
Should you deploy your model with via a web-hosted API? What about to an edge device like an NVIDIA Jetson or Luxonis OAK? How about onto a mobile device like iPhone or Android? What about running directly in the browser for realtime performance? These are all great questions.
In this guide, we're going to talk about the most commonly-used deployment methods for computer vision models. By the end of this guide, you'll be able to evaluate common deployment options. You'll also build the knowledge you need to understand under what circumstances different deployment methods make sense.
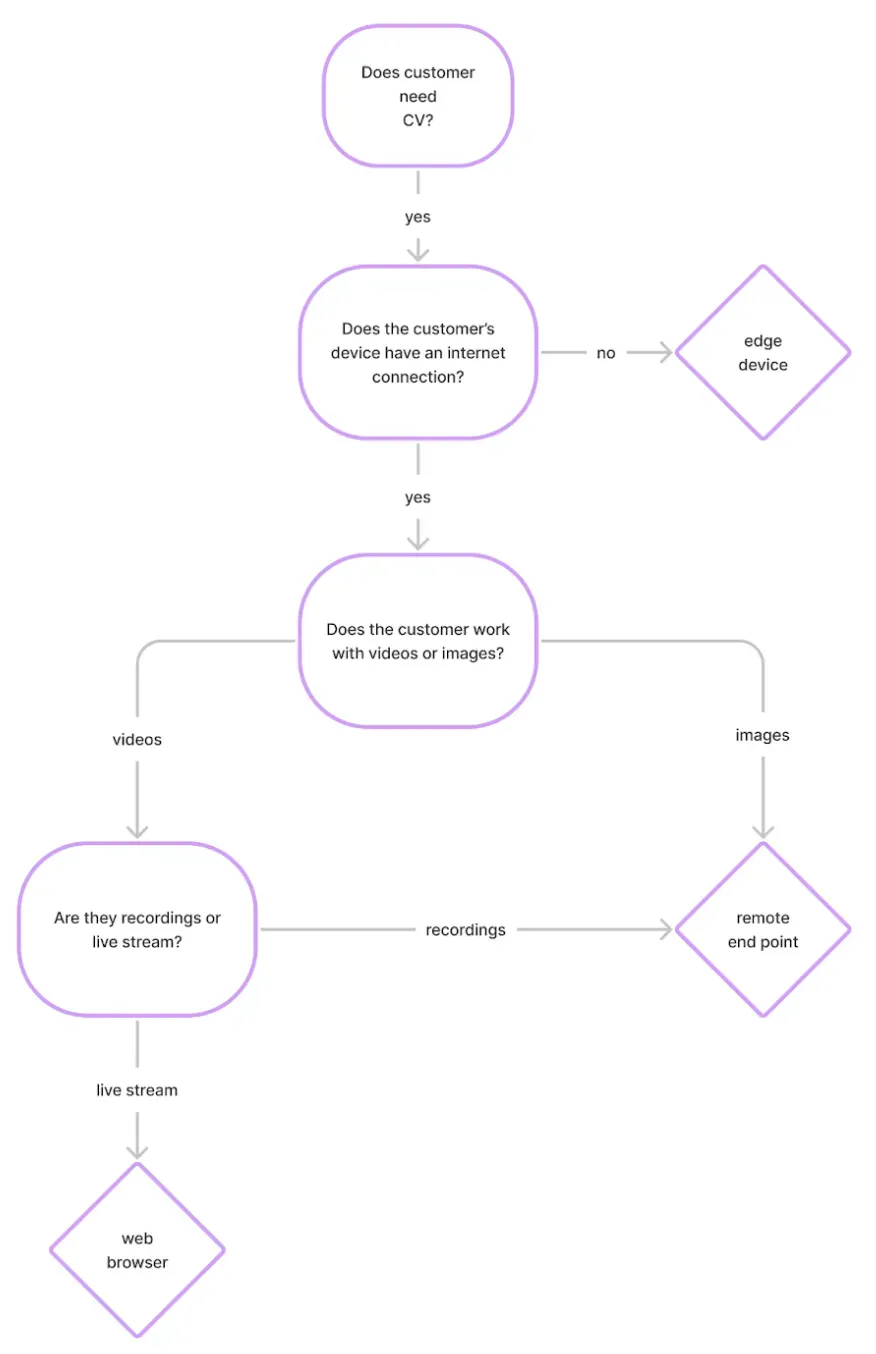
We have prepared a summary graphic you can use as a reference point as you read through this guide. We'll walk through each of the considerations – and terms – in the graphic below as we go through the article.
