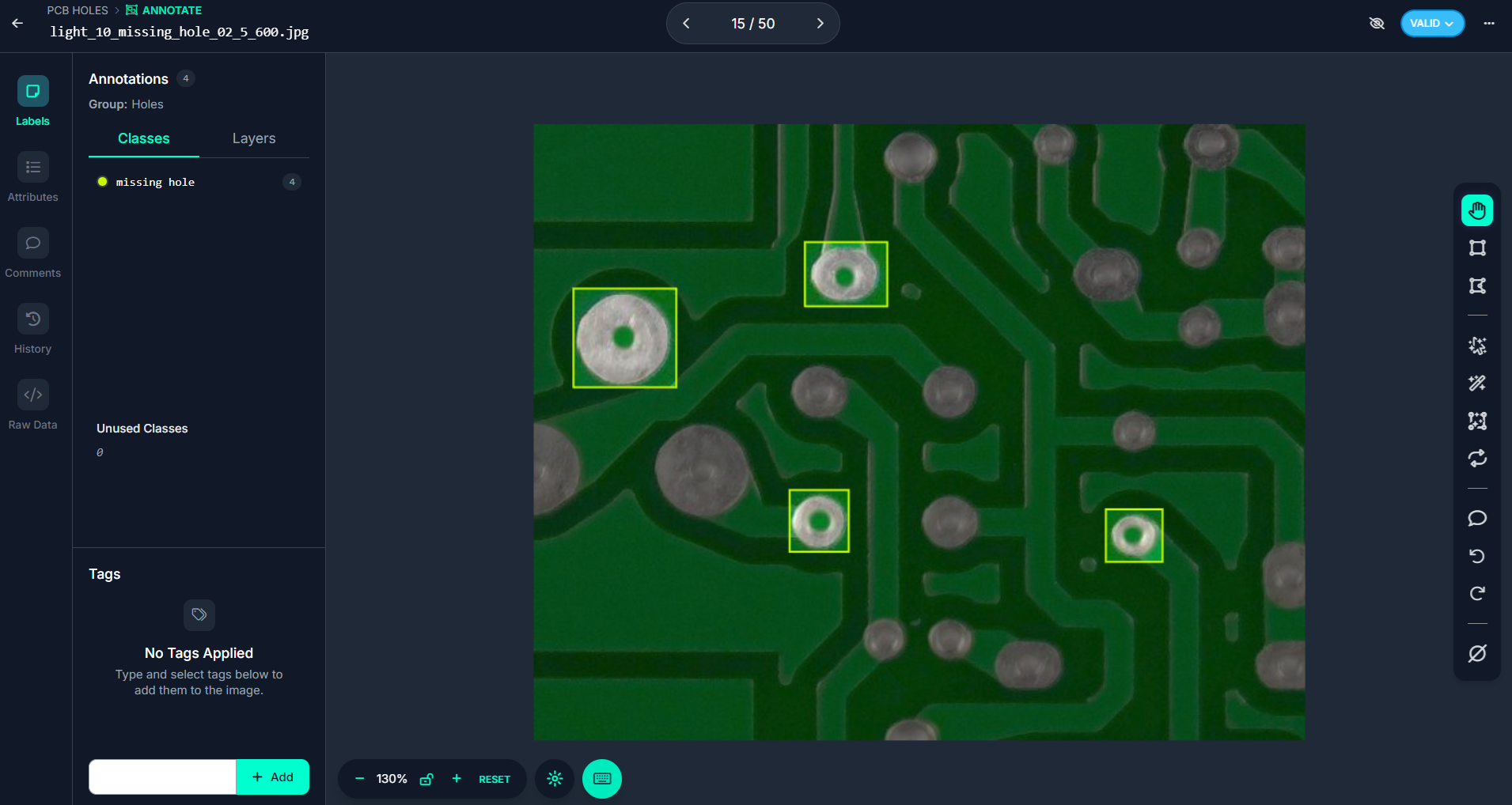
Step #3: Create the dataset version.
