
Designing a neural network is a challenging task, requiring mixing and matching layers, activation functions, and connection patterns until a winning combination is achieved. And today’s deep learning models are often massive image models with many layers, or language models with billions of parameters, making manually designing the perfect neural network architecture much more difficult.
Neural Architecture Search (NAS) has emerged as an answer to this challenge. NAS techniques treat neural‑network design as a machine‑learning problem. Rather than manually building a model architecture, an algorithm searches a space of candidate architecture, and automatically discovers a configuration that meets user‑defined objectives.
In this blog post, you’ll learn the following:
- What is NAS?
- The main components of NAS systems.
- How NAS works.
- The types of search spaces and strategies in NAS.
- Why NAS is useful.
So, let’s get started.
What Is Neural Architecture Search?
Neural architecture search is a technique for automating the design of artificial neural networks. It answers the question: What is the best model for my problem and my hardware?
Given a specific task (e.g., image classification, object detection, language modeling or image segmentation), a NAS algorithm searches over a pre‑defined space of possible neural‑network topologies to find an architecture that optimizes a performance metric such as accuracy, latency, or model size. There are 3 key components of NAS :
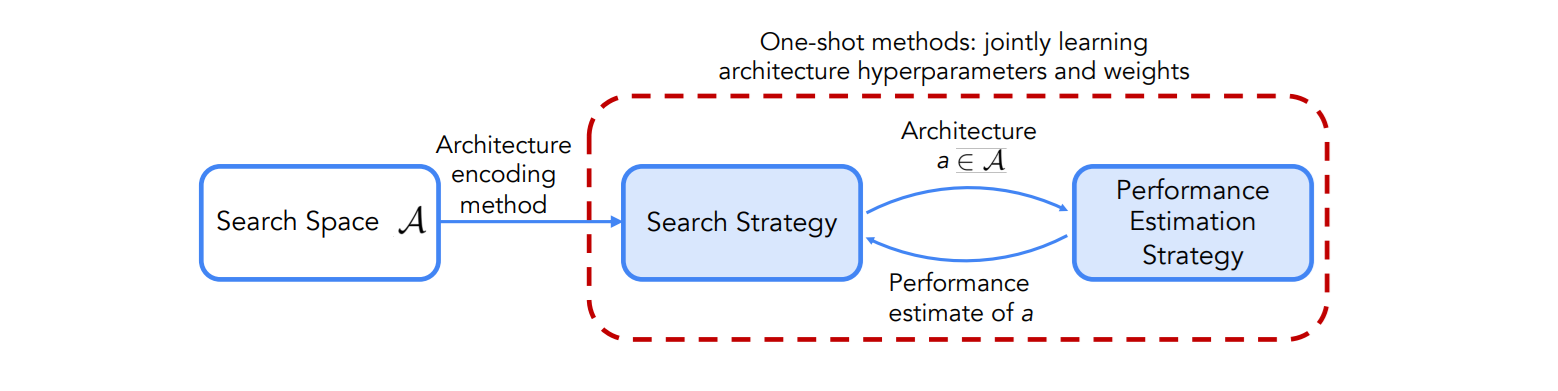
Search Space
The search space specifies the kinds of architectures that the algorithm may consider - it's what you are allowed to change. This includes allowable operations (such as convolution, pooling, attention layers, fully connected layers, and activation functions, etc.), how these operations can be combined, and hyper‑parameters such as kernel size or number of channels. How big is the input image? How many layers does the model have? How many object predictions does it make? How is attention applied? The search space may be global covering complete networks, or modular, where the algorithm learns reusable cells or blocks that can be stacked to build deeper models.
Search Strategy
The search strategy (or controller) is how you explore different options. It's an algorithm that proposes candidate architectures from the search space and updates its proposals based on feedback. Common strategies include randomly trying combinations, systematically testing a grid, or using modern methods that learn what works better.
Performance Estimation Strategy
Performance estimation is how you measure whether a configuration is good. You can train the model fully or partially, or reuse weights to save time. Specifically, performance estimation strategies speed up evaluation using proxy tasks (e.g., training on reduced datasets or fewer epochs), replacement or substitute models that predict a model’s performance from its structure, or weight‑sharing/one‑shot approaches that train a large supernetwork containing all possible operations and then evaluate different sub‑architectures using shared weights.
NAS benchmarks have been introduced to provide datasets and precomputed results that allow quick performance estimation and reduce the carbon footprint of NAS.
A supernetwork (or supernet) is a large, over-parameterized neural network that contains all possible architectures in the search space as subnetworks.
These three components: search space, search strategy and performance estimation, are the building blocks of any NAS framework. Next, we examine how NAS algorithms actually work by stepping through a typical NAS process, and surveying the most common search strategies.
How Does NAS Work?