Learn more about Roboflow Inference.
Learn how to deploy your vision model with Inference.
Without further ado, let's get started!
So You're Ready to Use Computer Vision in Production?
You've figured out a way to use computer vision in your business, such as cleaning plastic from oceans, monitoring office capacity, or keeping stock of inventory.
You've also trained a model and it performs well enough to meet your business goals.
You need to get that computer vision model out into the wild and in front of customers, in your place of business, or wherever else a computer vision is needed.
Video explanation of deployment methods
Before breaking down the considerations that influence how to select a given deployment method, understanding which deployment options are available is key.
Model deployment means determining which compute resources a model is going to use to create inferences (predictions), and where those resources are located.
💡 When we say "deploy our computer vision model," we're answering the question, "what compute is going to power the model's inference."
Deployment is in the Cloud or on the Edge
Principally, deployment either lives in the cloud or at the edge. Cloud deployment means the model runs on a remote server and is called via an API. Edge deployment means the model runs on whichever edge device is in question and inferences are run directly on the device.
The cloud raises further considerations like identifying the power of an instance, setting up an API gateway, and handling load balancing. (Note: deploying a model with Roboflow's hosted inference API automatically handles autoscaling, is always available, and only charges per call rather than paying to have an instance always on.)
What is Edge Deployment in Computer Vision?
Edge deployment is when you deploy a model on the same device where inferences are made. This may include a custom-built device like a Luxonis OAK or an NVIDIA Jetson, or a web browser that is connected to a webcam on an embedded device. Edge deployment is commonly used in scenarios where internet connection is unstable or low latency is a priority.
Deploying to the edge raises considerations like which edge device, connecting to a host to post-process model inferences, and continuously handling model updates and improvements in low connectivity environments.
There are a number of edge devices worth considering for deployment, including:
- NVIDIA Jetson - A small GPU that has various memory levels (Nano, Xavier, AGX) available
- Raspberry Pi - A single-board computer commonly used for edge deployment.
- Luxonis OpenCV AI Kit - A device that has an embedded 4k camera as well as real-time processing capabilities and can do depth (requires a host device)
- A web browser - A model can run entirely in a user's browser, leveraging their local machine's compute resources without making any API calls after page load
- A mobile device - Run a model directly on an iOS device (iPhone / iPad) or Android (phone / tablet)
You can deploy models on CPU and GPU edge compute devices such as the NVIDIA Jetson and Raspberry Pi using Roboflow Inference.
Inference is a computer vision deployment solution that lets you run your models either as a microservice, or directly connected to your application code. With Inference, you can run state-of-the-art computer vision models like RF-DETR and CLIP on your hardware. You can run your models on images, webcam streams, and RTSP streams.
💡 Cloud deployment involves running a model on a remote server and accessing it via API. Edge deployment means running the model on a specific piece of hardware, often a small GPU or mobile device.
Cloud vs Edge Deployment
In many cases, an application could rely on either the cloud or an edge device for running its computer vision model. With that in mind, considering the strengths and weaknesses of each option is helpful in evaluating the best way to deploy your model.
Cloud Deployment Advantages and Disadvantages
The cloud's key advantage is the compute it can provide is nearly infinitely scalable and powerful. Many various instance types are available to scale up model processing power. A second advantage of the cloud is managing model (re)deployment can be simpler given the models are online and available for modification.