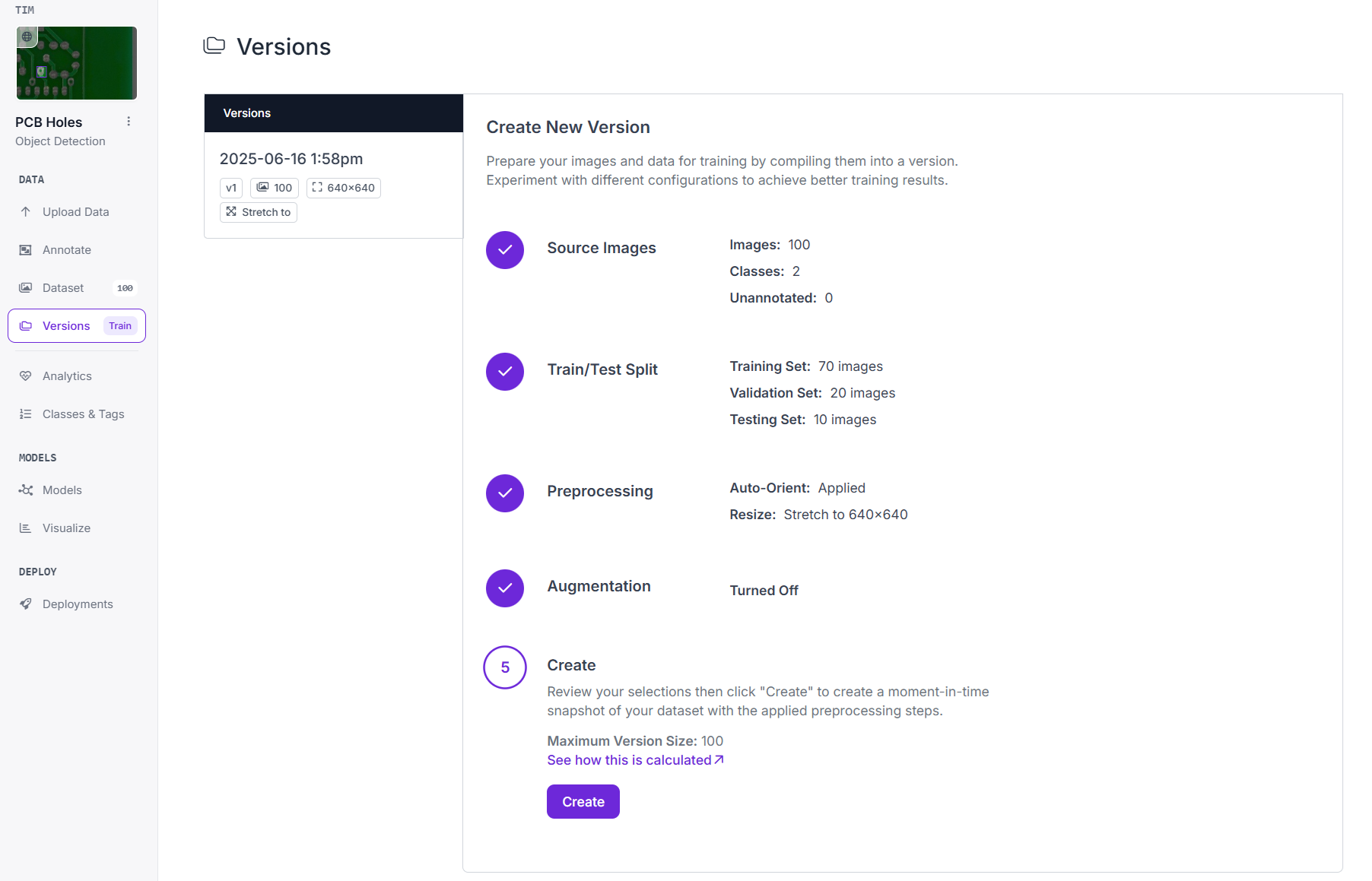
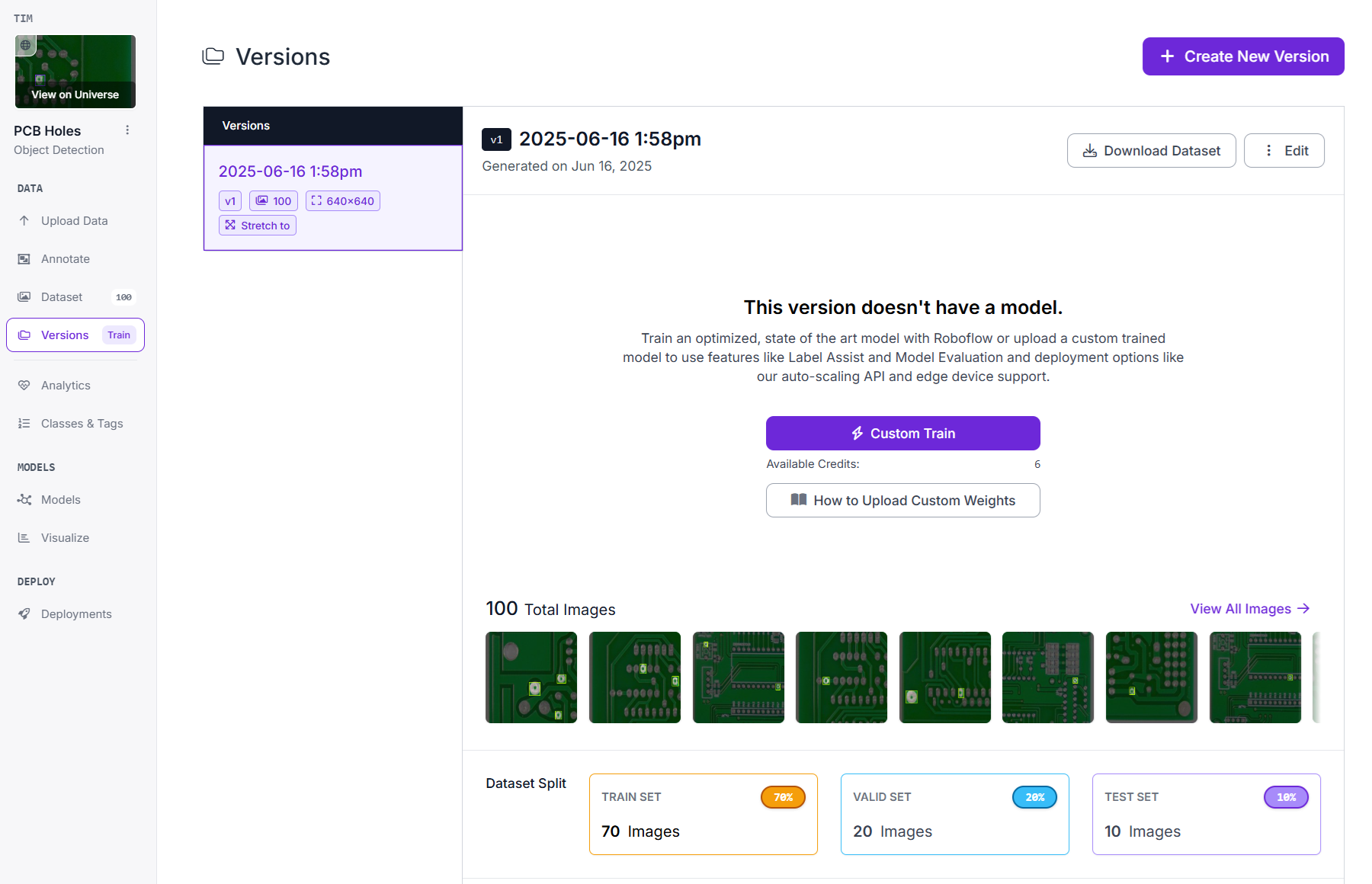
Step #4: Click “Custom Train”.
Choose YOLO models for training and then choose “Fast” and click “Start Training”.
