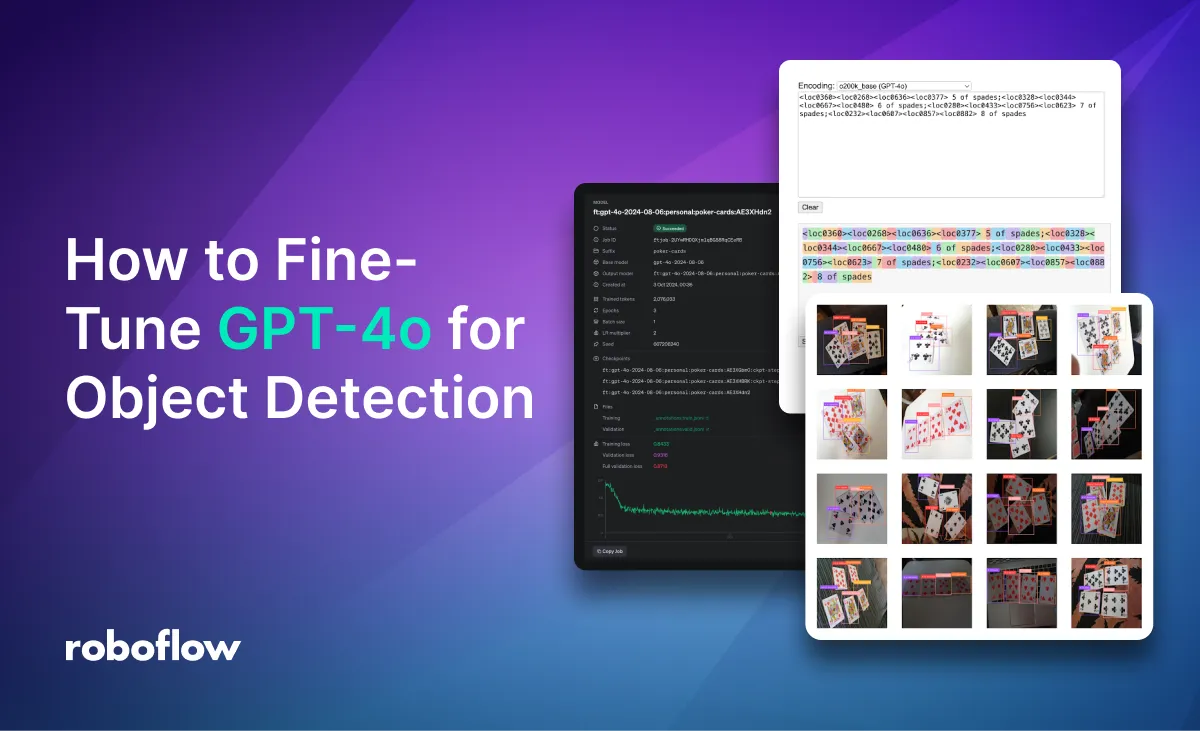
On October 1st, 2024, OpenAI announced support for fine-tuning GPT-4o with vision capabilities. This allows you to customize a version of GPT-4o specifically for tasks where the base model might struggle, such as accurately identifying objects in complex scenes or recognizing subtle visual patterns. While GPT-4o demonstrates impressive general vision capabilities, fine-tuning allows you to enhance its performance for niche or specialized applications.
The Roboflow team has experimented extensively with fine-tuning models, and we are excited to share how we trained GPT-4o, and how you can train your own GPT-4o vision model for object detection. Object detection is a task that the base GPT-4o model finds challenging without fine-tuning.
In this guide, we will demonstrate how to fine-tune GPT-4o using a playing card dataset. While seemingly straightforward, this dataset presents several important challenges for vision language models: dozens of object classes, multiple objects in each image, class names consisting of multiple words, and a high degree of visual similarity between objects.

GPT-4o Vision Dataset Structure
GPT-4o expects data in a specific format, as shown below. <IMAGE_URL> should be replaced with an HTTP link to your image, while <USER_PROMPT> and <MODEL_ANSWER> represent the user's query about the image and the expected response, respectively. Depending on the vision-language task, these could be, for example, a question about the image and its corresponding answer in the case of Visual Question Answering (VQA).
{
'messages': [
{
'role': 'system',
'content': 'You are a helpful assistant.'