A general NAS workflow can be summarized in following steps:
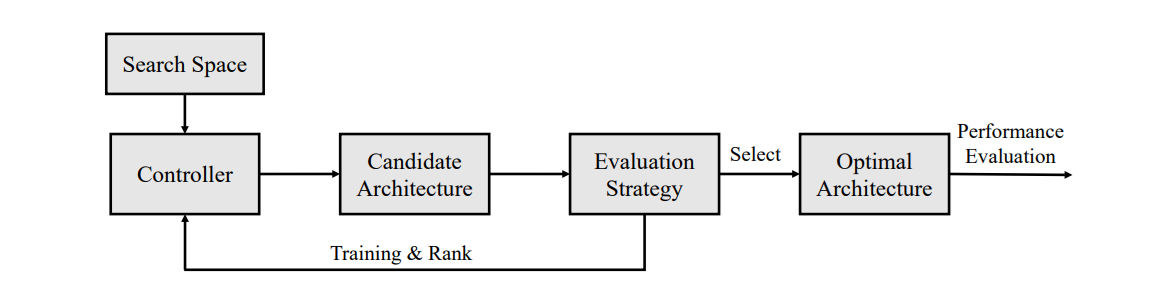
Step #1: Define the search space
In this step a set of operations (e.g., convolution, pooling, recurrent layers) and possible connections among them are decided. These operations form the building blocks for candidate architectures. The search space can be extremely large if it considers all possible layer combinations, so many NAS methods restrict the search to specific templates (such as cell‑based or hierarchical structures).
Step #2: Generate candidate architectures
A controller (the search strategy) proposes architectures from the search space. The controller might randomly sample, follow a policy learned by reinforcement learning, mutate existing architectures in an evolutionary loop, or adjust architecture parameters using gradients.
Step #3: Evaluate candidates
Each proposed architecture is partially or fully trained on a dataset. Its performance is then recorded on a validation set. To reduce cost, evaluation may involve training only a few epochs or using substitute models to estimate performance. In one‑shot approaches the architecture’s weights are inherited from a supernetwork rather than trained from scratch.
Step #4: Update the search strategy
The controller uses feedback from evaluated architectures to refine its search. In reinforcement learning methods, the controller updates its policy to pick better architectures. In evolutionary strategies, low‑performing candidates are replaced by modified versions of high‑performing candidates. In gradient‑based NAS, the architecture parameters are adjusted via back‑propagation over a continuous relaxation of the search space.
Step #5: Iterate and finalize
Steps 2 to 4 are repeated until the search meets a termination condition (e.g., a maximum number of evaluations or convergence of validation performance). Finally, the best architecture is fully trained on the training dataset and evaluated on the test set to report its performance.
Types of Search Space in NAS
