
Computer vision has rapidly evolved from a research concept into a powerful technology that drives everything from self-driving cars and medical diagnostics to factory automation and smart cities. Behind this transformation is a growing ecosystem of companies each specializing in different aspects of visual intelligence.
In this blog, we’ll explore the different types of computer vision companies, categorized by the industries they serve and the tools they provide. You’ll also discover a curated list of the best computer vision platforms and service providers, including their key offerings, advantages, and how you can get started with each. This guide will help you:
- Understand what computer vision is and different computer vision tasks/techniques.
- Discover the different types of companies in the CV space.
- Learn how companies specialize across sectors like automotive, manufacturing, healthcare, and retail.
- Get insights into the top players in the field, including Roboflow, Google Vision AI, Amazon Sagemaker, Microsoft Azure AI, and Scale AI.
- Understand key features of top platforms, and how you can get started with them.
By the end of this blog, you’ll have a clear understanding of the computer vision ecosystem, how to choose the right platform or service, and how these technologies are enabling machines to “see” and make sense of the world.
What Is Computer Vision?
Computer vision is a specialized subfield of artificial intelligence (AI) focused on enabling machines to “see,” interpret, and understand visual data (such as images, videos, or 3D scans). While human vision benefits from years of contextual learning, computer vision teaches machines to mimic that capability through algorithms and training on massive datasets.
More precisely, it refers to methods for acquiring, processing, analyzing, and understanding digital images, extracting high‑dimensional or symbolic information about the real world for instance, identifying objects, estimating depth, or detecting anomalies.
Originating in the late 1960s within university AI research, early computer vision attempted rudimentary tasks such as describing what a camera sees. The rise of deep learning has breathed new life into the field of computer vision. Today’s computer vision systems typically consist of deep neural networks like convolutional neural networks (CNNs) or vision transformers that are trained on massive, labeled datasets. They learn hierarchical visual features from edges and textures in early layers to entire objects or even scenes in later layers essentially learning to “see” by example.
Computer Vision Tasks and Techniques
Computer vision encompasses many sub‑tasks and methods. The following are the common tasks/methods used in computer vision:
- Image Processing: Low‑level operations applied to digital images such as filtering, denoising, normalization, contrast adjustment, or edge detection to improve image quality or prepare data for downstream analysis.
- Image Classification: Assigning one or more category labels to an entire image (e.g. “cat,” “no bicycle”) by analyzing its global features and content.
- Object Detection: Is about locating and classifying individual objects within an image or video via bounding boxes around instances of target classes like “person,” “car,” or “dog”.
- Image Segmentation: Partitioning an image into meaningful regions or pixel‐level classes. In semantic segmentation, each pixel is labeled by class; in instance segmentation, individual objects are distinguished.
- Keypoint Detection: Identifying specific landmark points in an image (such as facial landmarks, joint positions, or object corner points) that serve as anchors for further analysis.
- Pose Estimation: Predicting the configuration of keypoints (e.g. human joints or object pivots) in 2D or 3D space in order to infer posture or orientation from visual inputs.
- Object Tracking: Maintaining the identity and position of one or more objects across video frames, enabling continuous tracking even during occlusion or motion.
- Depth Estimation: Estimating the distance of each pixel or region from the camera, often from stereo images or from single (monocular) views using learned models.
Specialized Computer Vision Tasks & Techniques
The following are some of the advanced computer vision task/techniques:
- Optical Flow: Estimate the motion of objects between two frames that are taken at different times. It produces a vector field where each vector is a displacement vector showing the movement of points from the first frame to the second.
- Visual Odometry: Determines the camera’s position and orientation by tracking visual changes across frames and used to infer motion trajectory over time.
- Structure from Motion (SfM): Reconstructs 3D structures from 2D image sequences. It involves identifying distinctive features in multiple images and using them to infer the 3D geometry of the scene and the camera positions.
- Bag‑of‑Visual‑Words (BoVW): Represents images using histograms of clustered local feature descriptors (e.g. SIFT). Each “visual word” captures a repeated pattern and images are compared via these histograms.
- Rigid Motion Segmentation: Separates different rigid moving components in video like cars and humans based on their independent motion patterns and clusters of pixel trajectories.
- Neural Radiance Fields (NeRF): A neural scene representation that encodes a 3D scene as a continuous volumetric radiance field, enabling synthesis of new viewpoints with photorealistic rendering.
- Visual Question Answering (VQA): Given an image and a natural language question, the system produces a correct answer by reasoning over both visual content and contextual knowledge.
- Image Captioning: Automatically generates descriptive text for an image using encoder-decoder architectures that map visual features to natural-language sentences.
- Image Generation: Synthesizes new images, often guided by textual prompts, using generative AI models.
- Image Restoration: Enhances degraded images by removing noise, blur, or compression artifacts to recover improved visual quality.
- Super‑Resolution: Upscales low-resolution images to higher resolution with enhanced detail and clarity, using deep learning approaches.
Explore the Best Computer Vision Companies
In this section, we’ll take a closer look at five leading computer vision companies, exploring the key services and features they offer. We’ll also guide you on how to get started with each platform.
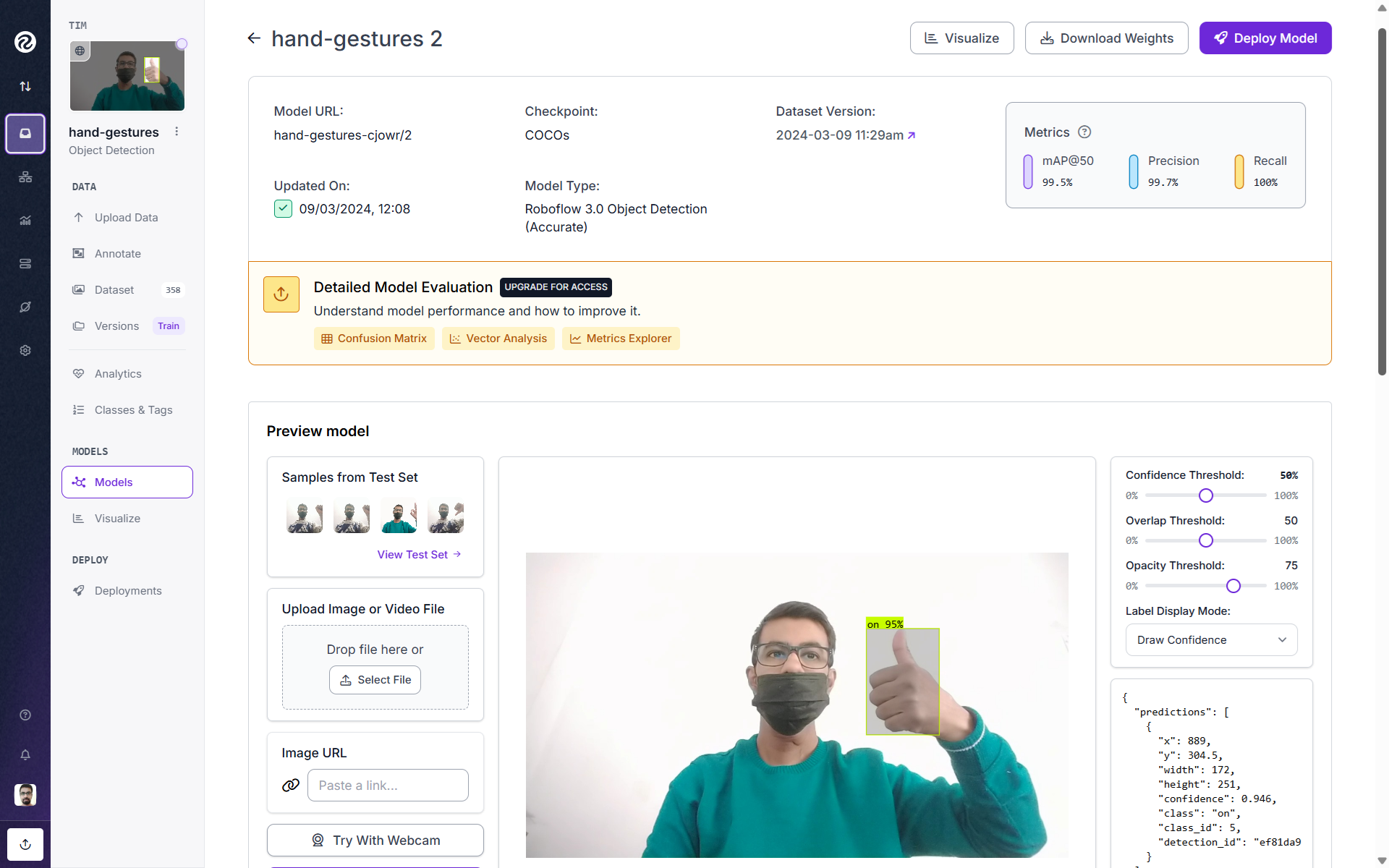
1. Roboflow
Roboflow is an end-to-end computer vision platform designed to simplify the entire computer vision development pipeline. Founded with the mission to make the world programmable, Roboflow has become a leading platform used by over 1 million engineers and more than half of Fortune 100 companies.