One disadvantage of the cloud is that because models are remotely accessible via API, there is latency in waiting for a given frame's result to be returned. It can also be complicated managing resource groups of instance types and expensive to have an always-on compute instance, especially if the model is not being constantly called.
Edge Deployment Advantages and Disadvantages
An edge device's notable advantage is eliminating latency. Because the model is running alongside the application itself, there is minimal delay in waiting model's processed results to be used in the business logic of the application. A second advantage of edge deployments is that the data run on them can be kept entirely private.
Edge devices are often more difficult to manage, which makes monitoring model health and updating model performance more challenging. With that said, Roboflow offers device management solutions you can use to monitor your deployments in production to ensure that your fleet of edge devices is running.
💡 Deploying to the cloud is often more scalable, easier to manage, and enables more powerful models to be used. Deploying to the edge reduces latency and supports better data privacy.
Now that we have a sense of given deployment targets, we'll take a look at considerations that help evaluate which one(s) we should use based on our circumstances.
Picking the Right Deployment Method Depends on Your Use Case
Determining which deployment method you should use for your computer vision model depends on factors related to your application. Analyzing real-time video feeds for production anomalies in a factory has a very different needs than an online art marketplace that is looking to automatically classify art styles.
💡 How you deploy your computer vision model depends more on your product's business logic than the machine learning it's using.
With that in mind, there's a few key factors that will help inform which deployment method is best for you:
- Do you need real-time (in excess of 30 frames per second) action?
- Will your application have consistent internet connectivity?
- Are you working with video or individual images?
Do you need real time and immediate results?
If your application is analyzing a video feed for immediate action, it requires real-time processing. Many monitoring systems may meet this requirement: shutdown a factory line if a given widget looks defective; send an instant alert if a leak is detected; track and report live the speed of tennis ball visible in frame.
With this context in mind, a few general recommendations surface:
- If the use case requires real-time processing and immediate action based on that processing, deploying to the edge is likely best because there's a key need to reduce latency.
- If the use case does not require real-time processing, deploying to the cloud is often simpler. Other considerations, discussed below, may influence.
- If near real-time solves the use case, deploying to the cloud or the edge is likely acceptable. Similarly, other considerations, discussed below, may influence.
If you need to process video streams in real time, we recommend using a powerful NVIDIA Jetson, or deploying your model on a GPU-enabled server. If you deploy your model on a server, you can connect to any camera in your facility on an RTSP stream. You can then run inference on your server, rather than on the same device that is recording video.
Note that processing video and requiring real-time processing of video are distinct. For example, imagine you have an application that needs to report the number of people that visited a store each day. This application could record video footage of the store for a full working day. Overnight, this video could be processed by a computer vision model to count people and report that count to another system. Because the count of people does not need to be maintained in real-time, the video also does not need to be processed in real-time.
In many circumstances, near-real time is sufficient for real-time. For example, imagine building an application that captures video of a parking lot and reports which parking spaces are empty. Processing this video in real-time (30 frames per second) would mean checking if a parking space is empty once every 33 milliseconds (for comparison, a blink lasts roughly 100 milliseconds). This application could likely check if parking spaces are empty once every five seconds and deliver its business value.
💡 If your use case requires real-time processing and immediate action based on that processing, deploying to an edge device is likely best. In most other cases, the cloud is simpler.
Will your application have consistent internet connectivity?
Internet access for your computer vision application is highly dependent on the use case. Building a computer vision model that automatically classifies a used car for a classic car marketplace is vastly different than building a computer vision model that identifies weeds from crops out in the field. An online marketplace implicitly always has internet; a tractor in rural Iowa may not.
There is a less clear middle ground. Some applications may collect data in a completely offline way, but only need to process that information when there is internet connectivity. Imagine an insurance business that identifies damaged roofs from drone footage. This business could capture all overhead video without internet and then process the video when they're back at the office with internet.
