
This post walks through building a U.S. license plate detection model trained with Roboflow, achieving 94.9% mAP, 95.7% precision, and 90.4% recall on images collected from Google and Central Florida locations. The workflow covers annotation, preprocessing with auto-orient and resize, augmentations tuned for occlusion and motion blur, training with the Fast option, and publishing the finished dataset and model to Roboflow Universe for public use in applications like toll roads, drive-throughs, and law enforcement.
The newest project featured on Roboflow Universe is a U.S. License Plate dataset and model with images collected from Google images and around Central Florida parks.
This dataset and model can be used for cases like:
- Police work
- Toll roads
- Bank drive-throughs
- Fast food drive throughs
In this overview we will go over the steps taken to create this model prior to releasing it to Roboflow Universe and making it available to the public.
Uploading and Annotating Images
Annotations for the first few iterations of this dataset were fast and easy as we were only detecting one object, the license plate. Future annotations for other objects in this dataset could be implemented to detect objects like tags and state if we were using it for use cases like police work, toll roads, or bank drive-throughs.
Some fast food drive throughs like Chick-fil-A simply take down the license plate number to identify which customer to deliver an order to.
It would be useful to build alongside with an OCR API to extract text results returned in a JSON format for any of the mentioned cases.
Preprocessing and Augmentation
The v4 version of this dataset was preprocessed with the defaults:
- Auto-orient , to avoid one of the most common bugs in CV. I was also not interested in turning this off for speed optimization, and knew that this model may be used in different apps that may run on different devices where images may have different EXIF orientation
- Resize, so that all images in my dataset are the same size
The Augmentations used were:
- Crop, for better detection on occluded license plate officers might encounter while driving
- Rotation, in the case of accidents and for difficult to place camera locations
- Brightness, for camera setting and lighting changes
- Blur, (5px) for moving cameras (in police cars) and cars
- Noise, to prevent overfitting
Train
The latest model was trained using the Fast training option which was implemented for students and engineering professionals for proof of concept projects.
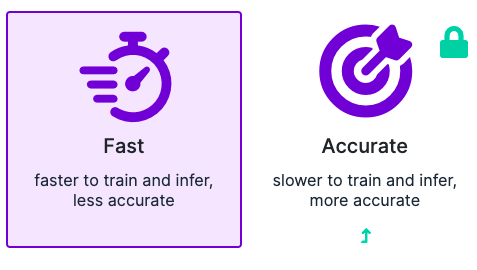
The result was an mAP of 94.9%, precision of 95.7%, and recall 90.4%
- Precision is a measure of, "when your model guesses, how often does it guess correctly?"
- Recall is a measure of, "has your model guessed every time that it should have guessed?"
- mAP (mean average precision) tell us at a glance the overall general performance of our model by combining precision and recall

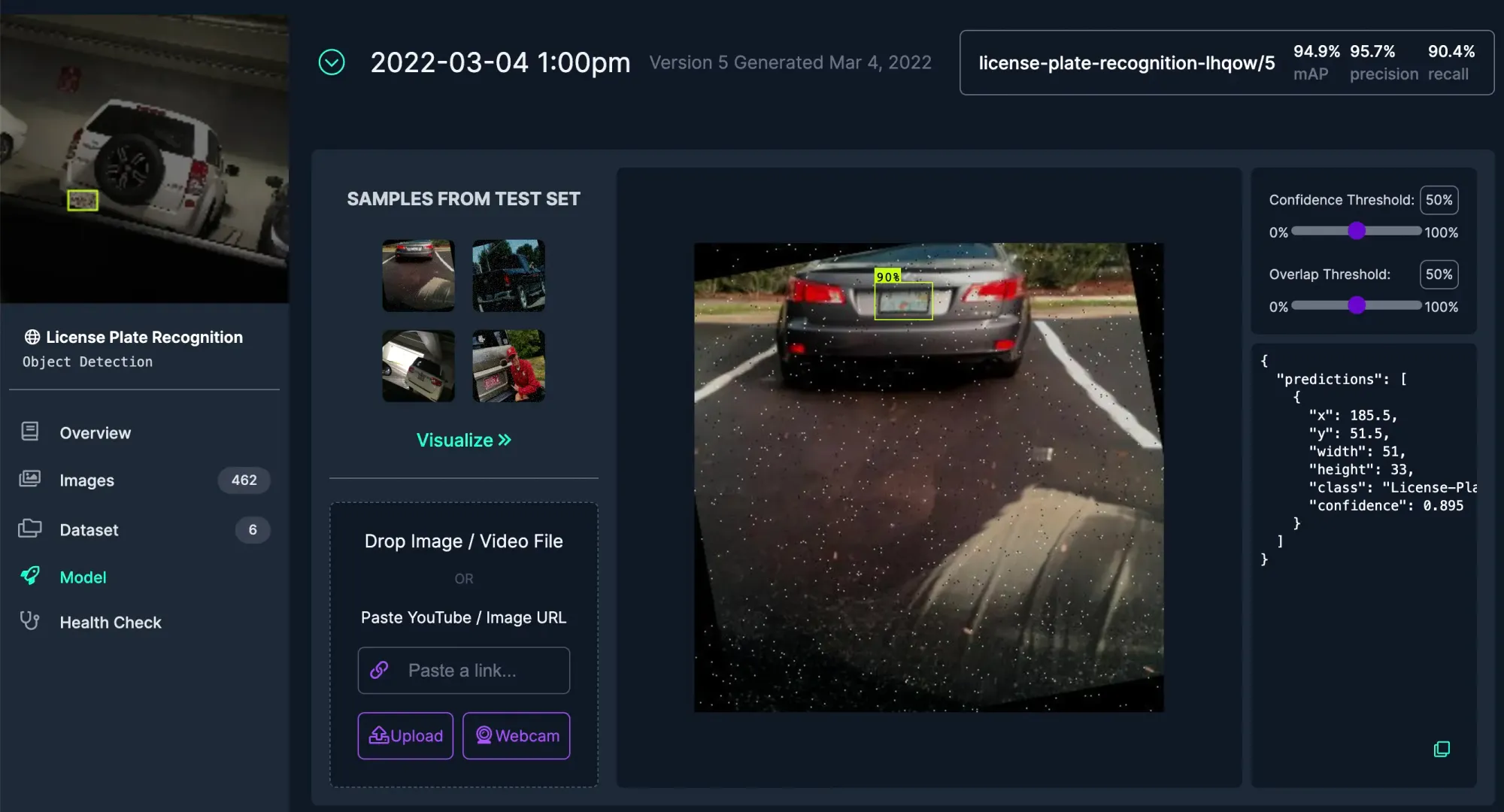
Deploy & Use
The test image on the example web app here was inferred at min confidence of 85%. Try it yourself!
Putting The Dataset And Model On Universe
Before I could share this project on Roboflow Universe, I had to make sure I complied with the guidelines below:
- Originality - For the most part, projects featured on Universe should be the user's own work or creation. Even though I did use some photos from another dataset, I made sure to only use photos from that project that was relevant to what I wanted to detect, which was U.S. license plates. I then of course added onto the data making it more of my own with pictures of cars and license plates from central florida parks. It was labeled in Roboflow.