The search space defines the set of all possible architectures the algorithm can explore. It acts as the “design playground,” specifying what building blocks (such as layers, blocks, or cells) are available and how they can be connected. The choice of search space heavily influences both the expressiveness of the architectures that can be discovered and the efficiency of the search process. Let’s discuss common search space types.
Layer: A single operation like a convolution or pooling. Sometimes a well-known combo, e.g., inverted bottleneck residual from MobileNetV2.Block / Module: A small fixed stack of layers, reused as a unit. Example: ResNet residual block.Cell: A DAG of operations searched in cell-based NAS. Example: NASNet normal cell or reduction cell.Motif: A repeated sub-pattern made from multiple operations or cells, common in hierarchical NAS. Example: Transformer encoder block as a higher-level motif.
Macro Search Spaces
The macro search space defines the entire neural network architecture in a single stage rather than focusing on smaller repeated components. It has two variants:
- In one variant, the architecture is modeled as a directed acyclic graph (DAG) where each node represents an operation (such as convolution, pooling, or fully connected layers) and the search includes both the choice of operations and the network topology. For example, the NASBOT CNN search space allows combinations of various convolution and pooling layers with depths up to 25.
- In another variant, the topology and operations remain fixed, but macro-level hyperparameters such as network depth, width, and spatial resolution downsampling points are optimized, such as scaling strategy in EfficientNet.
While macro search spaces provide high expressiveness and the potential to discover entirely novel architectures, their vast design space makes them computationally expensive to explore.
Chain-Structured Search Spaces
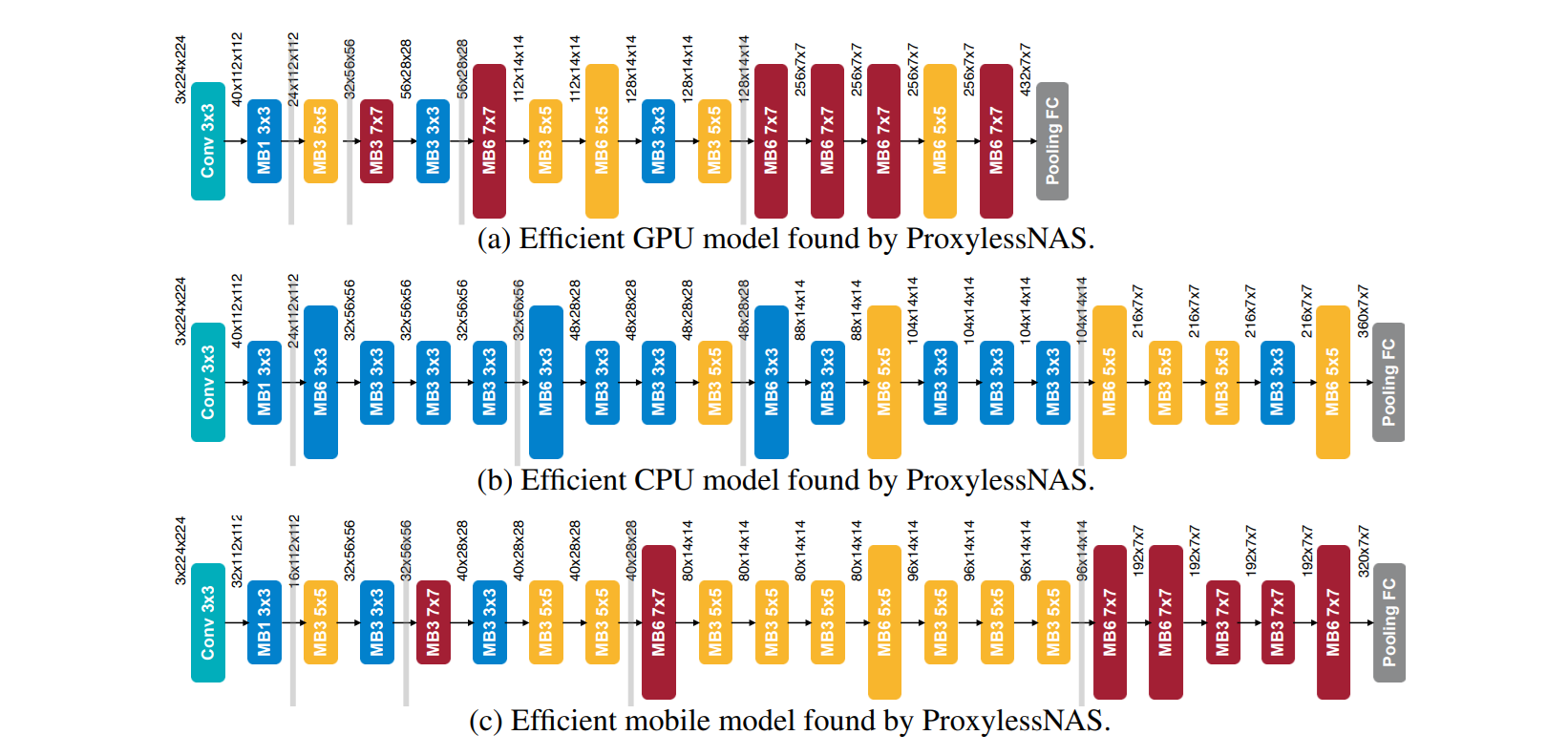