Roboflow's approach is centered around democratizing computer vision by providing tools that handle the complete workflow from data collection to model deployment. The platform abstracts away the complexity of computer vision development, allowing developers to focus on solving business problems rather than dealing with technical infrastructure.
Roboflow provides following key services:
- Data Management and Preprocessing tools provide a centralized platform to organize, manage, and version image datasets. It enables automatic image preprocessing including resizing, normalization, and format conversion ensuring consistent input for training. Robust data augmentation techniques such as flipping, rotation, and brightness adjustments are applied automatically to improve dataset diversity and model generalization. With built-in dataset versioning, users can track changes and maintain reproducibility across different experiment runs.
- Annotation and Labeling in Roboflow is powered by intuitive, AI-assisted tools that significantly speed up the annotation process. Users can collaborate on projects through multi-user annotation workflows, complete with quality assurance features. Auto-labeling capabilities allow users to bootstrap annotations using pre-trained models, reducing manual effort. Roboflow supports a wide range of export formats including COCO, YOLO, Pascal VOC, and custom schemas, making it compatible with nearly all major computer vision frameworks.
- Model Training and Development is streamlined through built-in AutoML features, which automate model selection and hyperparameter tuning for optimal performance. Developers can also train custom models using frameworks like PyTorch or TensorFlow. Additionally, Roboflow provides access to a library of high-performing pre-trained models for tasks like classification, detection, and segmentation. A model comparison tool lets users evaluate and benchmark different architectures and configurations for informed decision-making.
- Model Deployment and Inference is highly flexible users can deploy models to the cloud with scalable APIs or directly to edge devices such as mobile phones, embedded systems, and IoT hardware. Roboflow supports real-time inference that make it suitable for live video analytics and interactive applications. Post-deployment, the platform offers model monitoring to track performance and detect model drift, ensuring reliability and accuracy in production environments.
- Roboflow Workflows is a low-code, visual pipeline builder within its web platform. It allows users to create computer vision applications by simply dragging and connecting pre-built blocks such as models, logic components, and external APIs. Once the pipeline is assembled, the application can be deployed as a hosted API, run on a dedicated cloud server, or self-hosted on edge devices or local servers using Roboflow Inference.
Roboflow empowers developers with an intuitive, end‑to‑end computer vision workflow from dataset creation and annotation to training and edge or cloud deployment, making CV accessible even for everyone and rapid prototyping use cases.
2. Google Cloud Vision AI and Vertex AI
Google Cloud offers a comprehensive suite of computer vision services through Google Cloud Vision and Vertex AI Vision. Building on Google's decades of research in computer vision and machine learning, these services provide both pre-trained models and custom model development capabilities. Google's computer vision offerings are integrated into the broader Google Cloud ecosystem, providing seamless access to Google's AI research and infrastructure.
Google's approach to computer vision is centered around making AI accessible and scalable for businesses of all sizes. They provide both ready-to-use APIs for common vision tasks and advanced platforms for custom model development, all backed by Google's world-class AI research and infrastructure. The key services and tools are:
- Google Cloud Vision API provides powerful image content analysis tools. It supports object detection, scene understanding, text extraction via Optical Character Recognition (OCR) with multi-language support, and facial attribute detection (excluding facial recognition). It can identify brand logos, famous landmarks, and even detect explicit content using Safe Search. Additionally, it includes web detection capabilities to find similar images online and recognize web entities associated with the image.
- Video Intelligence API enables detailed video content analysis, allowing detection of objects, scenes, and human actions across frames. It supports shot change detection, object tracking throughout a video sequence, and extraction of text embedded in video frames. The API also includes content moderation features, making it suitable for compliance and safety checks in video datasets.
- Vertex AI Vision Platform is an end-to-end development environment designed for building and deploying computer vision models. It includes AutoML Vision for automated image classification and object detection, and also supports fully custom model training using TensorFlow, PyTorch, and other frameworks. Vertex AI offers a centralized model registry, experiment tracking tools, and robust version management for continuous improvement of models.
- Specialized Vision Services offered by Google Cloud include Visual Inspection AI for automated defect detection in manufacturing, Document AI for structured data extraction from forms and documents, Product Search for visual-based e-commerce recommendations, and Contact Center AI for integrating visual inputs into customer support solutions.
- Advanced Features of Google Cloud’s vision stack support multimodal AI use cases that combine vision with text or audio, as well as real-time inference for low-latency applications and batch processing for large datasets. Edge deployment capabilities are also available for running models on mobile and IoT devices.
- Development and Integration Tools include a suite of SDKs, REST APIs, and client libraries across major programming languages. Developers can use Jupyter Notebooks for experimentation and leverage MLOps tools for continuous integration, deployment, and monitoring of vision models across the ML lifecycle.
Google’s Vision APIs and Vertex AI Vision platform offer seamless integration of pre-trained vision capabilities, flexible custom model training, and scalable deployment, backed by enterprise-grade tooling and real-time/hybrid processing features.
3. Amazon Web Services (AWS)
Amazon Web Services provides a comprehensive suite of computer vision services through Amazon Rekognition, Amazon SageMaker, and other specialized services. AWS focuses on providing scalable, reliable, and cost-effective computer vision services that integrate seamlessly with the broader AWS ecosystem. Their approach emphasizes ease of use for developers while providing the flexibility and power needed for enterprise-scale applications.
- Amazon Rekognition provides robust image and video analysis capabilities. It supports object and scene detection in images, facial analysis with attributes such as age range, gender, and emotion, and facial recognition to identify specific individuals. The service also includes celebrity recognition, high-accuracy text detection from images, and unsafe content detection for moderation purposes. With Custom Labels, users can train specialized object detection models using their own datasets, enabling domain-specific applications.
- Amazon Rekognition Video extends these capabilities to video streams, allowing real-time and batch analysis of video content. It includes features like object detection, person tracking across frames, activity recognition, content moderation, and celebrity identification. Face search allows users to find and match faces within recorded or live video footage, making it ideal for surveillance, media, and security applications.
- Amazon SageMaker is a comprehensive platform for developing, training, deploying, and managing custom computer vision models. It includes Ground Truth, a high-quality data labeling service, along with support for distributed model training and scalable deployment with auto-scaling and endpoint management. SageMaker also provides tools for experiment tracking and managing the full machine learning lifecycle, from data preparation to production inference.
- Amazon Textract focuses on document understanding. It can extract printed and handwritten text, forms, and tables from documents with high accuracy. It also supports automated form processing, structured table extraction, and ID document parsing, making it useful in sectors like finance, healthcare, and government.
- Amazon Lookout for Vision is designed for industrial use cases, offering automated visual inspection capabilities. It detects product defects and anomalies, ensures quality control, and allows for real-time monitoring of production lines. Custom models can be trained for specific inspection tasks, and the system is optimized for rapid deployment in manufacturing environments.
- Specialized Services enhance AWS’s computer vision ecosystem. Amazon Lookout for Metrics enables anomaly detection in business metrics, while Amazon Monitron uses computer vision for equipment health monitoring. AWS Panorama allows edge-based computer vision deployment for on-premises analysis, and Amazon DeepLens offers a developer-centric smart camera for building and testing CV models.
- Advanced Capabilities include support for deploying models to edge devices, low-latency real-time inference, efficient batch processing, and full support for custom model development using popular ML frameworks. These features are tightly integrated with AWS’s MLOps tools, enabling seamless CI/CD and monitoring workflows.
- Integration and Development Tools include SDKs for multiple programming languages, REST APIs, the AWS Command Line Interface (CLI), and web-based management via the AWS Management Console. Additionally, CloudFormation allows users to manage and deploy infrastructure as code, ensuring repeatable and scalable deployments of computer vision solutions.
Amazon SageMaker, paired with Rekognition (for pretrained CV tasks), provides a unified, scalable environment supporting data labeling, training, deployment, and monitoring through AWS’s full-stack MLOps capabilities.
4. Microsoft Azure Computer Vision AI
Microsoft Azure AI Vision provides a comprehensive suite of computer vision services as part of the Azure AI services portfolio. Building on Microsoft's research in computer vision and AI, Azure AI Vision offers both pre-built cognitive services and custom model development capabilities, all integrated with the broader Microsoft ecosystem including Office 365, Power Platform, and Azure cloud services.
Microsoft's approach to computer vision emphasizes responsible AI development with strong ethics and privacy considerations. They focus on providing accessible AI services that can be easily integrated into existing business workflows while maintaining high standards for security, privacy, and compliance. The key features provided are:
- Azure AI Vision Service offers a broad suite of image analysis tools that detect and tag objects, generate descriptions, and extract text using powerful OCR capabilities. It supports multi-language printed and handwritten text recognition and includes face detection that respects privacy principles. For spatial understanding, Azure provides Spatial Analysis to monitor human movement and interactions in physical spaces ideal for retail or smart buildings. The Custom Vision service lets users train tailored image classifiers and object detectors, while Form Recognizer efficiently extracts structured data from scanned forms and documents.