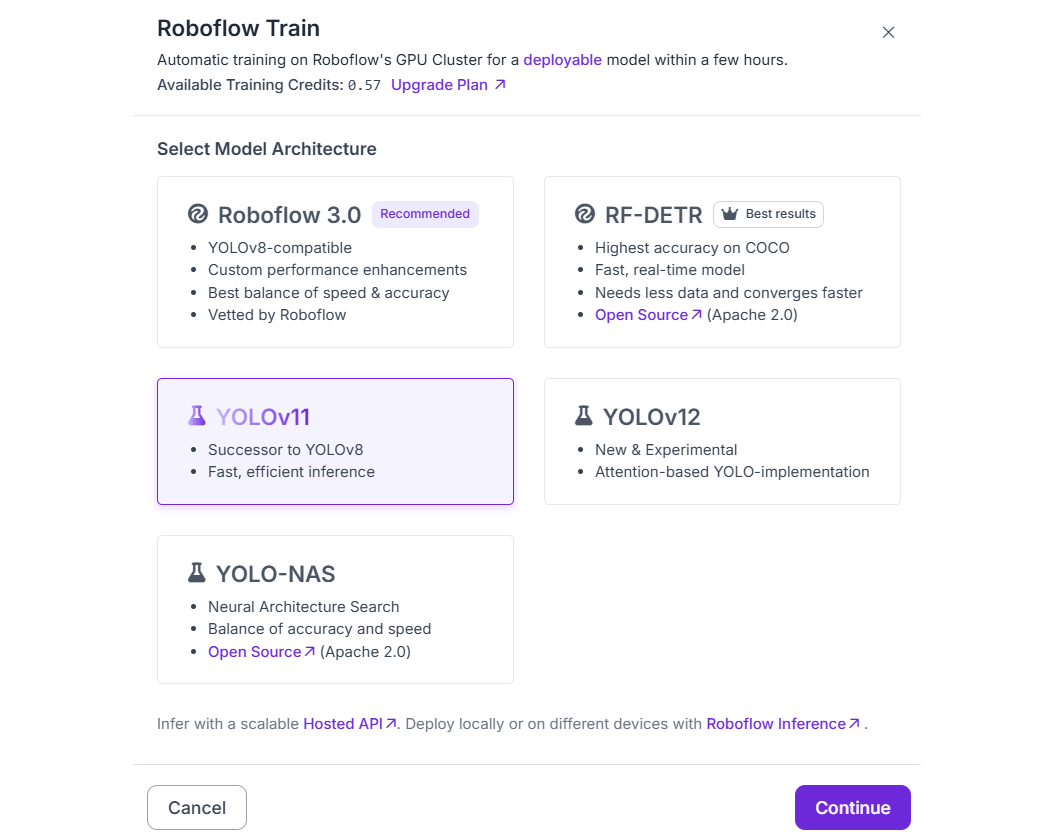
Roboflow uses best-practice settings (including YOLO) to train in the background. Once trained, the model is available on Roboflow inference server.
