
Introduction to Text Extraction
Manually working with data in JPG, PNG, or PDF formats can be a hassle, as it takes a lot of time to analyze and these files can’t be managed easily in a programmatic way. We can use tools, either online or offline, to convert images into editable text and make our work easier. An Optical Character Recognition (OCR) API is one such tool that can help extract text from images.
In this article, we’ll explore how using an OCR API can make extracting text from images easier and more efficient. Let’s get started!
Why Do We Need to Extract Text from Images?
Before we learn to extract text from images, let’s first explore why it is important and its impact. The technology to extract text from images has been around for a very long time, and over the years, it has found its way into many applications from automating data entry process to data analysis. Let’s take a look at some of these use cases to better understand OCR technology.
Extract Text from Images to Automate Data Entry
By extracting text from images, businesses can automate data entry. It is a great solution for handling repetitive data entry tasks efficiently and significantly saves time, reduces errors, and cuts labor costs.
The OCR process involves taking text from sources like scanned documents, receipts, and forms and converting it into a digital, machine-readable format. Once digitized, the data can be easily edited or changed as needed, which is much harder to do with non-digital formats.
A great example of how automation boosts efficiency is the USPS Flats Sequencing System (FSS). It is an enormous OCR system, roughly the size of a football field, that processes 300,000 pieces of mail daily and sorts them for 125,000 delivery addresses with incredible precision. It significantly cuts down on the need for manual sorting and handles large envelopes, magazines, catalogs, and circulars quickly and accurately. The system ensures consistent, reliable, and on-time delivery while reducing the need for manual work.
Extract Text from Images to Enhancing Accessibility
Access to information is essential in today’s digital world. However, documents can be hard to navigate for people with disabilities, especially those who are visually impaired. Extracting text from images can make digital content more accessible, inclusive, and fair. OCR tools play an important role in this effort. OCR scans and converts documents into digital text that screen readers can read aloud. Using this tech, visually impaired users can now hear text from images or save it as digital files for later.
OCR technology allows visually impaired individuals to access information they couldn’t before by making text in images accessible through screen readers. This improvement in accessibility is vital for creating a digital world where everyone can engage with content equally.
Extract Text from Images to Improve Searchability
For occupations that involve working with large collections of images, such as scanned books or historical documents, making these collections searchable can be a real game-changer. Finding specific information from large archives of documents can feel like searching for a needle in a haystack. Digitizing all that data using text extraction tools will streamline how we access and use these vast collections.
You can then perform text-based searches within large image collections, making it much easier to find specific information. OCR also improves the quality and accuracy of metadata and cataloging, ensuring more precise search results and reducing storage space since text files are smaller than image files.
Extract Text from Images to Enable Translation
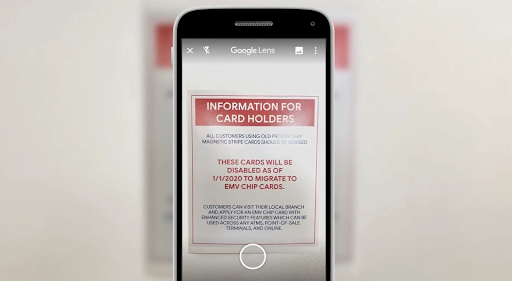
Using OCR is a great tool for translating multilingual documents or foreign signage. OCR acts as a bridge, turning these non-editable documents into machine-readable text that is ready for translation software.
Using OCR for translation offers several benefits. It boosts efficiency by quickly scanning and digitizing text, speeding up the translation process. Translators can now focus on the nuances of translation rather than manual transcription. OCR also improves accuracy, allowing translators to double-check their work and produce reliable translations. Also, OCR increases access to a wider range of documents, making it possible to digitize and translate materials that would be too time-consuming to transcribe manually.
Turning Documents into Data for Analysis
OCR is a great tool for preparing data for analysis. To analyze data, we first need to extract data in a machine-readable form. Businesses can use OCR to process invoices, receipts, and other paperwork quickly and accurately. In healthcare, it helps manage patient records and insurance claims. Researchers use it to analyze old documents and discover new information. Even self-driving cars use OCR to read street signs. Essentially, OCR is a tool that saves time, reduces errors, and unlocks the information hidden in printed materials.
How to Extract Text from Images
Now that we have taken a look at OCR use cases, let’s learn how to extract text from images using Roboflow’s OCR API. The API is powered by DocTR, which is a machine learning-powered OCR model.
Step 1: Set Up Your Roboflow Account
To get started, create a free Roboflow account and log in to access the platform.
Step 2: Install Dependencies
Then, we can install the necessary tools and libraries required for this project. Open a terminal or command prompt and run the following command to install the required libraries:
pip install inference inference-sdkStep 3: Extract Text From Images
After installing the dependencies, you can initialize the InferenceHTTPClient with the API URL and your API key to load the OCR model. Open a Python file and run the following code.
import os
from inference_sdk import InferenceHTTPClient
CLIENT = InferenceHTTPClient(
api_url="https://infer.roboflow.com",
api_key="YOUR_ROBOFLOW_API_KEY"
)
result = CLIENT.ocr_image(inference_input="./image.jpeg")
print(result)You will need to replace two values in the code above:
- ‘image.jpeg’: The filename of the image you want to extract text from.
- API_KEY: Your Roboflow API key. Here’s a resource to help you retrieve your Roboflow API key.