- Advanced OCR Capabilities are available through the Read API, which delivers high-accuracy text recognition from both printed and cursive handwriting. It also enables layout extraction, multilingual support (100+ languages), and deeper document intelligence, pulling structured content like key-value pairs and tables. This makes it particularly useful for document-heavy industries such as finance, healthcare, and logistics.
- Custom Vision Service allows users to build their own image classification or object detection models using minimal data, with options to deploy trained models to edge devices. It includes support for domain-specific pre-trained models, such as those tailored for retail or manufacturing, and uses active learning to improve performance iteratively through feedback and retraining.
- Video Analysis capabilities are offered through Azure Video Indexer, which performs in-depth analysis of video content. It supports object tracking across frames, human activity recognition, content moderation, and can generate full transcripts from audio within video files. This service is valuable for media companies, surveillance systems, and automated video processing.
- Specialized Services such as Immersive Reader for enhancing text accessibility, Ink Recognizer for identifying handwriting and digital ink, Personalizer for delivering personalized content using visual data, and Anomaly Detector for identifying irregular patterns in visual streams.
- Advanced Features include multimodal embeddings that combine image and text features, and the Florence model, a state-of-the-art vision-language foundation model for high-performance multimodal tasks. Azure emphasizes responsible AI with built-in mechanisms to ensure fairness, privacy, and reliability. It also supports hybrid deployment, allowing models to run both in the cloud and on-premises.
- Azure Machine Learning Integration offers a seamless connection to Azure ML, where users can leverage AutoML Vision for automated model development, train custom models using frameworks like PyTorch and TensorFlow, and manage models through a robust lifecycle management system. It also supports experiment tracking and orchestration of complex pipelines for scalable computer vision workflows.
- Development and Integration Tools include SDKs and REST APIs for major languages, and integration with Power Platform tools like Power Apps and Power Automate for low-code/no-code CV applications. Workflow automation is possible through Logic Apps, and Azure Functions enable serverless execution of vision workloads.
Azure’s Computer Vision and AI services combine comprehensive image and document analysis with strong compliance capabilities, multimodal integration, and responsible AI tooling and offer both no-code experimentation and enterprise-ready deployment.
5. Scale AI
Scale AI is a leading data infrastructure company that provides high-quality training data for AI applications. Scale AI has become one of the most valuable AI companies. The company serves diverse clients including Meta, Amazon, and government agencies, providing data annotation and curation services that power large language models, generative AI, and computer vision applications.
Scale AI's mission is to accelerate the development of AI applications by providing the highest quality training data. They combine human expertise with AI-powered tools to create scalable data annotation solutions that meet the demanding requirements of modern AI systems. Scale AI provides following key services and tools:
- Scale AI’s Data Engine Platform delivers a comprehensive end-to-end data pipeline that encompasses data collection, annotation, and curation at scale. It is built to support massive datasets with high speed and consistency while maintaining quality through multi-layered quality assurance processes, including human-in-the-loop validation.
- Computer Vision Annotation Services include a wide range of annotation types bounding boxes for object detection, 3D data for applications like autonomous vehicles, semantic segmentation for pixel-level classification, and instance segmentation for separating individual object instances. Scale also provides keypoint annotation for human pose estimation and video annotation services for labeling across time, such as for object tracking and action recognition.
- AI-Powered Annotation Tools further enhance efficiency and accuracy through automation and intelligence. Pre-labeling uses AI models to generate initial annotations, which are refined by humans. Active learning intelligently selects the most informative samples for labeling, while consensus modeling combines multiple annotator inputs to ensure quality. Automated quality control algorithms further inspect and correct annotations to maintain consistency and precision.
- Data Curation and Management services help teams gather and prepare high-quality datasets. This includes data collection tailored to specific use cases, cleaning to remove errors, validation against project criteria, and optimization to ensure datasets are balanced for training robust machine learning models.
- Advanced Capabilities of Scale AI extend to multimodal annotation, supporting not just images and video but also text and audio. The platform offers real-time annotation for time-sensitive applications, custom taxonomy development for projects requiring specialized label schemas, and enterprise-grade compliance and security backed by SOC 2 Type II certification and robust data governance infrastructure.
Scale AI leads in high‑precision, large‑scale annotation and dataset curation workflows. Its robust quality control and scalable infrastructure make it a go-to choice for mission-critical and safety‑sensitive computer vision models.
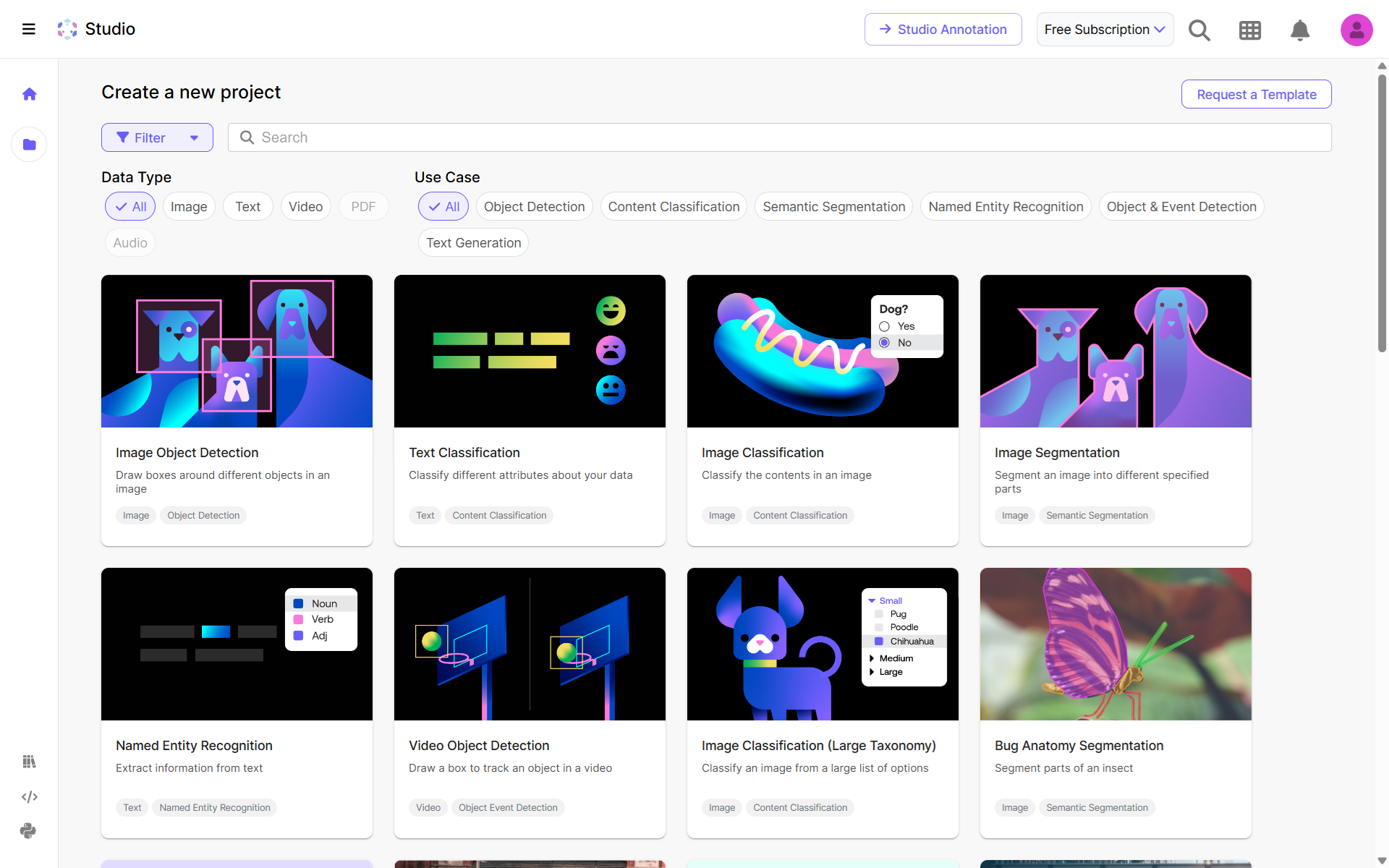
Getting Started with Object Detection on Top Vision Platforms
In this section, we explore how to quickly run object detection with bounding boxes using Roboflow, Google Vision AI (Vertex AI), Amazon SageMaker, and Microsoft Azure AI Vision, each with a concise step-by-step approach.
1. How to use Roboflow for object detection
Begin by creating a free Roboflow account and uploading your object detection dataset. Annotate bounding boxes using the intuitive labeling interface, then click “Custom Train” to let the platform train a model using COCO-pretrained weights. Once trained, you can instantly test the detector on images within the platform or deploy it via their hosted API. Visualize predictions and bounding boxes directly in the web interface or through Roboflow Workflows for low‑code application building.