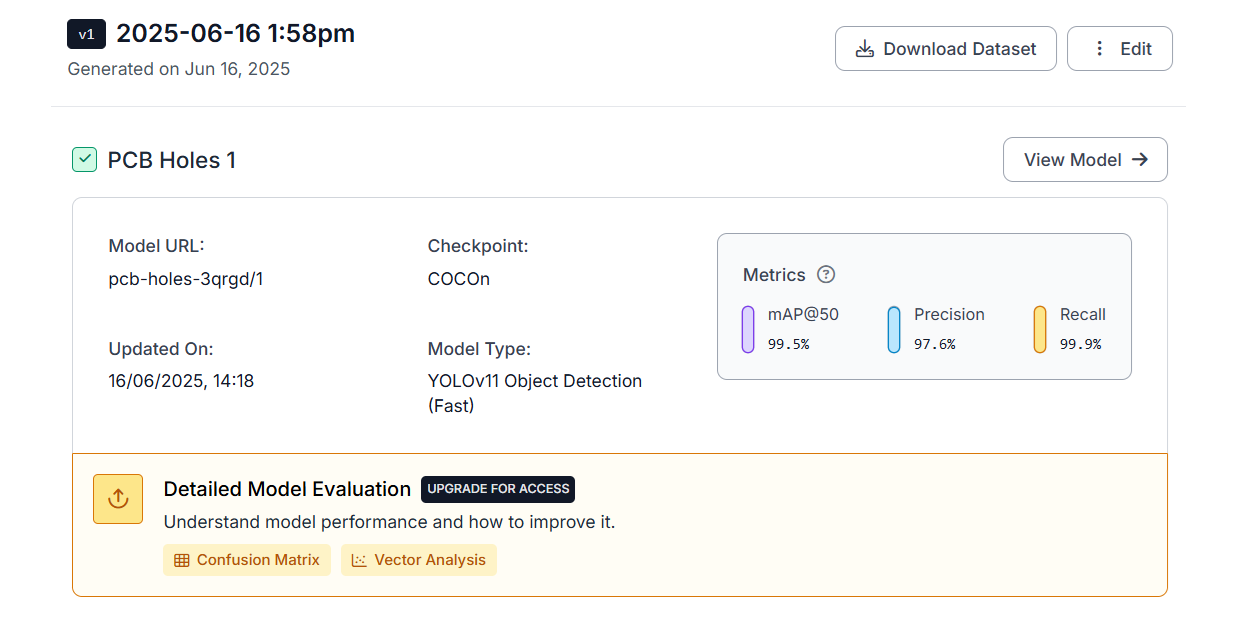
Step #5: Deploy the model
Roboflow offers different deployment options. You can deploy the custom trained model using inference API or download weights.