The chain-structured search space defines architecture as a simple sequential stack of layers, where each layer directly feeds into the next. These spaces often build on strong manually designed backbones such as ResNet or MobileNet and then allow variation in certain components.
For example, ProxylessNAS starts from MobileNetV2 and searches over kernel sizes and expansion ratios in inverted bottleneck residual layers, while XD-operations and DASH explore kernel sizes, dilations, or generalized convolutions derived from LeNet, ResNet, or WideResNet.
Chain-structured designs are also common in transformer-based NAS. Lightweight Transformer Search (LTS) searches GPT-style models by varying layer count, model width, embedding dimensions, feedforward network size, and attention heads. NAS-BERT and MAGIC apply similar ideas to the BERT architecture with multiple attention, feedforward layers, and convolutions with different kernel sizes.
This design is easy to implement, computationally efficient to search, and can quickly yield competitive models. But the restricted linear topology limits the diversity of architectures, and reduces the likelihood of discovering highly novel designs.
Cell-Based Search Space
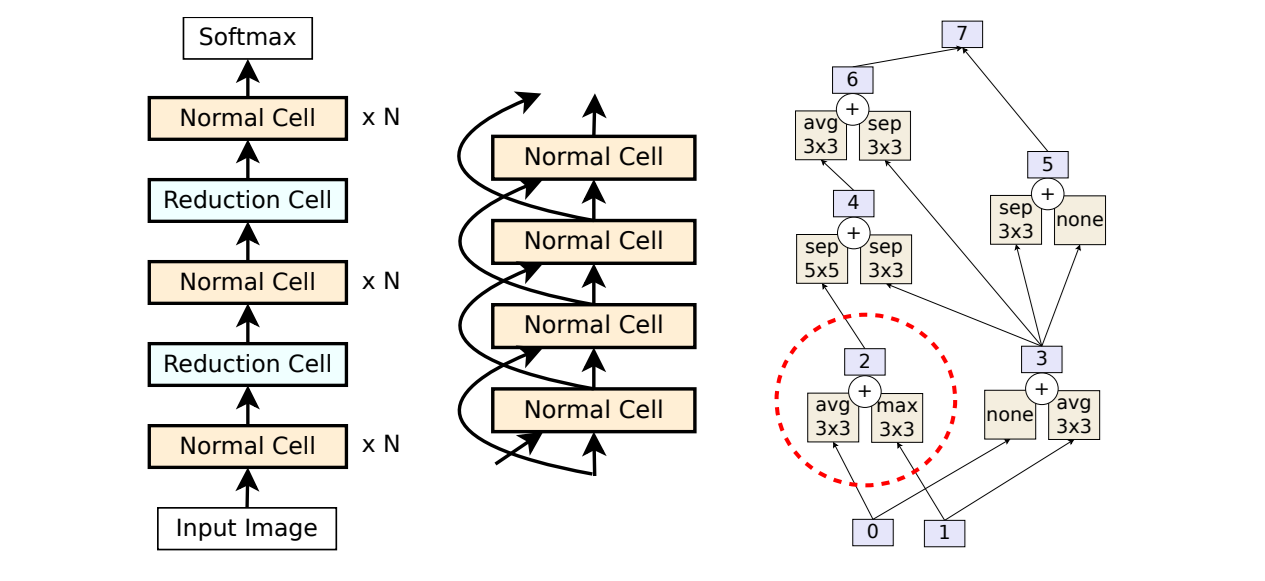
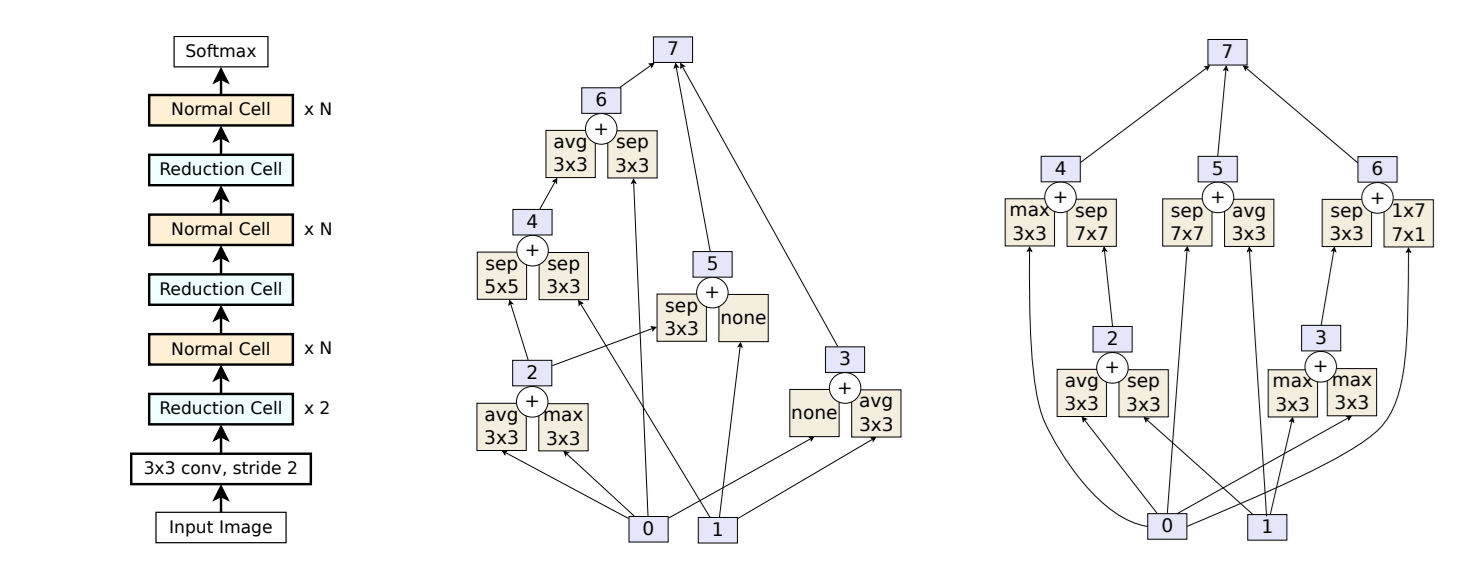
Cell-based search space focuses on designing small, repeatable building blocks (cells) instead of searching the entire network from scratch. This idea comes from human-designed CNNs like ResNet, where repeating units such as residual blocks are used throughout the model. In this setup, the micro-structure (the cell’s internal design) is searched, while the macro-structure (how cells are arranged in the full network) is fixed.
The first well-known example, NASNet, uses two cell types:
- Normal cell keeps the same spatial resolution.
- Reduction cell halves the spatial resolution by using stride-2 operations.
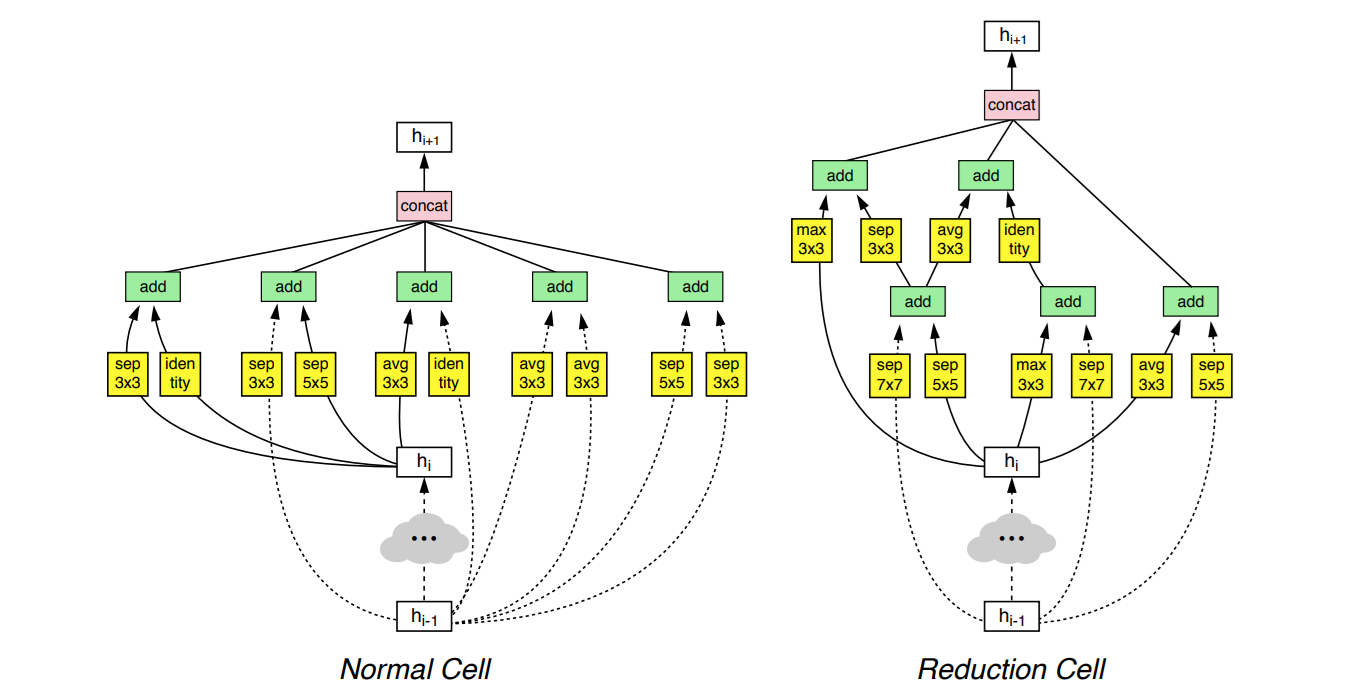
Each cell is a DAG with nodes representing operations (e.g., convolutions, pooling) and combination steps (addition or concatenation). By stacking normal and reduction cells, NASNet produces the final architecture.