Now we will build a Roboflow Workflows application to perform object detection using the model you have trained in your Roboflow workspace. This low-code, visual pipeline enables accepting input images, running the detection model, and generating bounding boxes and labels as outputs.
Step #1: Create a New Workflow
Log into your Roboflow account, go to the Workflows tab in the sidebar, and click “Create Workflow” -> “Custom Workflow” to start an empty canvas for your application.
Step #2: Add Your Object Detection Model Block
Use the Object Detection Model block. Choose your trained model from your workspace or Roboflow Universe. Connect it to accept input images for inference.
Step #3: Add Visualizers
Insert a Bounding Box Visualizer block to draw prediction boxes on the image. Then, add a Label Visualizer to overlay class names or confidence scores. Connect appropriately (box visualizer -> label visualizer).
Step #4: Save and Preview
Save your Workflow. Use “Test Workflow” in the editor and drag in a test image to see the detection results, with boxes and labels rendered on the image.
Step #5: Deploy the Workflow
Click “Deploy” within the Workflows page. Choose your deployment type.
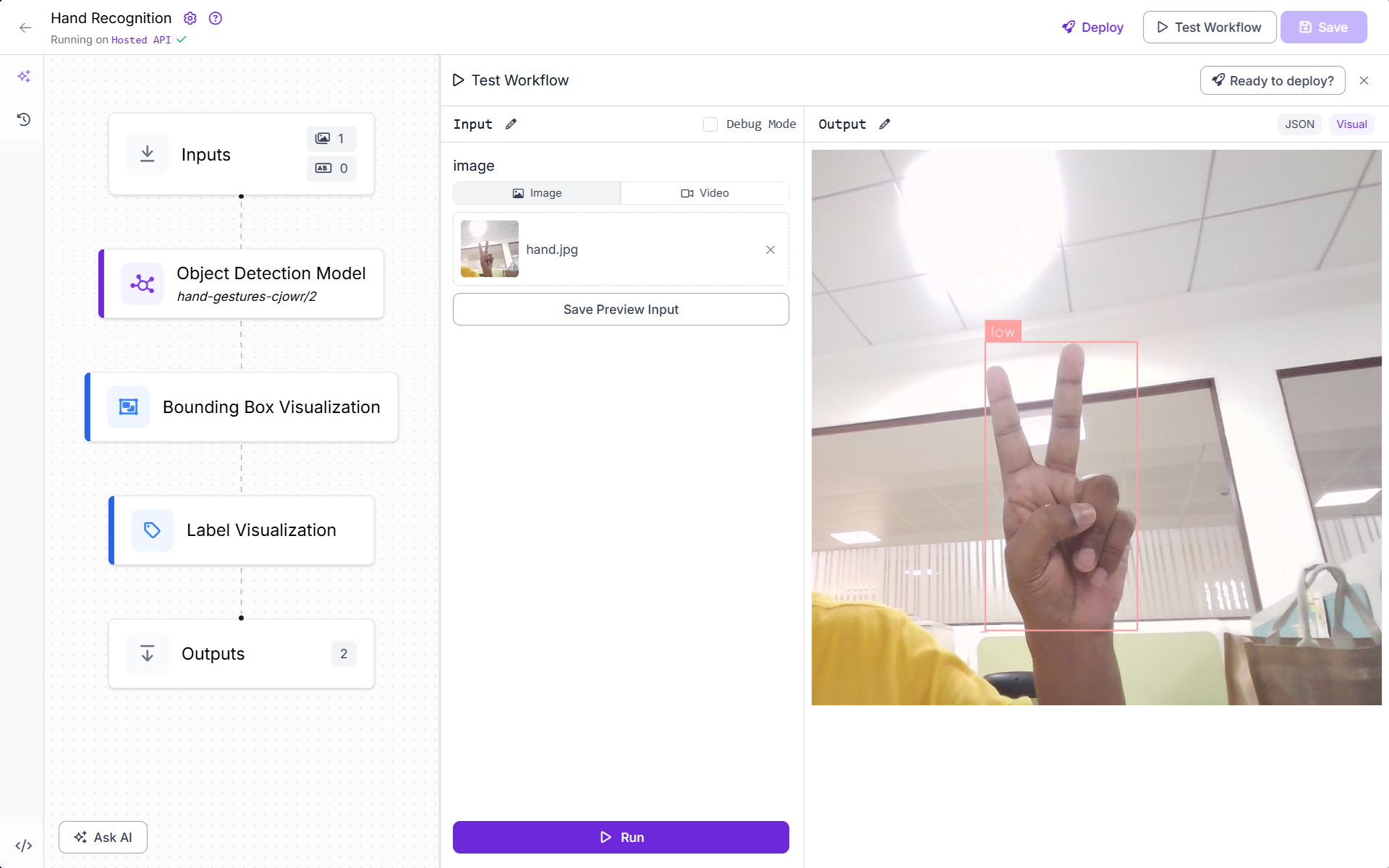
2. How to use Google Vision AI for object detection
In this example, we walk through how to create a Google Cloud project, enable the Vision API, and use the Python client library to perform object detection (object localization) on an image. You’ll load an image (e.g., parrot.png), submit it for localization, and receive object names along with their confidence scores and normalized bounding box vertices.
Step #1: Create a GCP Project & Enable Vision API
Go to the Google Cloud Console, select or create a new project. Enable billing for the project. Enable the Cloud Vision API via APIs & Services ->Library -> Cloud Vision API → Enable.
Step #2: Install the Vision Client Library
Install the library in your environment. I am using Google Colab Notebook.
!pip install google-cloud-visionThis installs the SDK needed to call the Vision API from Python.
Step #3: Use Python to Perform Object Localization
First authenticate the project that you have created.
from google.colab import auth
auth.authenticate_user(project_id='<YOUR_PROJECT_ID>')
And then use the code below to perform inference.
from google.cloud import vision
from PIL import Image
import numpy as np
import cv2
import os
# Initialize Vision client
client = vision.ImageAnnotatorClient()
# Load local image bytes
image_path = 'baseball.png'
with open(image_path, 'rb') as f:
content = f.read()
# Send image for object localization
image = vision.Image(content=content)
response = client.object_localization(image=image)
objects = response.localized_object_annotations
# Load image with OpenCV to draw on
cv_img = cv2.imread(image_path)
height, width = cv_img.shape[:2]
# For each detected object, compute pixel bounding box and annotate
for obj in objects:
# Convert normalized vertices to pixel coords
pixels = [
(int(v.x * width), int(v.y * height))
for v in obj.bounding_poly.normalized_vertices
]
# Derive xmin, ymin, xmax, ymax
xs = [p[0] for p in pixels]
ys = [p[1] for p in pixels]
xmin, ymin = min(xs), min(ys)
xmax, ymax = max(xs), max(ys)
# Draw the bounding box
cv2.rectangle(cv_img, (xmin, ymin), (xmax, ymax), color=(0, 0, 255), thickness=2)
# Overlay label and confidence
label = f"{obj.name} {obj.score:.2f}"
cv2.putText(cv_img, label, (xmin, ymin - 10),
fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.6,
color=(0, 255, 0), thickness=2)
# Convert to RGB and show in notebook
cv_rgb = cv2.cvtColor(cv_img, cv2.COLOR_BGR2RGB)
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
plt.imshow(cv_rgb)
plt.axis('off')
plt.title('Detected Objects with Bounding Boxes')
plt.show()
This above code:
- Load and send the image for
object_localization()to retrieve detected objects. - Each object contains
.bounding_poly.normalized_vertices, normalized (0–1) coordinates for the box’s four corners. - Multiply normalized values by image width and height to get actual pixel coordinates. Use OpenCV to draw rectangles and labels onto the image.
- Display final visual output using matplotlib.
You should see output as following.
3. How to use AWS Sagemaker for object detection
In this example, we'll show you how to use Amazon Rekognition to perform object detection with bounding boxes directly from a SageMaker Studio notebook without training any model. Leveraging SageMaker’s notebook interface, you can call Rekognition’s pre-trained detection APIs (rekognition.detect_labels(...)) to identify objects in images, retrieve bounding box coordinates, and visualize the results all within a fully managed Python environment. This approach is ideal for rapid prototyping or building lightweight vision services without setting up or training custom models.
Step #1: Sign In to AWS Console
- Go to https://aws.amazon.com
- Log in to the AWS Management Console with your account.
Step #2: Setup Sagemaker
Search “Amazon SageMaker AI”. Go To Amazon Sagemaker Studio -> Sagemaker Domain -> Create a Sagemaker Domain.

Then choose Setup Single User. This will setup everything for you.
Once Studio is ready, click "Open Studio" .
On left click Jupyter Lab and setup Jupyter Lab. This will show up following screen.