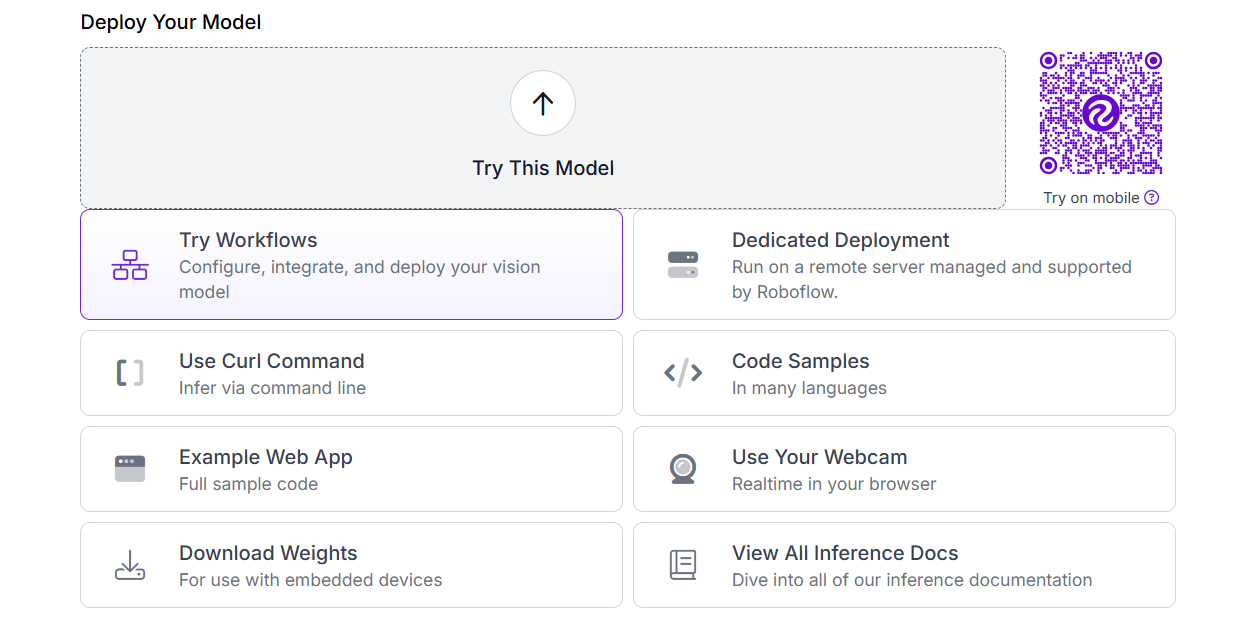
Here’s the hosted image inference example.
# import the inference-sdk
from inference_sdk import InferenceHTTPClient
# initialize the client
CLIENT = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key="YOUR_API_KEY"
)
# infer on a local image
result = CLIENT.infer("PCB_IMAGE.jpg", model_id="pcb-holes-3qrgd/1")
We will use Gradio to build and deploy an interactive web application for PCB defect detection. Gradio provides a simple and user-friendly interface that allows users to upload images and instantly view detection results without needing to install any complex tools or write frontend code.
By integrating it with a YOLOv11 model hosted on Roboflow, the app processes the uploaded PCB image, runs inference to detect holes or defects, displays the results with bounding boxes and labels, and shows the total number of defects found. This makes it easy to demonstrate and test computer vision models in real time directly from the browser. Here’s the code.
import gradio as gr
from inference_sdk import InferenceHTTPClient
from PIL import Image, ImageDraw, ImageFont
# Initialize Roboflow client
CLIENT = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key=" YOUR_API_KEY" # Replace with your Roboflow API key
)
# Inference function
def detect_pcb_defects(image):
image.save("pcb_image.jpg") # Save uploaded image
result = CLIENT.infer("pcb_image.jpg", model_id="pcb-holes-3qrgd/1")
# Load and draw on image
image = image.convert("RGB")
draw = ImageDraw.Draw(image)
count = 0
font = ImageFont.load_default() # You can replace with truetype font if needed
for prediction in result["predictions"]:
x, y, w, h = prediction["x"], prediction["y"], prediction["width"], prediction["height"]
class_name = prediction["class"]
conf = prediction["confidence"]
# Coordinates
left = x - w / 2
top = y - h / 2
right = x + w / 2
bottom = y + h / 2
# Draw bounding box
draw.rectangle([left, top, right, bottom], outline="red", width=2)
# Label text
label = f"{class_name} ({conf:.2f})"
text_size = draw.textbbox((0, 0), label, font=font)
text_width = text_size[2] - text_size[0]
text_height = text_size[3] - text_size[1]
# Draw filled rectangle behind label
draw.rectangle(
[left, top - text_height - 4, left + text_width + 6, top],
fill="red"
)
# Draw label text
draw.text((left + 3, top - text_height - 2), label, fill="white", font=font)
count += 1
return image, f"Holes Detected: {count}"
# Gradio Interface
interface = gr.Interface(
fn=detect_pcb_defects,
inputs=gr.Image(type="pil"),
outputs=["image", "text"],
title="PCB Hole Defect Detector",
description="Upload a PCB image to detect holes using a YOLOv11 model hosted on Roboflow."