Thus, the question of internet connectivity is dependent on if the application needs to make decisions without internet.
This makes the recommendations for how to deploy based on internet connectivity are fairly straightforward.
- If the use case has steady internet access (like a web application using computer vision), deploying via cloud API is likely best.
- If the use case does not have any internet access and requires making actionable decisions without internet (like a robot operating in a rural field spraying herbicide only on weeds), deploying via the edge is likely best.
- If the use case collects image/video data without internet but does not need to immediately process that data, deploying the model via either the cloud or edge is subtable. (The cloud may be simpler to avoid purchasing a dedicated edge device.)
💡 If your use case does not ever have internet, deploying to the edge is likely best. In most other cases, the cloud is simpler.
Are you working with video or individual images?
Applications that are processing video have different considerations than those that are processing individual images. Video, at its core, is simply a high number of images processed together.
Once you understand the limitations of your system in terms of data type and internet connectivity–selecting the correct deployment method becomes a simple decision. If you're using Roboflow Deploy, we have built in options to deploy your model quickly to the cloud, the edge, or the browser – try it for free.
What type of data do you work with?
The data you work with will greatly influence how you deploy your model. For example, working with a real-time data stream from video cameras will have a different process than a mobile app which allows users to upload individual photos.
The types of data you may be working with:
- Images
- Recorded Video
- Live stream video
Does your device have an internet connection?
How your device communicates with the cloud will also influence where you can deploy your model to. A server filled with terabytes of data but access to the internet can send data to a remote endpoint for computer vision results, while an offline camera which uploads images once every two weeks when getting serviced.
The types of connections you may have:
- Online capabilities
- No internet connection (i.e. offline)
Examples
Live stream video data with an internet connection
You can process live stream video using Roboflow Inference. You can connect to an RTSP stream to run inference on camera frames.
You can also use a web browser plug-in to leverage Roboflow's tfJS-based web camera deployment method live from any device with a browser! This can range from streaming via a platform such as Twitch, to your own mobile application.
Recorded video data with an internet connection
If you have a large storage of recordings and you don't need to support real-time inference–the remote endpoint would be the best pick for you. Roboflow makes it easy to add video to your dataset.
Roboflow offers a Video Inference API with which you can process videos in bulk. This API accepts videos and returns predictions from a model you have fine-tuned, or a foundation model. This API scales to your requirements: whether you have 10 or a thousand videos, the API will reliably process your video with your chosen computer vision models.
Single images with no internet connection
If you need to perform inference on images periodically out in the wild without an internet connection, you'll need a device that has a computer vision model loaded into it such as an NVIDIA Jetson and Raspberry Pi. Images with bounding boxes can be stored directly on the edge device, or the edge device can be used as a controller to send signals to other devices in the field it's paired with.
Conclusion
How you are going to deploy your computer vision model is an essential question. With so many options, it can be difficult to make a decision.
If you need to run your model in real time, we recommend running your model on frames from video stream either using an edge compute device like the NVIDIA Jetson or a central, GPU-enabled server for processing vision predictions.
If you need to process pre-recorded video in bulk, we recommend the Roboflow Video Inference API.
If you need to process images, we recommend running your model on a server with the computational requirements you need. For a low-volume application, a CPU-enabled server will work. For applications that need to process hundreds of images a minute, a GPU-enabled server is essential.
Need help planning your vision deployment for an enterprise application? The Roboflow sales team are experts in architecting solutions to vision deployment tasks. Our sales team works closely with our best-in-class field engineering team to gather information and recommendations tailored to your use case. Contact the Roboflow sales team to learn more.
Cite this Post
Use the following entry to cite this post in your research:
Jay Lowe, Joseph Nelson. (Apr 2, 2022). How to Deploy Computer Vision Models: Best Practices. Roboflow Blog: https://blog.roboflow.com/deploy-computer-vision-models/