},
{
'role': 'user',
'content': <USER_PROMPT>
},
{
'role': 'user',
'content': [
{
'type': 'image_url',
'image_url': {'url': <IMAGE_URL>}
}
]
},
{
"role": "assistant",
"content": <MODEL_ANSWARE>
}
]
}
Drawing from our experience with other VLMs, we decided to format the <USER_PROMPT> and <MODEL_ANSWER> in the same way as for PaliGemma.
<USER_PROMPT>consists of the keyword detect followed by a semicolon-separated list of the classes you want to locate.
detect 10 of clubs ; 10 of diamonds ; 10 of hearts ; 10 of spades ...<MODEL_ANSWER>is a semicolon-separated list of detection definitions. Each definition comprises the bounding box geometry description followed by the name of the detected class. The box coordinates are arranged in the ordery_min, x_min, y_max, x_max, then normalized, multiplied by1024, and rounded to integers.
<loc0161><loc0145><loc0640><loc0451> 9 of spades ; <loc0120><loc0485><loc0556><loc0744> 10 of spades ; <loc0477><loc0459><loc0848><loc0664> jack of spades ; <loc0295><loc0667><loc0676><loc0896> queen of spades ; <loc0600><loc0061><loc0978><loc0330> king of spadesIf you want to learn more about PaliGemma and the detection format it supports, check out our YouTube tutorial:
Download GPT-4o Vision Format Dataset
Fortunately, you don't have to manually convert your object detection dataset to this format. Any detection dataset on Roboflow Universe can now be exported in the format required for GPT-4o vision fine-tuning. You can automate this entire process using roboflow SDK.
pip install roboflowfrom roboflow import Roboflow
rf = Roboflow(api_key=<ROBOFLOW_API_KEY>)
workspace = rf.workspace("roboflow-jvuqo")
project = workspace.project("poker-cards-fmjio")
version = project.version(3)
dataset = version.download("openai")Upload a training file
Once you have your dataset in the correct format and size, it's time to upload it. We'll use the OpenAI SDK for this.
pip install openaiNext, create an instance of the OpenAI client, passing in your OPENAI_API_KEY, which you can find in your OpenAI account settings:
from openai import OpenAI
client = OpenAI(api_key=<OPENAI_API_KEY>)The final step is to provide the paths to the files containing your training and validation subsets and upload them using the client we initialized earlier. Once uploaded, each file will be assigned a unique ID that we'll use shortly when submitting the fine-tuning job.
training_file_upload_response = client.files.create(
file=open(f"{dataset.location}/_annotations.train.jsonl", "rb"),
purpose="fine-tune"
)
training_file_upload_response
# FileObject(
# id='file-OeucFR8fKMF68qdJ9yCSESPv',
# bytes=548592,
# created_at=1727908593,
# filename='_annotations.train.jsonl',
# object='file',
# purpose='fine-tune',
# status='processed',
# status_details=None
# )
validation_file_upload_response = client.files.create(
file=open(f"{dataset.location}/_annotations.valid.jsonl", "rb"),
purpose="fine-tune"
)
validation_file_upload_response
# FileObject(
# id='file-uo8nWSYWdo51SF9XodisEn6K',
# bytes=30011,
# created_at=1727908594,
# filename='_annotations.valid.jsonl',
# object='file',
# purpose='fine-tune',
# status='processed',
# status_details=None
# )GPT-4o Vision Training
Finally, we're ready to start training. It's important to note that for now, vision fine-tuning can only be performed on the gpt-4o-2024-08-06 model. To make it easier to identify our model later, it's helpful to add a suffix, which will be appended to the checkpoint name of our trained model.
fine_tuning_response = client.fine_tuning.jobs.create(
training_file=training_file_upload_response.id,
validation_file=validation_file_upload_response.id,
suffix="poker-cards",
model="gpt-4o-2024-08-06"
)