Other popular cell-based spaces include NAS-Bench-101, which defines 7-node cells with 3 operation choices per node (423,624 possible architectures), and DARTS, which differs by placing operations on the edges of the graph rather than the nodes and allow gradient-based search and yielding 1018 possible architectures.
Cell-based designs are also applied beyond computer vision tasks. For example, NAS-Bench-ASR searches convolutional cells for speech recognition, and LSTM-based cell search spaces exist for language modeling.
The main strength of cell-based search is efficiency and transferability. Optimal cells found on small datasets like CIFAR-10 can be scaled up for larger datasets like ImageNet. However, limitations include low performance variance among architectures (making advanced search strategies yield small gains), ad-hoc design constraints (like fixed cell node counts), and reduced expressiveness compared to macro-level search.
Hierarchical Search Space
The hierarchical search space designs architectures at multiple levels rather than searching only one flat level (like in the cell or macro level). In this approach, higher-level motifs are built from lower-level motifs, and each level is typically represented as a DAG composed of components from the level below.
A simple example is a two-level hierarchy, where the lower level defines the micro-structure (such as cells or layer blocks) and the upper level controls macro-level hyperparameters like the number of cells per stage, downsampling points, or block types.
For example, MnasNet uses MobileNetV2 blocks at the lower level and searches macro parameters like depth, width, and resolution at the higher level. Similar two-level setups have been applied in semantic segmentation, image denoising, stereo matching, and vision transformers, combining local convolutions and global self-attention layers.
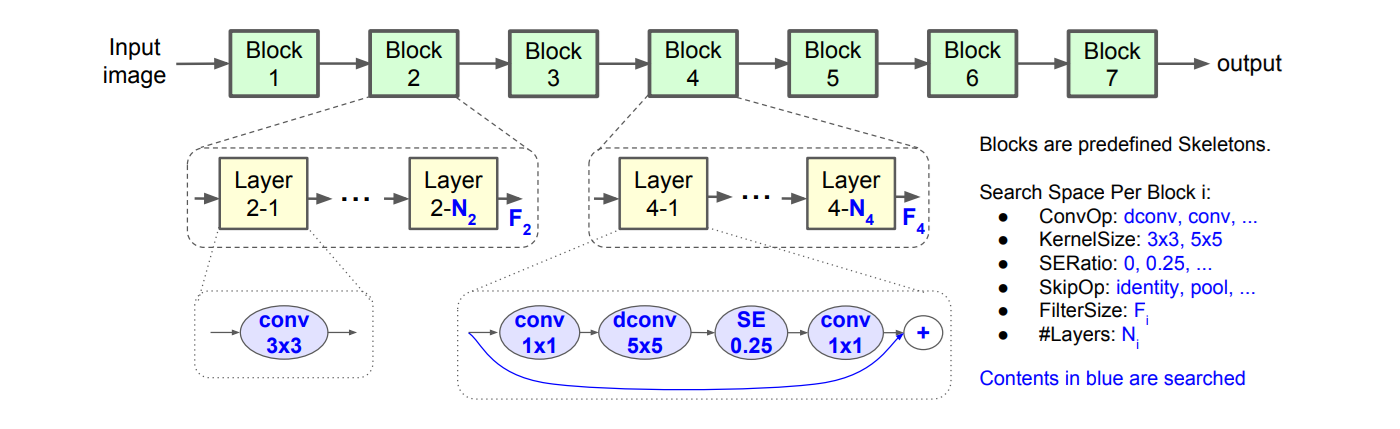
More complex designs extend this to three or more levels where:
- Level 1 defines primitive operations i.e. smallest building blocks such as a 3x3 convolution, max pooling, or a ReLU activation. For example, A 3×3 Conv layer from ResNet.
- Level 2 defines motifs, a small structures made by combining multiple primitives into a reusable unit. For example, a ResNet residual block combining convolution, batch normalization, and skip connections.
- Level 3 defines the final architecture i.e. the complete network formed by connecting multiple motifs in sequence or stages. For example, ResNet-50, which stacks residual blocks into four main stages to form the full model.