)
# Launch app
interface.launch()
When you run the code and upload the image, you should see output as following.
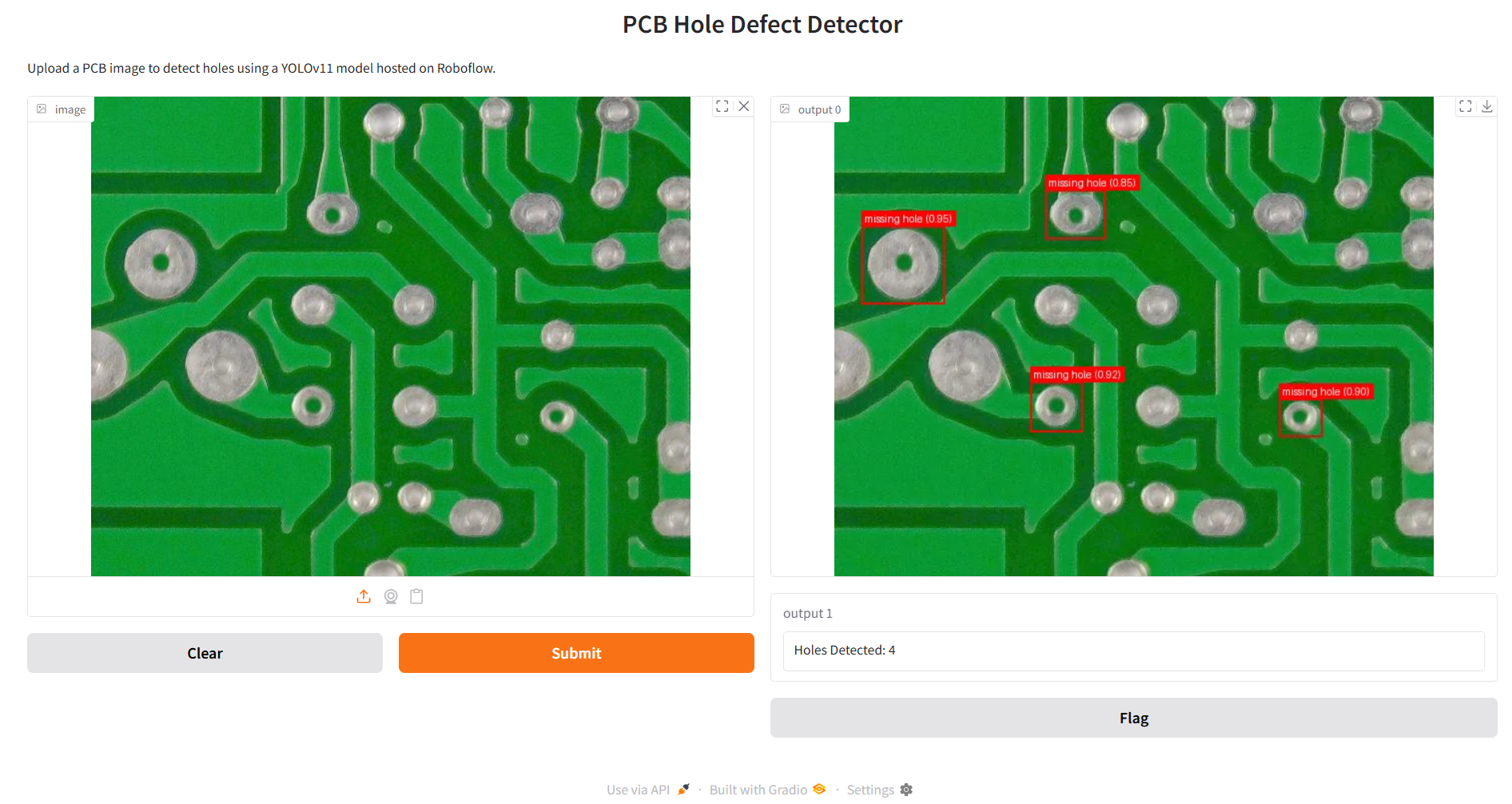
Using YOLO Models in Roboflow Workflows
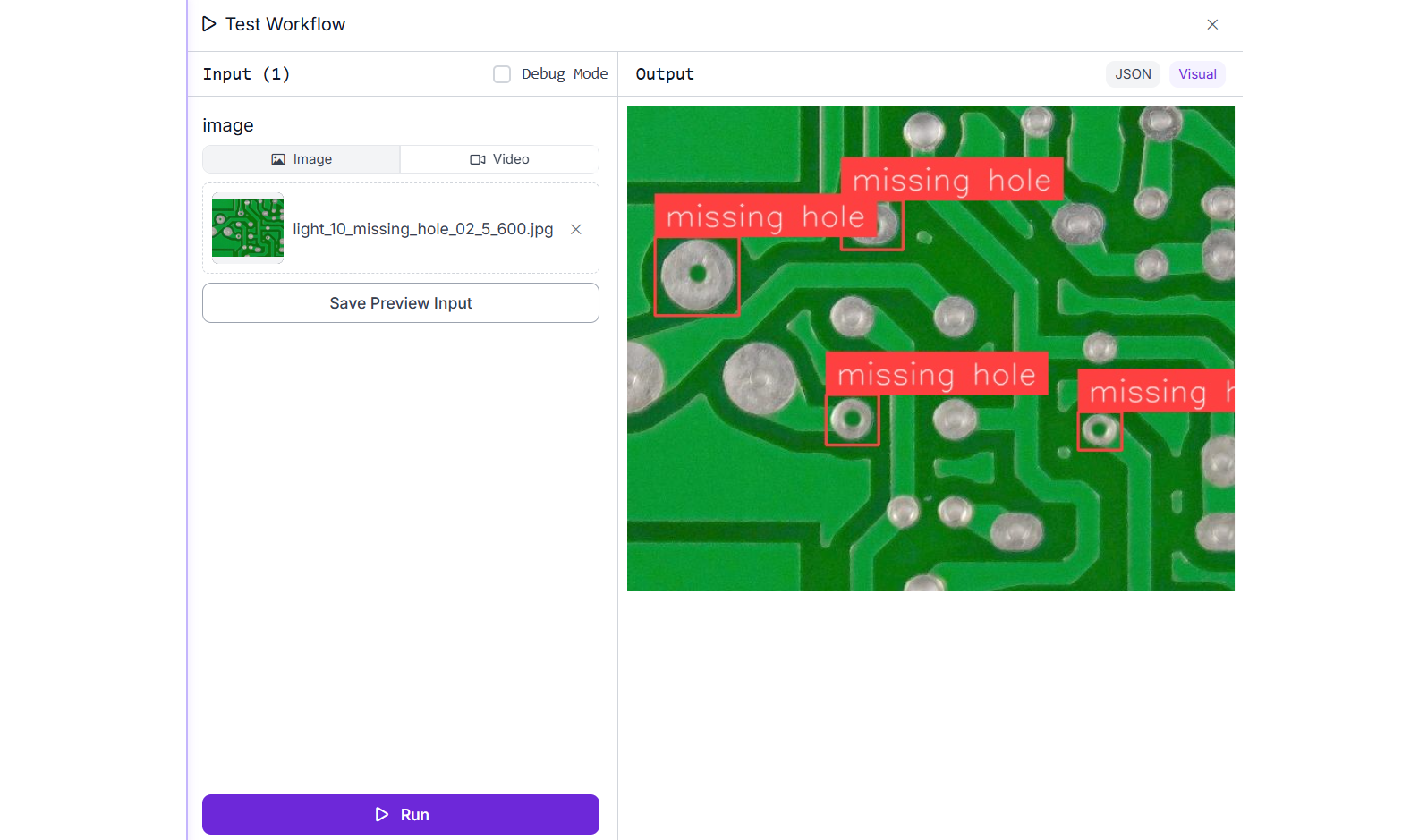
Roboflow Workflows is a powerful tool that enables you to quickly build and deploy computer vision applications. It offers access to pre-trained YOLO models that you can use out of the box, as well as the flexibility to integrate your own custom-trained or fine-tuned YOLO models with the same simplicity. In this example, we’ll create a Workflows application using our YOLOv11 model, trained specifically to detect PCB holes.
Create a Roboflow Workflow as follows. Add the Object Detection block and choose pcb-holes-3qrgd/1 model that we have trained. Also add the Bounding Box Visualization block and Label Visualization block.