- Non-Duplicate - I did not fork or copy this project to make it a duplicate.
- Good Workspace Name - My workspace name, “Objects in the Wild” is descriptive to the projects I post within it. The default is new-workspace-xxxx would not be descriptive or helpful to users.
- Good Project Name - Similarly, my project's name made sense to a general audience. It is descriptive, and does not contain the word "dataset" or "project" (Roboflow adds this automatically in some spots). The project name goes in the URL, is important for SEO, and is used in the API to access the project, so having a simple and relevant name is very high-value. Because names are permanent identifiers of models, they cannot be renamed directly. If a project needs to be renamed, it should be downloaded (raw) and re-uploaded.
- Good README - All projects highlighted on Universe should have a good readme that describes what the project is, what it can be used for, contains relevant links to more information or associated open source projects, blog posts, videos, industry pages, etc. Photos visualizing what the model can detect are a really nice touch! This is important both for users and SEO purposes. Think about what the ideal consumer of this project might be searching for and try to use those keywords so it is easily findable in search results. Industry terms can be especially useful.
- Useful Labels and Ontology - Think about how the model will be used by end-users. Are the objects annotated in the way we'd like for the model to predict them? Do the classes make sense? Sometimes users will need help thinking through this.
- Generated (Raw) Version - Users can only download generated versions of a dataset. At the very least, each project featured on Universe must contain one version generated with no augmentations (and likely only the "Auto-Orient" preprocessing option) or it will not be usable. Additional versions may also be included if needed, but every featured project should have a "raw" version.
- Trained Model - Ideally with high mAP performance. The vision for Universe is to be a source of hundreds of high-quality "off the shelf" computer vision APIs for particular use-cases. If a project has a trained model it can be used right away by end-users without having to go through the whole training process. Getting a good trained model oftentimes means experimenting with preprocessing and augmentation steps.
- License - All public projects must choose a license; older projects (or projects converted from private to public may be missing one). It's very important that users of Universe know whether they are able to legally use the data in their work.
- Has a Health Check - Health checks must be generated in the core app and then will show up in Universe. If the project has been modified substantially since the health check was first generated, click "Regenerate" at the bottom to update it.
Discuss & Share
We encourage you to build and add your dataset and models on Roboflow Universe! Be sure to follow the guidelines and contact our team at friends@roboflow.com to be featured!
As a next step, try this video tutorial:
Cite this Post
Use the following entry to cite this post in your research:
Kelly M.. (Mar 8, 2022). Building a U.S. License Plate Detection Model And Sharing It On Roboflow Universe. Roboflow Blog: https://blog.roboflow.com/license-plate-detection-model/