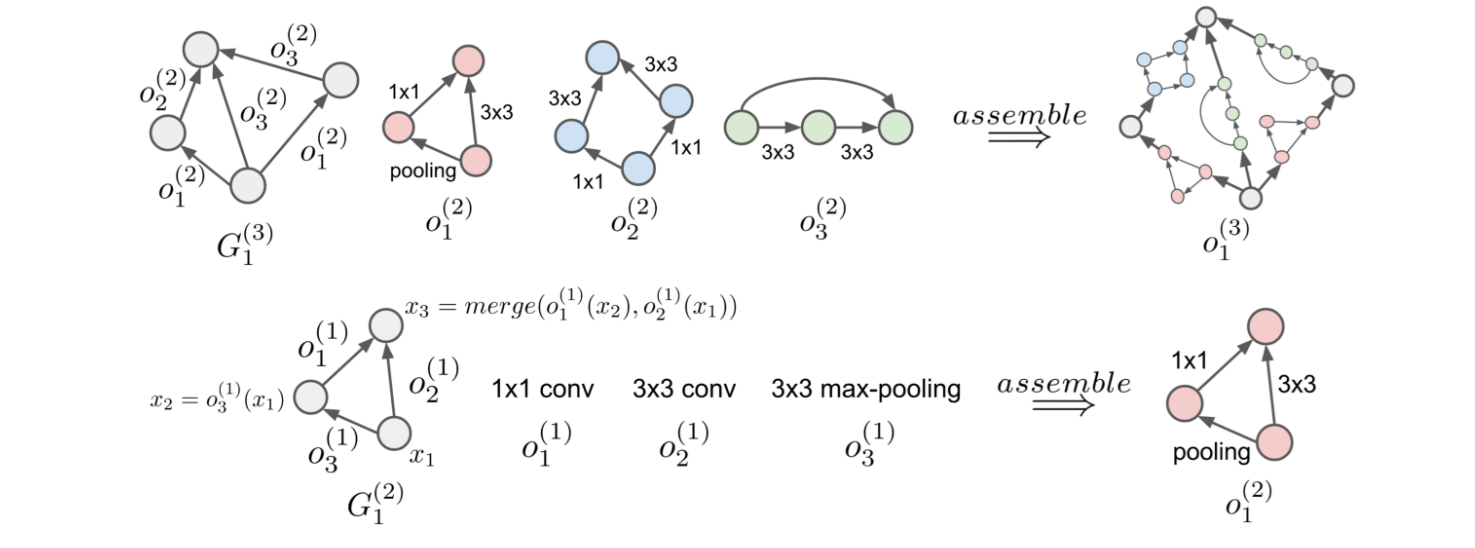
There are researches that extend beyond three levels, enabling recursive or variable-depth hierarchies for even more complex designs.
The hierarchical search space is highly expressive, and able to represent a much wider variety of architectures. It can reduce search complexity by reusing smaller motifs to build larger structures. However, it is more complex to implement, and requires careful design to make the search efficient.
Search Strategies in NAS
The search strategy is the method NAS uses to explore the search space and find high-performing architectures. Different strategies balance exploration (trying new designs) and exploitation (refining promising ones) in different ways.
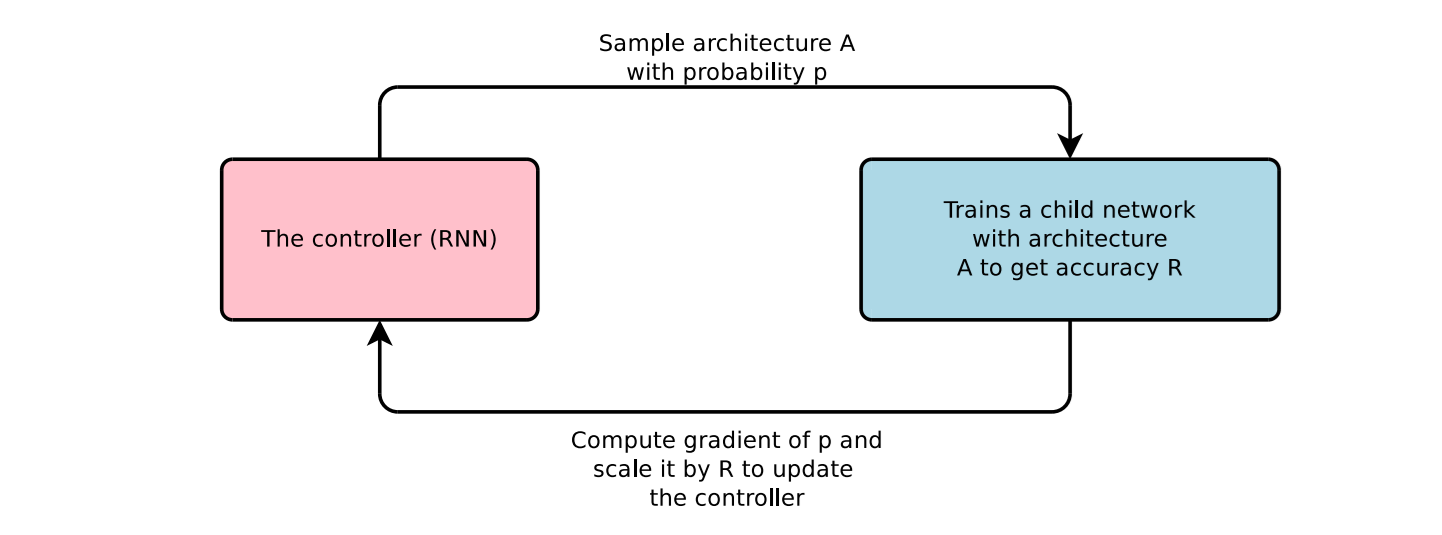
Reinforcement Learning (RL)
In the reinforcement learning based NAS search technique, an agent (often implemented as a RNN controller) generates architectures step-by-step by making sequential decisions about layers, operations, and connections. After an architecture is generated, it is trained and evaluated on a target task, and the resulting performance (e.g., validation accuracy) is used as a reward signal. Over many iterations, the controller learns to produce better architectures by maximizing these rewards. This approach treats architecture search as a sequential decision-making problem, allowing the system to explore vast and complex design spaces.