Step #3: Write Code
Open Jupyter Lab notebook and start writing code in the notebook. Here we will use Boto3 AWS SDK for Python, allowing developers to interact with Amazon Web Services (AWS) resources and services using Python code. It enables the creation, configuration, and management of various AWS services like S3, EC2, DynamoDB, and more.
Install the required libraries.
!pip install boto3 –quiet
!pip install opencv-python-headless
Import libraries.
import boto3
import cv2
import numpy as np
import matplotlib.pyplot as plt
Get region and bucket information to be used in code.
# Initialize S3 client
s3 = boto3.client('s3')
# Fetch all buckets in your AWS account
buckets_response = s3.list_buckets()
for bucket in buckets_response['Buckets']:
name = bucket['Name']
# Retrieve the region for each bucket
loc = s3.get_bucket_location(Bucket=name)['LocationConstraint']
# AWS returns None for us-east-1 region
region = loc
print(f"Bucket: {name}\tRegion: {region}")
Upload the image to Jupyter notebook and use the bucket and region information and upload the image to S3 bucket.
# Initialize S3 client
s3_client = boto3.client('s3')
# Local image path in SageMaker
local_path = 'soccer.png'
bucket_name = 'sagemaker-us-east-2-728951503109'
s3_key = 'soccer.png' # desired path in bucket
# Upload file
s3_client.upload_file(local_path, bucket_name, s3_key)
print(f"Uploaded {local_path} to s3://{bucket_name}/{s3_key}")
Finally run the rekognition to detect object and display bounding box.
# Initialize AWS clients
s3 = boto3.client('s3')
rek = boto3.client('rekognition', region_name='us-east-2')
# Specify your bucket and object key
bucket = 'sagemaker-us-east-2-728951503109'
key = 'soccer.png'
# Download image bytes from S3
response = s3.get_object(Bucket=bucket, Key=key)
image_bytes = response['Body'].read() # raw bytes
# Convert bytes to OpenCV image (numpy array)
np_arr = np.frombuffer(image_bytes, np.uint8)
image = cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
height, width, _ = image.shape
# Call Rekognition API to detect labels
rek_resp = rek.detect_labels(
Image={'Bytes': image_bytes},
MaxLabels=10,
MinConfidence=70
)
# Draw bounding boxes for detected instances
for label in rek_resp['Labels']:
for inst in label.get('Instances', []):
bb = inst['BoundingBox']
left = int(bb['Left'] * width)
top = int(bb['Top'] * height)
w_box = int(bb['Width'] * width)
h_box = int(bb['Height'] * height)
cv2.rectangle(image, (left, top), (left + w_box, top + h_box), (0, 255, 0), 2)
cv2.putText(image, label['Name'], (left, top - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (36, 255, 12), 2)
# Convert BGR → RGB and display using matplotlib
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10, 8))
plt.imshow(image_rgb)
plt.axis('off')
plt.title('Detected Labels with Bounding Boxes')
plt.show()
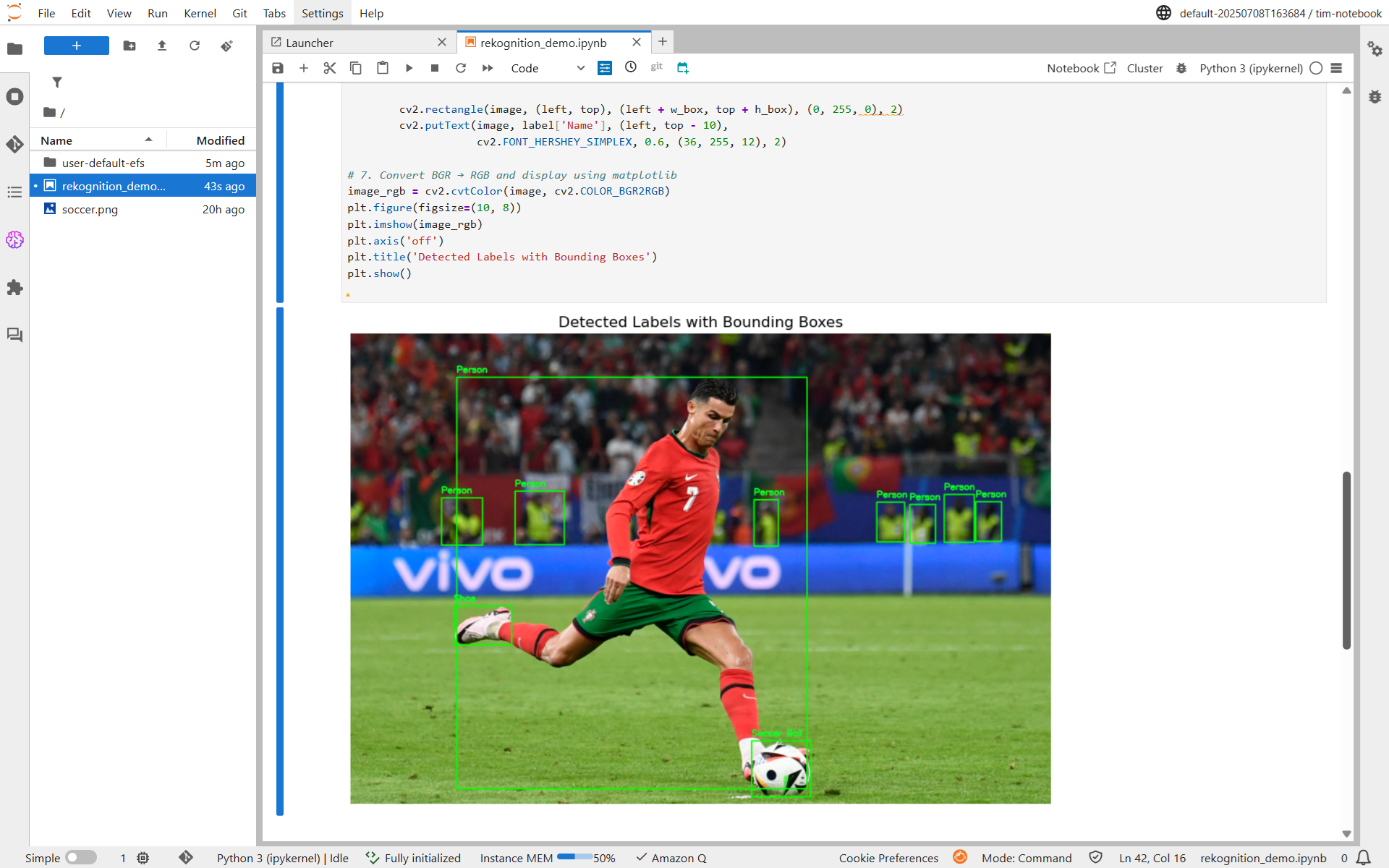
This code loads an image from an S3 bucket, converts it into a NumPy array using OpenCV, and then sends the raw bytes to Amazon Rekognition’s detect_labels API to recognize objects. For each detected object instance, it computes pixel-accurate bounding boxes by multiplying Rekognition’s normalized coordinates with the actual image dimensions (width and height), draws colored rectangles and labels onto the image using OpenCV, converts the image to RGB, and finally displays the annotated image inline using matplotlib. This visualizes the model’s predictions, object names and their locations, in your SageMaker notebook environment. You will see output similar to following.
4. How to use Azure AI for object detection
In this example, we'll show you how to use Azure AI Vision to perform object detection with bounding boxes directly from a Python notebook in Google Colab, without training any custom model. By leveraging Azure’s pre-trained `ImageAnalysis` API, you can automatically detect objects in local images, retrieve bounding box coordinates, and visualize the results using simple Python code. This approach is ideal for quickly building and testing computer vision applications
Step #1: Create an Azure AI Vision Resource
Sign in to the Azure Portal. Create a “Computer Vision” resource or “Azure AI” Services resource. After deployment, note the endpoint URL and an API key. You'll need these to connect your application.
Step #2: Install the library
Install the following library in Google Colab notebook.
!pip install azure-ai-vision-imageanalysisStep #3: Write the code
First import libraries and setup client.
from azure.ai.vision.imageanalysis import ImageAnalysisClient
from azure.ai.vision.imageanalysis.models import VisualFeatures
from azure.core.credentials import AzureKeyCredential
from PIL import Image, ImageDraw
endpoint = "<YOUR_ENDPOINT>"
key = "<YOUR_KEY>"
client = ImageAnalysisClient(endpoint, AzureKeyCredential(key))
Use the following code.
local_image_path = "baseball.png"
# Read image as bytes
with open(local_image_path, "rb") as f:
image_data = f.read()
# Call Azure analyze API with OBJECTS feature
result = client.analyze(
image_data=image_data,
visual_features=[VisualFeatures.OBJECTS]
)
# Open image and draw detection boxes
img = Image.open(local_image_path)
draw = ImageDraw.Draw(img)
# Convert dict_values to list
raw_objects = list(result.objects.values()) if result.objects else []
# If it's a nested list, flatten it
objects = raw_objects[0] if len(raw_objects) > 0 and isinstance(raw_objects[0], list) else raw_objects
# Draw boxes
if objects:
print("Detected objects:")
for obj in objects:
bbox = obj["boundingBox"]
tags = obj.get("tags", [])
name = tags[0]["name"] if tags else "unknown"
conf = tags[0]["confidence"] if tags else 0.0
x, y, w, h = bbox["x"], bbox["y"], bbox["w"], bbox["h"]
draw.rectangle([x, y, x + w, y + h], outline="red", width=2)
draw.text((x, y), f"{name} ({conf:.2f})", fill="red")
print(f" {name}: {conf:.2f}, bbox=[{x}, {y}, {w}, {h}]")
else:
print("No objects detected.")