fine_tuning_response
# FineTuningJob(
# id='ftjob-2UYwRHDQXjm1qBG88RqCEeRB',
# created_at=1727908609,
# error=Error(code=None, message=None, param=None),
# fine_tuned_model=None,
# finished_at=None,
# hyperparameters=Hyperparameters(
# n_epochs='auto',
# batch_size='auto',
# learning_rate_multiplier='auto'
# ),
# model='gpt-4o-2024-08-06',
# object='fine_tuning.job',
# organization_id='org-sLGE3gXNesVjtWzgho17NkRy',
# result_files=[],
# seed=667206240,
# status='validating_files',
# trained_tokens=None,
# training_file='file-OeucFR8fKMF68qdJ9yCSESPv',
# validation_file='file-uo8nWSYWdo51SF9XodisEn6K',
# estimated_finish=None,
# integrations=[],
# user_provided_suffix='poker-cards'
# )Once training begins, we can track its progress in the fine-tuning dashboard.
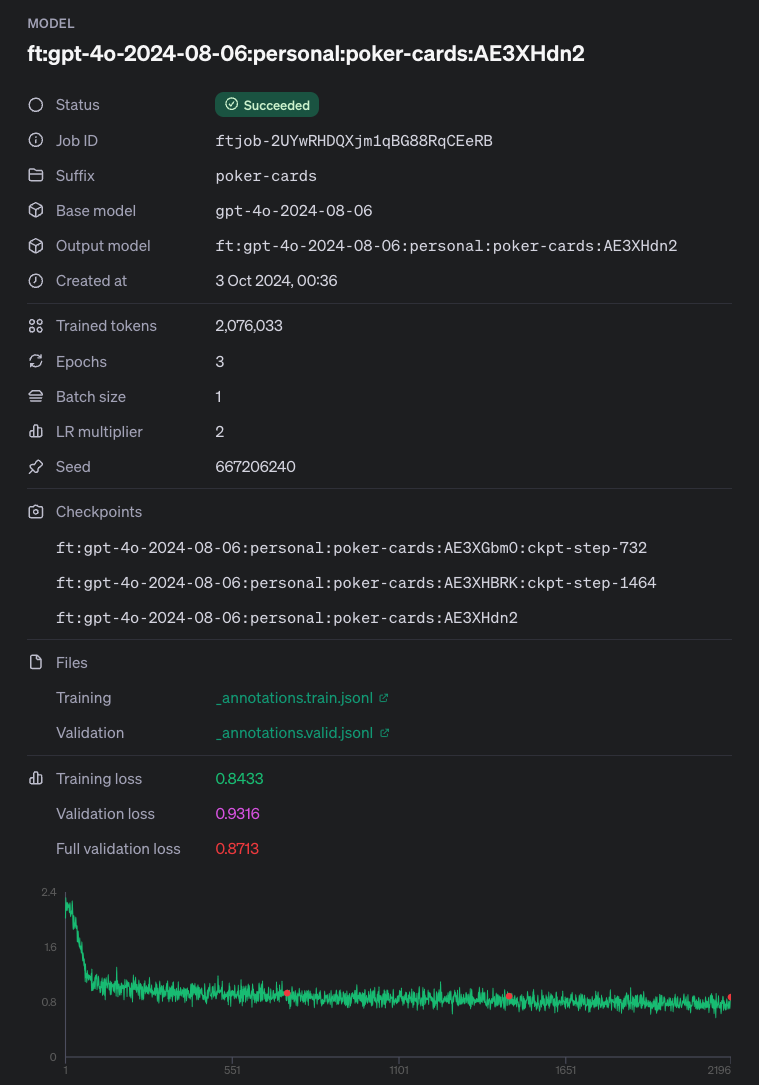
Checking GPT-4o Vision Training Status
After you've started a fine-tuning job, it may take some time to complete. Your job may be queued behind other jobs in theour system, and training a model can take minutes or hours depending on the model and dataset size. However, you can check the status of your training job at any time in the UI or via an API call:
status_response =client.fine_tuning.jobs.retrieve(fine_tuning_response.id)
status_response
# FineTuningJob(
# id='ftjob-2UYwRHDQXjm1qBG88RqCEeRB',
# created_at=1727908609,
# error=Error(code=None, message=None, param=None),
# fine_tuned_model='ft:gpt-4o-2024-08-06:personal:poker-cards:AE3XHdn2',
# finished_at=1727913545,
# hyperparameters=Hyperparameters(
# n_epochs=3,
# batch_size=1,
# learning_rate_multiplier=2
# ),
# model='gpt-4o-2024-08-06',
# object='fine_tuning.job',
# organization_id='org-sLGE3gXNesVjtWzgho17NkRy',
# result_files=['file-Kk8dqKdelvneesBc9uVWfLdZ'],
# seed=667206240,
# status='succeeded',
# trained_tokens=2076033,
# training_file='file-OeucFR8fKMF68qdJ9yCSESPv',
# validation_file='file-uo8nWSYWdo51SF9XodisEn6K',
# estimated_finish=None,
# integrations=[],
# user_provided_suffix='poker-cards'
# )Using Fine-tuned GPT-4o Model
Once training is completed successfully — the fine-tuning job status in the response above changes to succeeded — you can run predictions using your model. The identifier of your fine-tuned model can also be found in the status response under status_response.fine_tuned_model. The structure of the messages used to query your model is almost identical to a dataset entry: it includes a system prompt, a user prompt, and the image to which the user prompt refers.
messages = [
{
'role': 'system',
'content': 'You are a helpful assistant.'