A famous example is NASNet which used RL to discover high-performing convolutional cell structures that could be transferred to larger datasets like ImageNet. Another example is ENAS, which improved efficiency by using parameter sharing so that multiple architectures could reuse weights. This reduces the search cost from many GPU days to just a few.
Evolutionary Algorithms (EA)
Evolutionary algorithms mimic the process of natural selection to discover optimal architectures. They maintain a collection of candidate architectures (population), evaluate their performance (fitness), and select the best-performing models by altering layers, kernel sizes, or connections (mutation) and combining parts of two architectures (crossover). Over iterations, the model evolves toward better design.
One well-known approach, AmoebaNet-A is an image classifier, outperforming many manually designed architectures. Another early milestone was Large-Scale Evolution of Image Classifiers, which demonstrated that pure evolutionary methods could compete with human-designed models when given sufficient computational resources. However, powerful EA can be expensive since evaluating each generation often requires training many architectures from scratch.
Gradient-Based / Differentiable Search
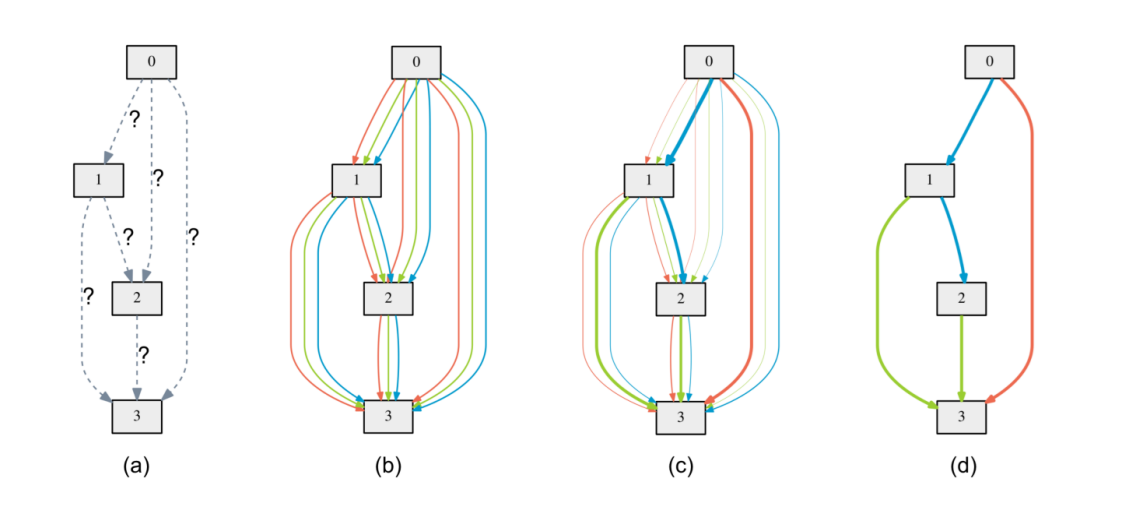
Gradient-based NAS transforms the discrete architecture search problem into a continuous optimization problem. Instead of choosing one operation for each connection, it assigns continuous weights to all possible operations (via softmax relaxation). Both the model’s weights and these architecture parameters are optimized together using gradient descent. At the end, the highest-weighted operations are selected to form the final architecture.
The DARTS method initiated this approach by enabling fast search without training each candidate from scratch. Later improvements like ProxylessNAS adapted this method to run directly on target hardware while keeping memory usage low. Gradient-based NAS offers high speed improvements compared to RL or EA but can sometimes due to relaxation, the search can settle on designs that are not the best.
Bayesian Optimization (BO)
Bayesian optimization is a sample-efficient NAS method that builds a probabilistic model (often a Gaussian process) to approximate the relationship between architecture configurations and their performance. Using this model, it selects the next architecture to try via an acquisition function, which balances exploring new regions of the search space and exploiting known promising areas.
For example, NASBOT used Bayesian optimization combined with optimal transport metrics to guide the search in complex CNN architecture spaces. BO is particularly useful when training each candidate is computationally expensive, because it can find good architectures with fewer evaluations. However, it struggles in extremely large or high-dimensional search spaces.
Random Search
Random search is the simplest NAS strategy. It selects architectures completely at random from the search space, trains them, and records performance. While this brute-force approach lacks intelligent guidance, research has shown that with a well-designed search space, random search can be surprisingly competitive. Especially when paired with weight sharing to reduce evaluation costs.
Liam Li and Ameet Talwalkar showed that a carefully controlled random search can perform well in some cases. But without learning-based guidance, random search usually needs many more tries to find good models. So it becomes costly in very large search spaces.