# Show result
from IPython.display import display
display(img)
This code reads a local image (baseball.png) and uses Azure AI Vision’s pre-trained Image Analysis API to perform object detection. It sends the image bytes to the API, which returns a list of detected objects along with their bounding boxes and confidence scores. The code then opens the image using Pillow, draws red rectangles around each detected object, labels them with their class name and confidence score, and finally displays the annotated image within a Colab notebook. This provides a simple, end-to-end workflow for visualizing object detection results without training a custom model.

Types of Computer Vision Companies
Computer Vision companies operate across various industries, offering specialized solutions designed to specific needs. Following is a detailed list of CV companies categorized by industry, along with the services they provide.
Automotive & Autonomous Vehicles
These companies develop vision systems for self-driving cars, traffic management, and transportation safety. These companies offer one or more of the following services:
- Object detection and tracking
- Lane detection and navigation
- Traffic Signal and sign Recognition
- Pedestrian and cyclist detection
- Fleet management and monitoring
The following are the companies in this space that provide computer vision services.
Waymo is an autonomous driving technology company under Alphabet Inc., originally launched as the Google Self‑Driving Car Project in 2009 and became Waymo in December 2016. It now operates Waymo One, a commercial robotaxi service in multiple cities across the U.S. Waymo's core computer vision and perception capabilities stem from its proprietary Waymo Driver system, a tightly integrated sensor and AI stack.
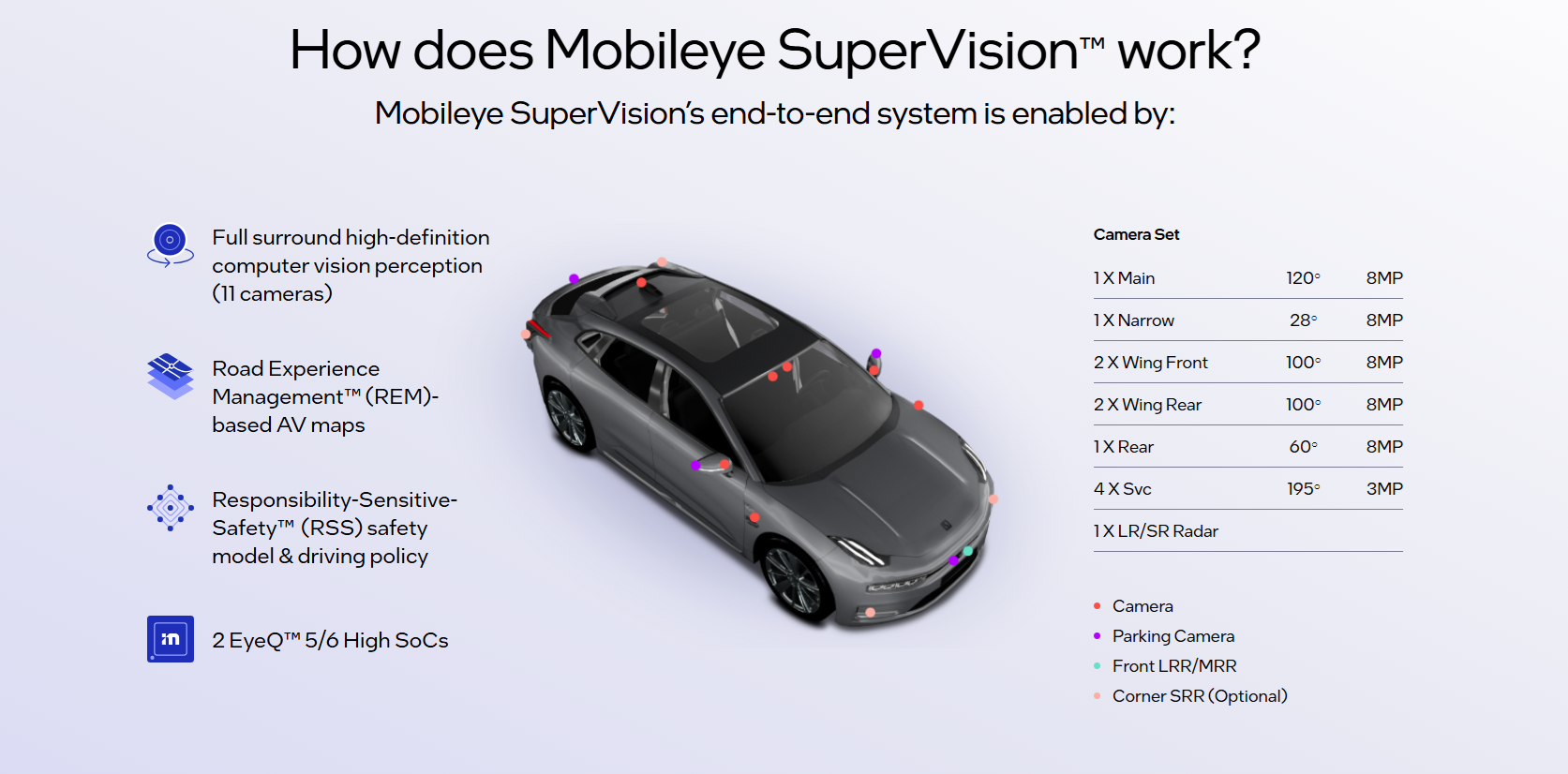
Mobileye Global Inc. is a leading computer vision and autonomous driving technology company, founded in 1999 in Israel and later acquired by Intel in 2017. It specializes in advanced driver assistance systems (ADAS) and full-stack autonomous mobility solutions.
Manufacturing and Industrial
These companies offer computer vision solutions for quality control, predictive maintenance, and automation in manufacturing environments. The services they offer are:
- Quality inspection and defect detection
- Predictive maintenance
- Assembly line automation
- Safety monitoring
- Process optimization
- Robotic vision for assembly lines
- Warehouse automation
The following are the companies in this space that provide computer vision services.
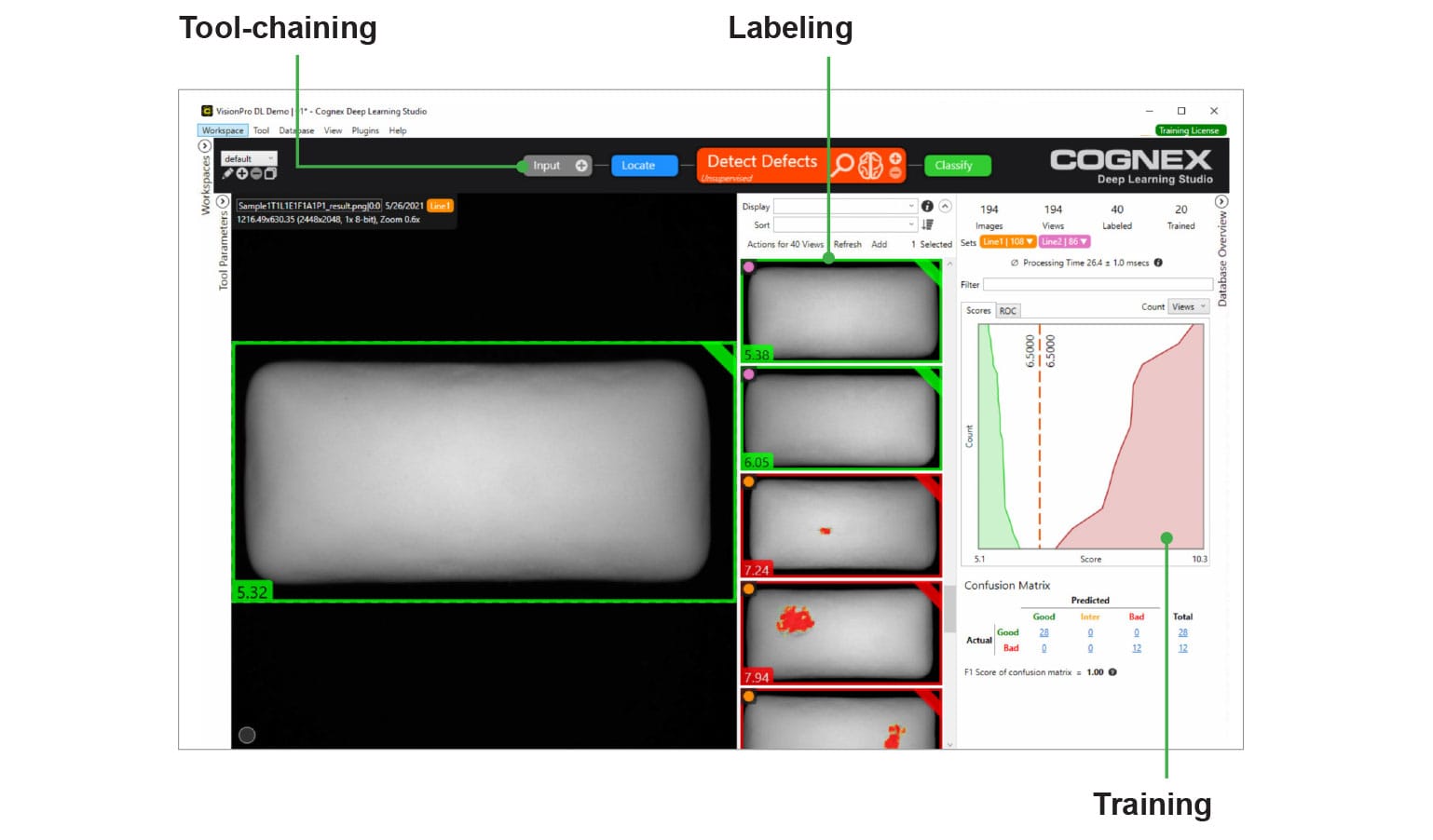
Cognex Corporation is a global leader in machine vision solutions, specializing in automation hardware and software for manufacturing and logistics operations. Cognex's products are used in diverse industrial settings for tasks like defect detection & quality control, presence/absence checks and verification, barcode/QC scanning and traceability in logistics and packaging, dimensioning & gauging, robotic guidance & assembly assistance etc. Cognex’s systems are widely deployed across sectors such as automotive, electronics, pharmaceuticals, food and beverage, and logistics operations in warehouses worldwide.