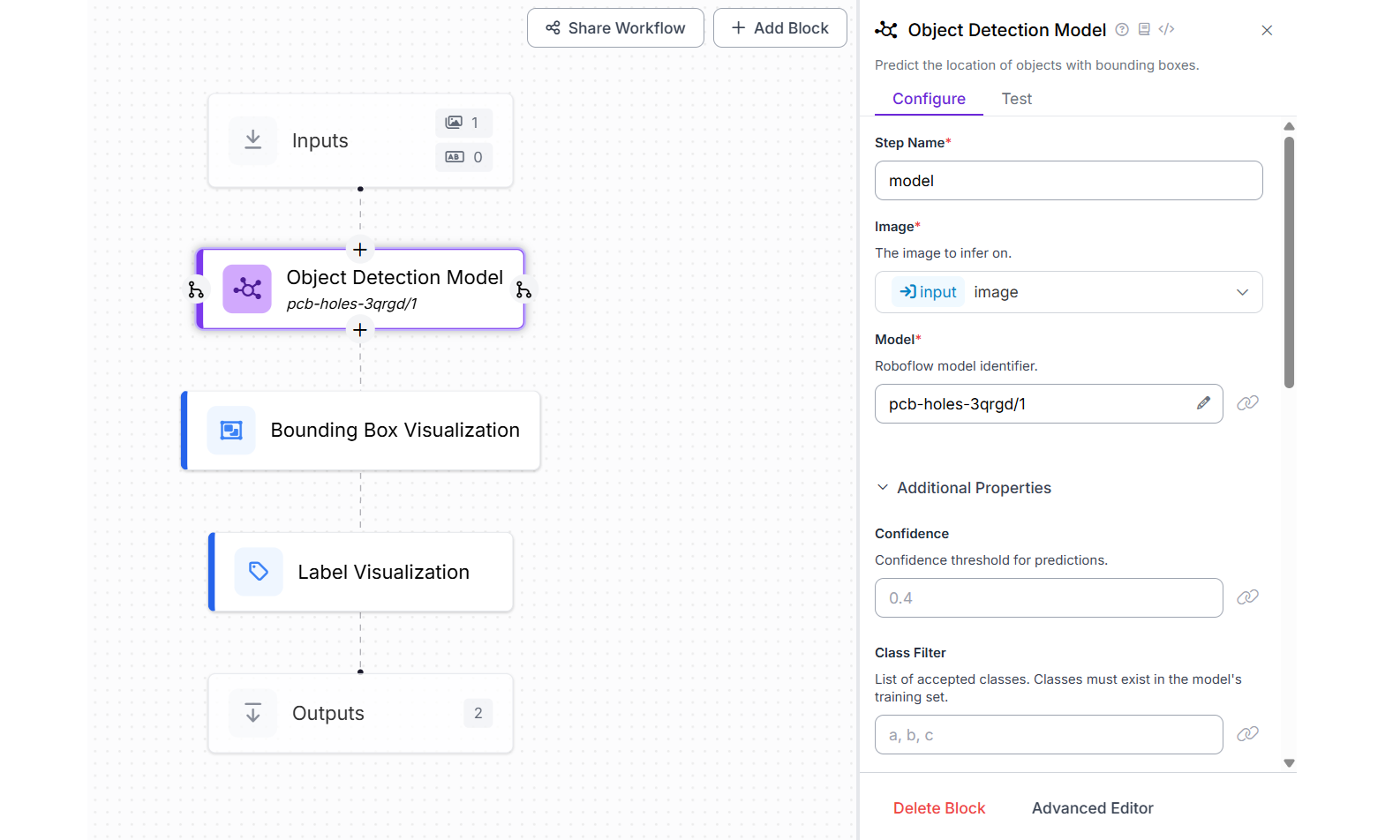
Now run the workflow. You should see output similar to the following.
Using YOLO Object Detection
YOLO object detection has revolutionized the field of computer vision by enabling real-time, accurate object recognition and localization in a single forward pass.
From its initial version to the latest YOLOv12, the architecture has continuously evolved to improve speed, precision, and deployment flexibility across diverse use cases. YOLO models offer a powerful AI solution for different industries and use case as well as enabling AI on edge devices.
With platforms like Roboflow, deploying YOLO, from training to inference, has become accessible even to non-experts, unlocking immense potential for practical computer vision applications. Try it free today.
You might also be interested in RF-DETR - a SOTA, real-time object detection model architecture developed by Roboflow and released under the Apache 2.0 license.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Jun 19, 2025). YOLO Object Detection: An Introduction. Roboflow Blog: https://blog.roboflow.com/yolo-object-detection/