One-Shot NAS (Supernet-Based Search)
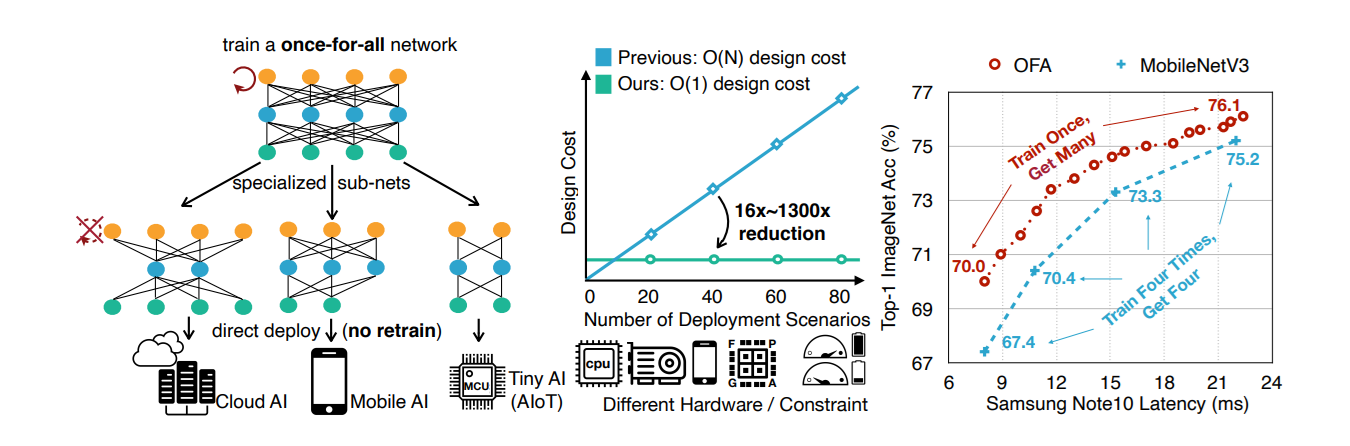
One-shot NAS trains a supernet, a single large network that contains all possible sub-architectures in the search space as paths or subgraphs. Candidate architectures are evaluated by sampling subnets from the supernet and using the already-trained shared weights which avoid full retraining. This “train once, evaluate many” strategy reduces search time.
The Once-for-All Network is a prime example, where the supernet is trained to support many configurations that can be specialized for different devices or constraints (e.g., latency, power consumption). One-shot NAS provides speed and flexibility but can introduce bias, as shared weights may not perfectly reflect the performance of individually trained architectures.
Why Use Neural Architecture Search?
Neural Architecture Search turns architecture creation into a machine learning problem itself, systematically hunting down the best possible configuration so you don't have to.
1. Automation for Everyone
One of the primary benefits of NAS is reducing the need for manual trial‑and‑error. Traditional neural‑network design often requires significant domain knowledge and time‑consuming experimentation. NAS automates this process and allows even non‑experts to obtain high‑performing models.
2. Discovering Novel Designs
Sometimes, the best architecture is one a human would never think to build. NAS has a track record of discovering weirdly effective structures that outperform hand-designed models while using a fraction of the parameters.
3. Hardware-Aware Performance
Building for a GPU in the cloud is one thing; building for a mobile phone or an OAK-D camera is another. Hardware-aware NAS bakes your device’s constraints - like latency, memory limits, and power consumption - directly into the search. Techniques like DPP‑Net explicitly incorporate device characteristics (e.g., memory capacity) into the search process, while ProxylessNAS searches directly on the target hardware by pruning computational paths.
4. Shipping Faster
In the early days, NAS was a compute hog. Today, techniques like weight-sharing and differentiable search have slashed search times from months to mere hours. This doesn't just mean a faster development cycle; it means more sustainable AI.
5. Reusable Innovation
The best part about NAS-discovered components is that they play well with others. The modular "cells" discovered for one dataset often generalize perfectly to others. For example, the cells learned by NASNet on CIFAR‑10 were successfully transferred to ImageNet and improved object‑detection performance when integrated into the Faster‑RCNN framework. Also, carbon‑efficient NAS search frameworks such as CE‑NAS reduce compute requirements and address carbon footprint.
How Does RF-DETR Use NAS?
RF-DETR uses weight sharing. Instead of training thousands of models, it trains one model that can behave like many smaller models. At each training step, the model uses a different configuration, but all configurations share the same weights. This allows the model to learn how to work well across many choices without retraining every time.
The model is allowed to change. RF-DETR does not search for strange or exotic architectures, it focuses on practical knobs that directly impact speed and accuracy. These include patch size, which controls how many tokens the model sees, the number of decoder layers, which controls depth and speed, the number of object queries, which controls how many objects the model can detect, input resolution, which affects small object performance, and attention windows, which trade global context for speed. Each combination of these is a valid model.
Here's how these knobs matter. Smaller patches mean more tokens, more detail, and more compute. On the other hand, larger patches mean fewer tokens and faster inference. More decoder layers improve accuracy, but increase latency. More queries help detect crowded scenes, but cost more compute. Higher resolutions help small objects, but increase costs. These trade-offs are predictable, and that's why they work well with NAS.
Here's the key idea: training happens once. After training, you evaluate many configurations on a valid set. From that evaluation you get a curve called the Pareto curve that shows accuracy versus speed. You then pick the version that best fits your needs - no retraining, no guessing.
NAS is not about inventing weird networks. It's about finding the right balance. RF-DETR shows that NAS can produce models that are fast, accurate, and practical. By training once, and selecting later you get the state of the art performance, without the traditional cost. That's why NAS is becoming a standard tool in computer vision, not just a research idea anymore.
Neural Architecture Search (NAS) Conclusion
The future of computer vision isn't just about bigger models; it's about smarter architectures.
- Explore the Models: Check out Roboflow Playground to see how state-of-the-art models perform on real-world data.
- Train Your Own: Ready to move beyond the defaults? Use Roboflow Train to leverage optimized backbones that have already done the heavy lifting for you.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Aug 13, 2025). What Is Neural Architecture Search (NAS)?. Roboflow Blog: https://blog.roboflow.com/neural-architecture-search/