STEMMER IMAGING AG is a leading systems integrator and component supplier in industrial machine vision. It deliver both hardware and software (i.e. Common Vision Blox (CVB)) solutions including cameras, optics, lighting, image processing tools, and consulting services for industrial and non-industrial scenarios alike. STEMMER IMAGING’s solutions find wide adoption across manufacturing & automation (PCB inspection, part validation, robotic assembly), logistics & warehousing (parcel handling, quality control with line-scan cameras), food & pharmaceutical (product sorting, assembly line monitoring, contamination detection), sports & entertainment (player movement tracking, event replay analysis), smart Infrastructure & geospatial mapping etc.
Healthcare & Medical Imaging
Computer vision companies in healthcare focus on diagnostic imaging, medical device integration, and patient monitoring solutions. It offers services like:
- X-ray, MRI, and CT scan analysis
- Tumor detection & pathology automation
- Real-time surgical guidance
- Patient monitoring
The following are the companies in this space that provide computer vision services.
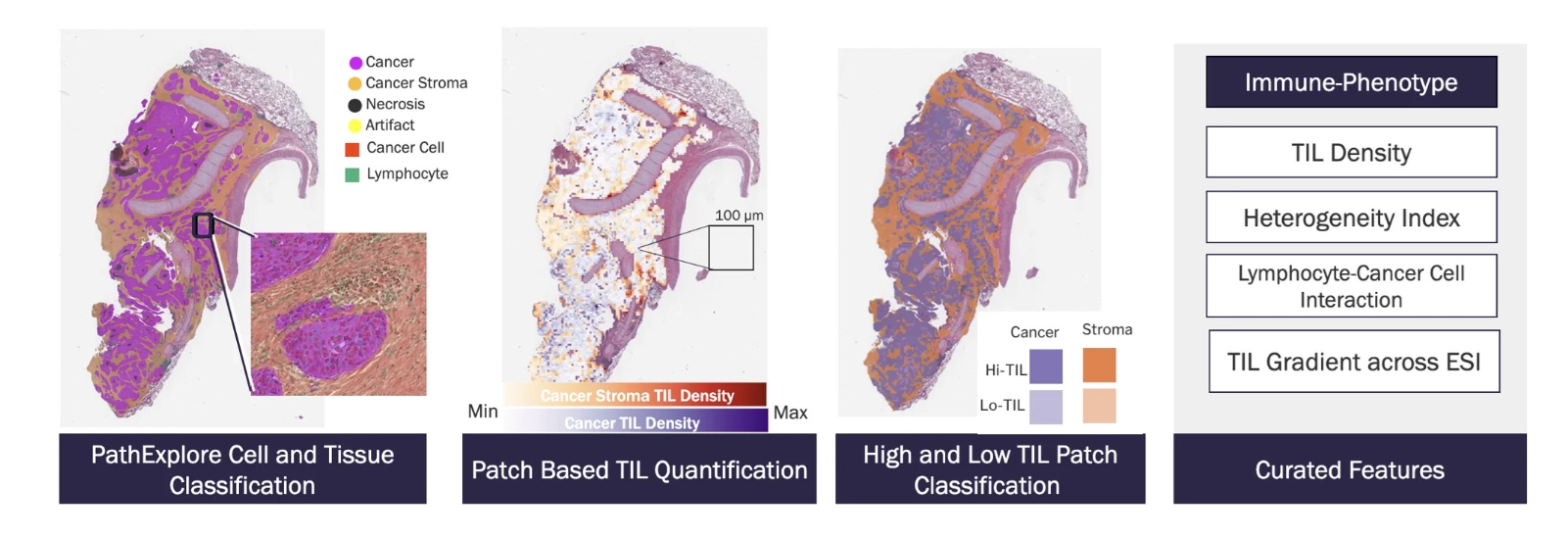
PathAI is a health-tech company founded in 2016 with the mission to improve patient outcomes using AI-powered pathology. It develops deep learning models to analyze digitized tissue slides (microscopic histology images) and collaborates closely with biopharma companies and clinical labs to accelerate drug development and enhance diagnostic workflows. PathAI offers a suite of AI tools within AISight designed for histopathology, including biomarker quantification (e.g. PD-L1, HER2), tumor detection and grading, tissue feature recognition and artifact detection etc.
Aidence offers clinically-certified AI tools that empower radiologists and pharma professionals to deliver faster and more precise diagnostics, especially in the context of lung cancer screening.
Retail & E-Commerce
These companies focus on enhancing shopping experiences, inventory management, and customer analytics. The services they offer are:
- Visual search and product discovery
- Inventory management
- Customer behavior analysis
- Cashierless checkout systems
- Product recommendation engines
The following are the companies in this space that provide computer vision services.
Standard AI builds computer vision systems to help physical retailers and consumer packaged goods (CPG) brands understand in-store shopper behavior, product interactions, and retail performance without using facial recognition technology. The company shifted its focus from autonomous checkout toward broader vision analytics in retail environments.
Trax Retail delivers AI‑powered in-store planning and execution solutions for consumer packaged goods companies and retailers worldwide. Its offerings blend computer vision, machine learning, mobile tools, and retail services to optimize shelf performance and drive sales through actionable insights. It is serving clients such as Coca‑Cola, Unilever, Procter & Gamble, and Nestlé, Trax operates in over 80 countries with global coverage in 45 markets.
Security & Surveillance
Computer vision companies specializing in security applications provide monitoring, threat detection, and access control solutions. It offers services such as:
- Facial recognition and authentication
- Anomaly detection
- Crowd monitoring
- Perimeter security
- Video analytics and forensics
The following are the companies in this space that provide computer vision services.
Oosto, formerly AnyVision, is a global computer vision company specializing in real-time video analytics, facial recognition, and behavioral detection solutions for enterprise and security use cases. It helps detect persons of interest in video streams for real-time intelligence and alerts, even in challenging conditions like poor lighting or crowds. It also offers action detection including gestures like fighting, falling, running, crouching, line crossing, and other nuanced behaviors for operational safety.