Input Image:
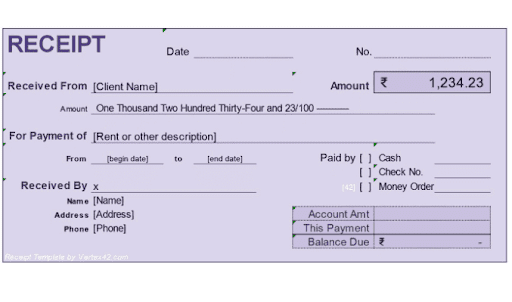
Output:
{'result': 'RECEIPT Date No. Received From [Client Name] Amount R 1,234.23 Amount One Thousand Two Hundred Thirty-Four and 23/100 For Payment of [Rent or other description) From [begin date] to [end date] Paid by [ I Cash Check No. [ I Money Order Received By x Name [Name] Address [Address] Phone [Phone) Account Amt This Payment Balance Due 2 Fpupt Tmpile by Mertrizcon', 'time': 1.5897352940000928, 'parent_id': None}As you can see from the output, all the textual data from the input image has been successfully extracted.
Extract Text from Specific Regions of an Image
Next, instead of extracting all the data, we’ll look at an example of extracting data from specific regions. We’ll try to extract text from an image of a shipping container. We’ll use an object detection model to detect the regions of interest and then extract the specific data we need, such as the container number and ISO type.
import requests
import base64
from roboflow import Roboflow
from PIL import Image
from io import BytesIO
import supervision as sv
API_KEY = "ROBOFLOW_API_KEY"
rf = Roboflow(api_key=API_KEY)
project = rf.workspace().project("container-shipping-number2")
model = project.version(3).model
bounding_boxes = model.predict("image.jpeg").json()
predictions = sv.Detections.from_inference(bounding_boxes)
image = Image.open("image.jpeg")
classes = [i["class"] for i in bounding_boxes["predictions"]]
for i, _ in enumerate(predictions.xyxy):
x0, y0, x1, y1 = predictions.xyxy[i]
class_name = classes[i]
# add 10% padding
x0 = int(x0 * 0.9)
y0 = int(y0 * 0.9)
x1 = int(x1 * 1.1)
y1 = int(y1 * 1.1)
cropped_image = image.copy().crop((x0, y0, x1, y1))
# change to black and white
cropped_image = cropped_image.convert("L")
# convert to base64
buffered = BytesIO()
cropped_image.save(buffered, format="JPEG")
data = {
"image": {
"type": "base64",
"value": base64.b64encode(buffered.getvalue()).decode("utf-8")
}
}
# decode and show image
img = Image.open(BytesIO(base64.b64decode(data["image"]["value"])))
img.show()
ocr_results = requests.post("https://infer.roboflow.com/doctr/ocr?api_key=" + API_KEY, json=data).json()
print(ocr_results, class_name)Input Image:

Output:


Regions of Interest
{'result': 'CBCU 200031 0ons', 'time': 1.4347421770000892, 'parent_id': None} container-number
{'result': '- . - 226', 'time': 1.057534553000096, 'parent_id': None} iso-typeThe OCR API was able to successfully identify the text for the container number but missed some characters related to the ISO type. You can use additional preprocessing steps to mitigate such issues when extracting text from images.
Here are a few other considerations to make when working with OCR models:
- Ensure the text in the image is as readable as possible (i.e. the lighting conditions make the text visible, and the typeface is easy to read).
- Use an error correction system to address mistakes in the OCR endpoint.
We’ll learn more about error correction in the following sections.
Extracting Text from Images Using Your Hardware
You can also run the OCR API on a device through Roboflow Inference. Inference allows you to deploy any type of computer vision model. You can also deploy pre-trained models (i.e. YOLOv5 and YOLOv8) and use foundation models such as DocTR. Inference can be run on a range of devices and architectures, from x86 CPU to ARM CPU to NVIDIA GPU.
First, you’ll need to install the package. Run the following code in the command prompt:
pip install inferenceCreate a new Python file and run the following code:
import os
from inference_sdk import InferenceHTTPClient
CLIENT = InferenceHTTPClient(
api_url="http://localhost:9001",
api_key=os.environ["ROBOFLOW_API_KEY"]
)
result = CLIENT.ocr_image(inference_input="./image.jpg")
print(result)When this code runs for the first time, DocTR will be downloaded automatically to your system. The amount of time this process will take depends on the strength of your internet connection.
Once you have the model weights ready on your system, you can extract text from images. The OCR API runs entirely on your device without the requirement of an internet connection once you have downloaded the model weights for the first time.
Error Correction when Extracting Text From Images
As we have seen from our coding exercise above, text extraction is very useful but not always perfect. Even with clear text and recognizable fonts, OCR systems can sometimes make mistakes. This is why error correction is an essential step in the text extraction process. It involves reviewing the text output generated by an OCR model and cleaning it up as necessary.
Let's check out some popular error correction methods:
- Rules or Heuristics: Correct OCR errors based on context, such as changing "l" to "1" if numbers are expected.
- Spelling Correction: Use tools like SymSpell to automatically fix spelling mistakes, available in many programming languages.
- Multiple OCR Models: Use two different OCR models for comparison, choosing the most accurate result or combining the best parts.
- Expected Outputs: Automate error correction by matching expected text in specific document sections, such as in insurance documents.
Conclusion
Extracting text from images is key to turning static text files into editable text. OCR technology, such as Roboflow's OCR API, makes this process easier and faster. It helps with tasks like data entry, making information accessible, and translating text. While OCR is useful, mistakes can sometimes be made. To fix these errors, you can use methods like correcting text based on context, fixing spelling mistakes, and using multiple OCR tools. These steps improve accuracy and make sure the text is correct and useful for everyone.
Keep Reading
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Aug 7, 2024). How to Extract Text From Images. Roboflow Blog: https://blog.roboflow.com/extract-text-from-images/