},
{
'role': 'user',
'content': 'detect 5 of spades;6 of spades;7 of spades;8 of spades'
},
{
'role': 'user',
'content': [
{
'type': 'image_url',
'image_url': {'url': <IMAGE_URL>}
}
]
}
]
completion = client.chat.completions.create(
model=status_response.fine_tuned_model,
messages=messages
)
completion.choices[0].message
# ChatCompletionMessage(
# content='<loc0360><loc0268><loc0636><loc0377> 5 of spades;<loc0328><loc0344><loc0667><loc0480> 6 of spades;<loc0280><loc0433><loc0756><loc0623> 7 of spades;<loc0232><loc0607><loc0857><loc0882> 8 of spades',
# refusal=None,
# role='assistant',
# function_call=None,
# tool_calls=None
# )Parsing GPT-4o Vision Model Predictions
Models like GPT-4o and their open-source alternatives, such as PaliGemma and Florence-2, generate a sequence of tokens as output. These tokens require post-processing to obtain a meaningful representation of the detected objects' positions.
VLMs work by encoding both the image and the prompt into a shared embedding space, allowing them to reason about the relationship between visual and textual information.
As mentioned earlier, we utilized a representation consistent with the one proposed by PaliGemma, enabling us to process the output similarly. An example of the raw output from our fine-tuned GPT-4o model is shown below:
completion.choices[0].message.content
# <loc0360><loc0268><loc0636><loc0377> 5 of spades;<loc0328><loc0344><loc0667><loc0480> 6 of spades;<loc0280><loc0433><loc0756><loc0623> 7 of spades;<loc0232><loc0607><loc0857><loc0882> 8 of spades
The supervision package provides ready-to-use utilities that allow you to parse strings in the format supported by popular models, convert them into the more traditional representation used in object detectors, and then visualize them.
import requests
import supervision as sv
from PIL import Image
image = Image.open(requests.get(<IMAGE_URL>, stream=True).raw)
detections = sv.Detections.from_lmm(
lmm=sv.LMM.PALIGEMMA,
result=completion.choices[0].message.content,
resolution_wh=image.size
)
box_annotator = sv.BoxAnnotator(color_lookup=sv.ColorLookup.INDEX)
label_annotator = sv.LabelAnnotator(color_lookup=sv.ColorLookup.INDEX)
annotated_image = image.copy()
annotated_image = box_annotator.annotate(
scene=image,
detections=detections
)
annotated_image = label_annotator.annotate(
scene=annotated_image,
detections=detections
)
supervision.GPT-4o Vision Fine-tune Price
The cost of GPT-4o fine-tuning is based on the number of training tokens, calculated as the number of tokens in the training dataset multiplied by the number of training epochs. In the context of vision-language models like GPT-4o, a token represents a fundamental unit of information, which can be a word in the text or a portion of an image.
Image inputs are first tokenized based on image size, and then priced at the same per-token rate as text inputs. The larger your training dataset or the longer the training process, the higher the cost will be. Currently, the unit price is $25 / 1M training tokens.
OpenAI doesn't charge you for the tokens in the validation set.
You can find the total number of training tokens for your training job in the Fine-tuning dashboard and in the response that checks the status of your training job. It was around 2M in our case, so the estimated cost of training this model was about $50.