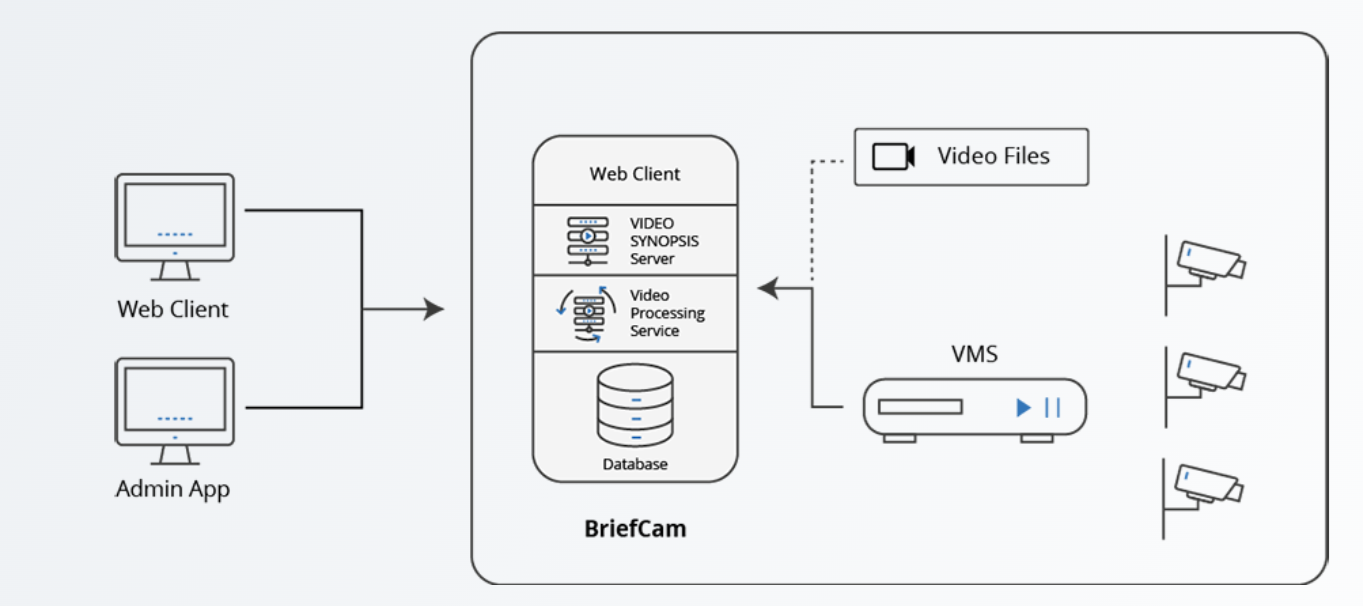
BriefCam is an enterprise-grade provider of video content analytics software, now part of Milestone Systems and Canon. It transforms video surveillance into actionable, searchable data using patented Video Synopsis® and deep learning technologies. It provides features such as Video Synopsis that condenses long video streams into brief, analyzable segments, multi-camera search, face & license plate recognition, face matching etc.
Agriculture & Food
These are the computer vision companies serving agriculture focus on crop monitoring, livestock management, and food safety. The common services provided are:
- Crop health monitoring
- Yield prediction
- Livestock tracking
- Food quality inspection
- Precision agriculture
- Pest & disease detection
The following are the companies in this space that provide computer vision services.
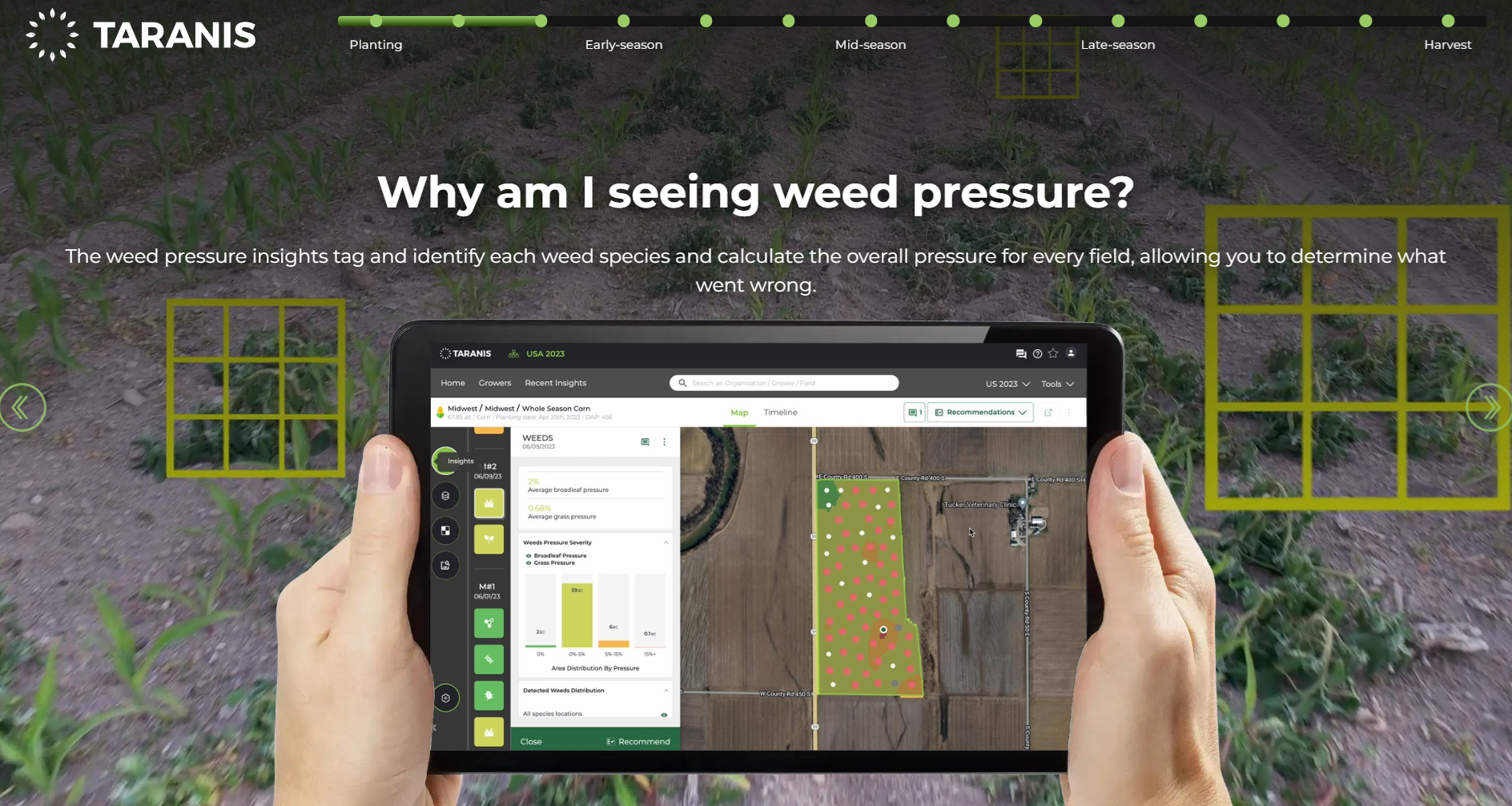
Taranis is an agri‑technology company provides AI-based crop intelligence solutions designed to help farmers and agronomists monitor and manage field health at scale down to the leaf level with submillimeter precision imaging analytics. Taranis provides intelligence platform that uses ultra‑high‑resolution aerial and satellite imagery to deliver leaf-level insights across entire fields. Their AI models trained on over 500 million data points, detect threats like weeds, pests, disease, or nutrient deficiencies and count plant emergence. The platform transforms raw image data into field-level prioritization, severity scoring, and expert agronomic recommendations via a user-friendly dashboard. With its full-service offering including capture, ingestion, analysis, and ROI tracking, Taranis empowers growers and agronomy advisors to act quickly and precisely across large-scale operations.
Blue River Technology (now part of John Deere) is an agricultural robotics company integrates computer vision, machine learning, and robotics to build intelligent farm machinery. Blue River core computer vision–driven technology See & Spray system uses high-speed cameras and AI to detect and differentiate weeds from crops in real time as the tractor moves through fields. Trained on over a million plant images, it enables precise herbicide spraying only where needed. This reduces chemical use by up to 77% and protects healthy crops. The system also supports advanced plant-level analytics for future applications like targeted fertilization and automated harvesting.

Computer Vision Platform and Tools Providers
These companies offer software tools, SDKs, low-code / no-code platforms, or developer support for building custom CV applications. The services they offer are:
- Data annotation and management
- Model training and deployment
- Application development
- API and SDK platforms
The following are the companies in this space that provide computer vision services.
Roboflow is a company and a software-as-a-service platform that enables developers to build, train, and deploy custom computer vision models at scale. Roboflow lets users upload and annotate images or videos, preprocess and export data in multiple formats. It enables one-click training for object detection, classification, keypoint and segmentation models, with detailed evaluation metrics. It helps to deploy models via APIs, edge devices, or custom servers. Roboflow also offers a low-code workflow builder for automating vision pipelines at scale.

OpenCV AI is a computer vision company that provides Computer Vision software and services and practical AI solutions for startups and Fortune500 companies. They maintains OpenCV (Open Source Computer Vision Library), a free, open-source software library offering a comprehensive collection of over 2,500 optimized computer vision and machine learning algorithms.
Get Started with the Best Computer Vision Companies
Computer vision is transforming how machines perceive and interact with the world, and the companies explored in this blog are leading that revolution. Whether you're building intelligent systems for healthcare, retail, agriculture, or autonomous vehicles or simply looking to prototype an AI application, these platforms offer robust tools to get started. By understanding their unique capabilities, you can choose the right solution to bring visual intelligence into your workflow and unlock the full potential of computer vision.
Start building your computer vision application using Roboflow for free today.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Jul 9, 2025). Best Computer Vision Companies. Roboflow Blog: https://blog.roboflow.com/computer-vision-companies/