
Mountain Dew's Super Bowl LV ad challenged viewers to count the exact number of bottles in the commercial for a $1 million prize, and this post builds an object detection model to assist with that count. The 30-second video was sampled at three frames per second in Roboflow to produce 92 annotated training images, and the resulting model was used to catch bottles a human reviewer might otherwise miss across the densely packed scene.
Last night during Super Bowl LV, Mountain Dew ran an ad featuring John Cena riding through a Mountain Dew-themed amusement park. Bottles are scattered all over the scene: neon signs on buildings, in fun house mirrors, and flying out of the car trunk.
At the end of the ad, John Cena challenges the audience: The first person to tweet at Mountain Dew the exact number of bottles that appear in the commercial is eligible to win $1 million.
Watch the ad for yourself here:
Mountain Dew's Super Bowl 2021 ad.
When we heard that a task called for careful visual inspection and counting, we knew computer vision would be a helpful tool. So, we did what any developer would do: trained an object detection model to recognize bottles that appear throughout the scene.

In this case, we're using a computer vision model to help us find any bottles we may have otherwise missed. The viewer should still identify the unique occurrences of each bottle across the scene when tweeting a submission.
Per the Official Rules, any type of bottle counts – but each bottle should only be counted once. (For example, the bottle in the car John Cena drinks from is present multiple different times, but it should only be counted once towards the tally.)
Let's dive in.
Preparing a Dataset
First, we need a dataset of images from the ad. In this case, we can grab the exact video file of the commercial. We'll need to split the video file into individual image frames in order to annotate the images and train a model.
I created a dataset and dropped the Mountain Dew video into Roboflow, which asks what frame rate I'd like to sample. I decided on doing three frames per second, which creates 92 images from the roughly 30-second Super Bowl spot.
Having each of the individual frames from the video is independently helpful: it means we can have a closer look at all of the places where the Mountain Dew bottles may be present.
Once we have these images, we need to annotate all of the bottles we can find in each of the scenes. While this is fairly similar to counting all of the bottles manually, remember we might not be perfect in finding all of the bottles with our own eyes. So, hopefully, in teaching a computer vision model what bottles look like and then asking that same model to find bottles for us, we'll see any we may have missed.
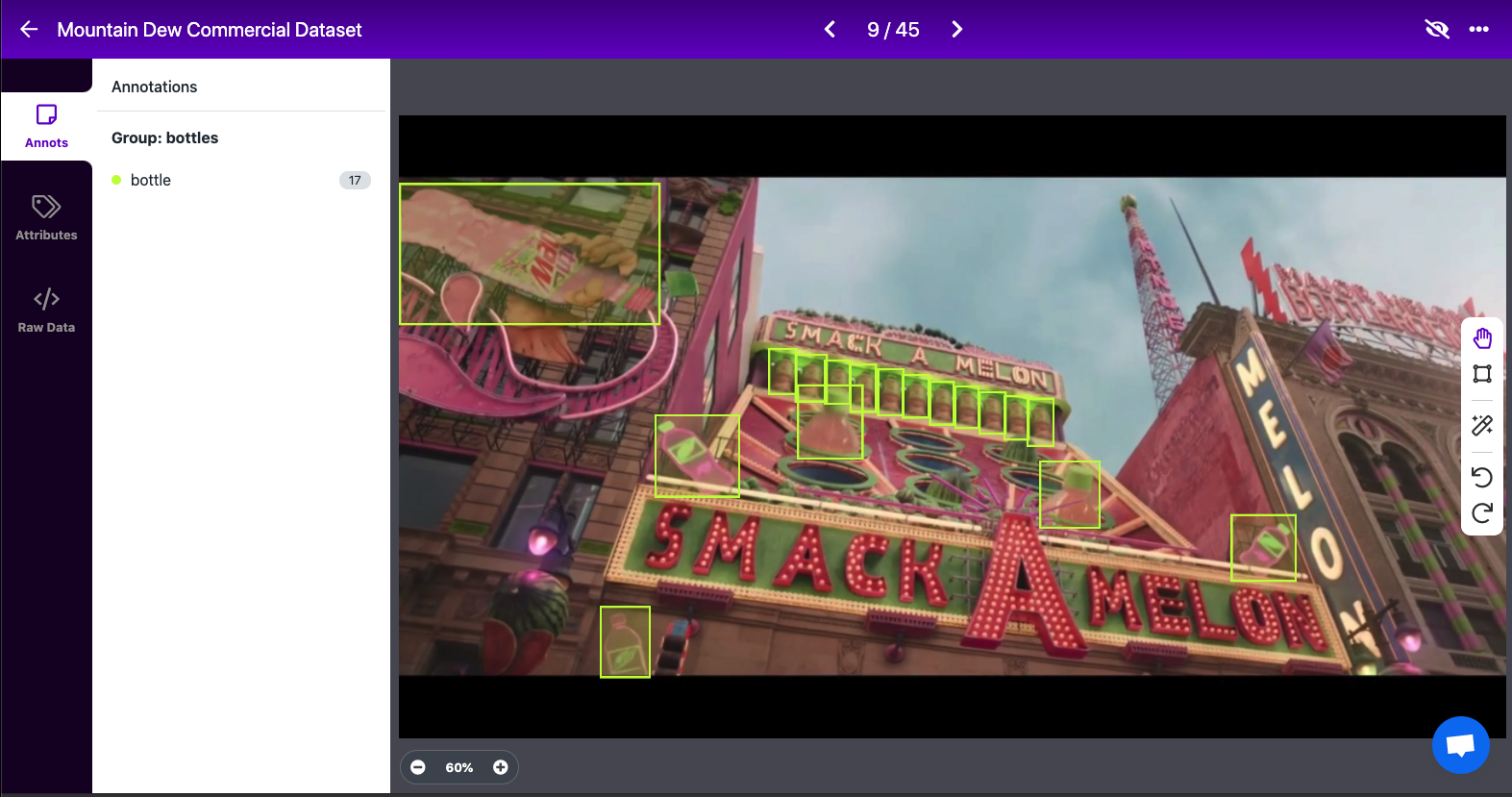
After labeling (and deleting one completely black image from the vid), we have 869 annotations across 91 images. We've open sourced this final Mountain Dew bottles image dataset:

Training an Object Detection Model
Once we have our images collected and labeled, we can train a model to find bottles for us. Before training, however, we can use image augmentation to increase the size of our training dataset.
By applying random distortions like brightness changes, perspective changes, flips, and more, we can increase the volume and variability of our training dataset so that our model has more examples to learn from.




Our augmented images have been brightened, sheared, flipped, rotated, and more to increase dataset size and variability.
We then made use of Roboflow Train, which gives us the option to one-click have a trained model available. Critically, when starting model training, we can start from a previous model checkpoint. This transfer learning will accelerate model training and improve model accuracy. For this dataset, starting training from the COCO Dataset (a dataset of "Common Objects in Context") will give the model a healthy head start.
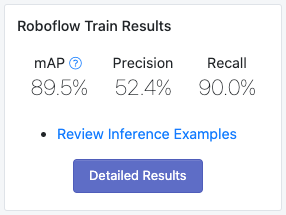
Using Our Model
Once the model finishes training, we have an API we can call to perform detections on our original video. With a little shell scripting, we can passthrough the original commercial video frame-by-frame and reconstruct the result with the bounding boxes present.
The result? See for yourself:
A full video walkthrough of our process. The resulting video is available at the 12:53 mark.
Good luck! We hope you win that $1 million.
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Feb 8, 2021). Using Computer Vision to Help Win $1 Million in Mountain Dew's Big Game Contest. Roboflow Blog: https://blog.roboflow.com/mountain-dew-contest-computer-vision/