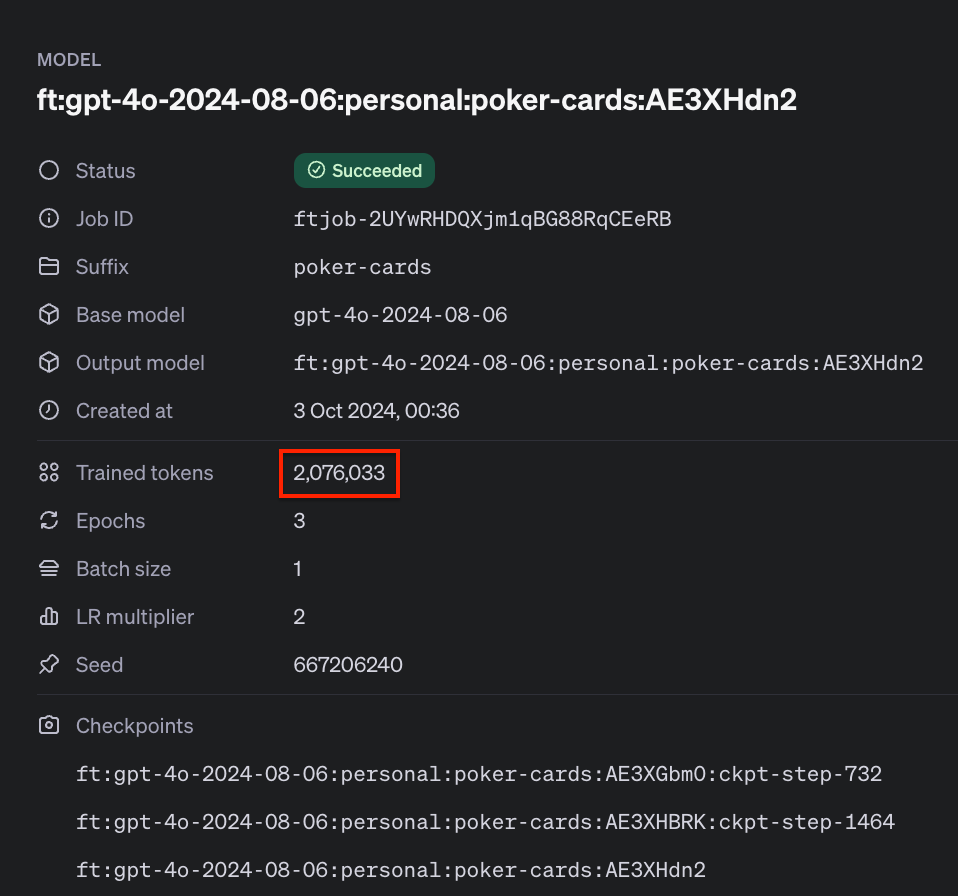
The number of tokens in the training dataset depends on many factors that can be optimized, such as the number of images in the dataset, the resolution of the images, and, in the case of object detection, the format of the text storing the bounding box coordinates, which may contain more or fewer text tokens. It is therefore possible that the same training effect could be achieved using even several times fewer tokens, and thus reduce the training cost.

Things to Consider Fine-tuning GPT-4o Vision
While fine-tuning GPT-4o offers exciting possibilities, it's essential to be aware of certain factors before diving in.
Censorship
During our experimentation with OpenAI GPT-4o fine-tuning across various vision tasks, we encountered an unexpected hurdle with OCR. We chose the CATMuS Medieval dataset, which contains images of medieval manuscripts and their corresponding transcribed text. However, upon launching the fine-tuning job, we received the following message:> The job failed due to an invalid training file. Too many images were skipped due to moderation. Please ensure that your images do not contain content that violates our usage policy.
Price for Fine-tuning GPT-4o Vision
As demonstrated in our example, training a model on a dataset of approximately 800 images proved to be quite expensive. In comparison, using the same dataset, we could train a convolutional model like YOLO or even a VLM like Florence-2 for free using Google Colab. On the other hand, OpenAI allows you to process 1M tokens for free every day. Enough to experiment a bit!
Privacy
Fine-tuning GPT-4o requires uploading your data to OpenAI's servers. This raises privacy concerns, especially for sensitive data. It's crucial to be aware that your data will be processed and stored by OpenAI. Furthermore, even after training is complete, the fine-tuned model remains accessible only through the OpenAI API, limiting your control and ownership over the model.
Conclusions
Fine-tuning GPT-4o for object detection allows you to enhance its performance for specific tasks, leveraging its understanding of both visual and textual information. However, consider the costs and limitations before starting.
While promising, dedicated models like YOLOv10 are likely more effective for accuracy-critical tasks. GPT-4o's cloud dependency requires a stable internet connection and introduces latency, hindering production use and real-time applications.
Often, alternative models or open-source VLMs provide a more cost-effective, privacy-conscious, and flexible solution. As the field evolves, expect advancements in fine-tuning and accessibility. Stay informed and evaluate the trade-offs to harness the potential of VLMs for your computer vision needs.
Cite this Post
Use the following entry to cite this post in your research:
Piotr Skalski. (Oct 3, 2024). How to Fine-Tune GPT-4o for Object Detection. Roboflow Blog: https://blog.roboflow.com/gpt-4o-object-detection/
Discuss this Post
If you have any questions about this blog post, start a discussion on the Roboflow Forum.