
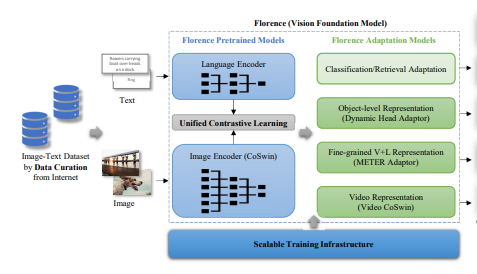
Florence, released by Microsoft Research, applies the foundational model paradigm from NLP to computer vision by pre-training on large-scale image-text data and achieving strong results across detection, segmentation, captioning, and classification without task-specific architectures. Unlike OpenAI CLIP, which focused on classification, Florence addresses a wide range of computer vision tasks in a single model. Florence-2, released in 2024 under MIT license, extends this with strong zero-shot and fine-tuning performance on 126 million images despite a compact size.
Update: as of June 2024, Florence-2 has been made available for use under MIT license.
Microsoft Research recently released the foundational Florence model, setting the state of the art across a wide array of computer vision tasks.
In this post, we will boil down the research done in the Florence paper and comment on what it means for the computer vision field.
Computer Vision has Lacked a Foundational Model
In natural language processing, AI research has been dominated by the paradigm of pre-training models on an unsupervised task (like language modeling) and finetuning on specific tasks (like text classification). This paradigm was started all the way back with word vectors, contextualized by Elmo, and then scaled to transformers with BERT.
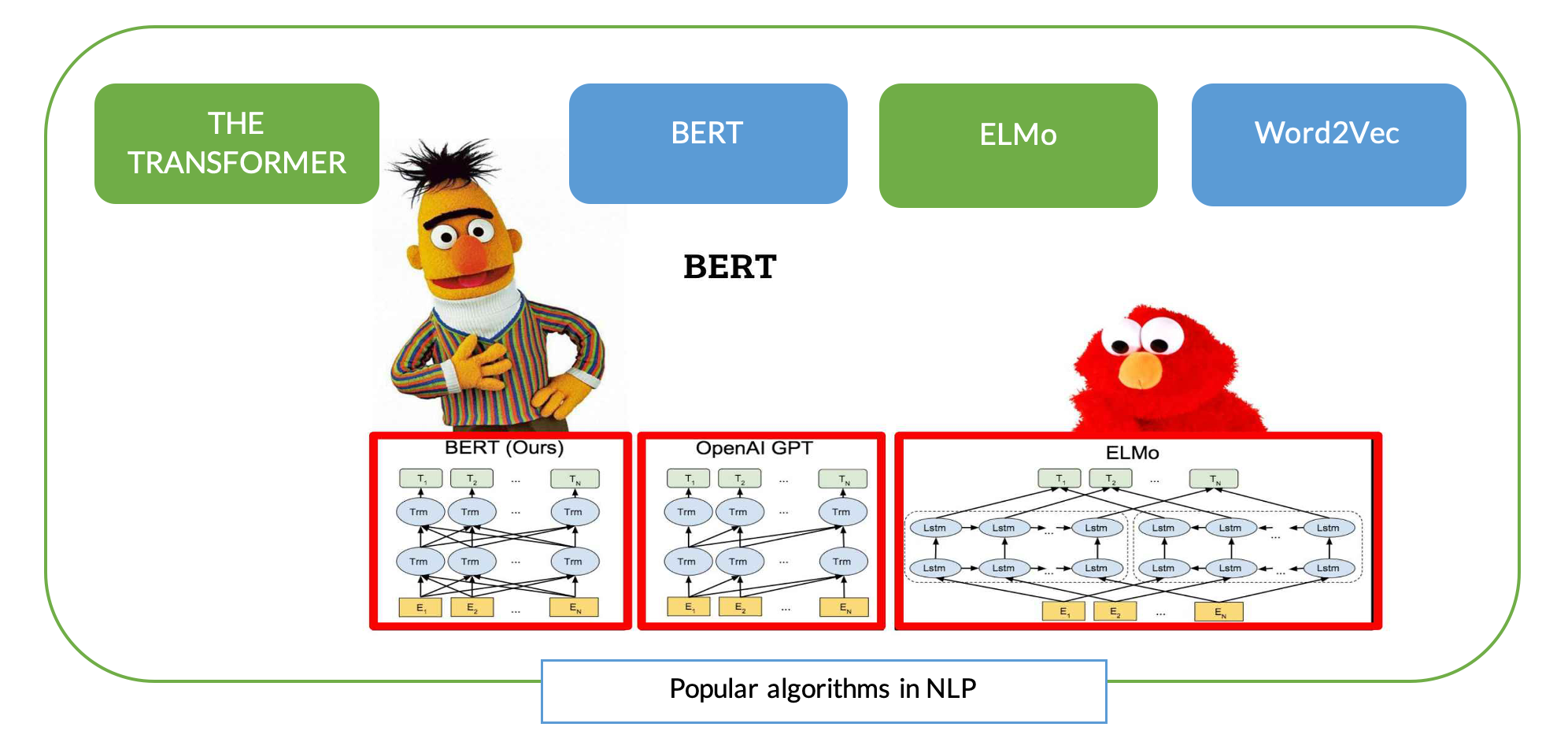
In computer vision, there has not been a pretraining procedure, beyond pretraining your classifier on ImageNet or your object detector on COCO, which are both narrow datasets defining a supervised task. The ImageNet authors would love to hear me calling their 1000 class, 1.2MM image dataset narrow, but it is hard to keep up with the size of wikipedia when you need to annotate images.
OpenAI CLIP: Computer Vision's First Foundational Model
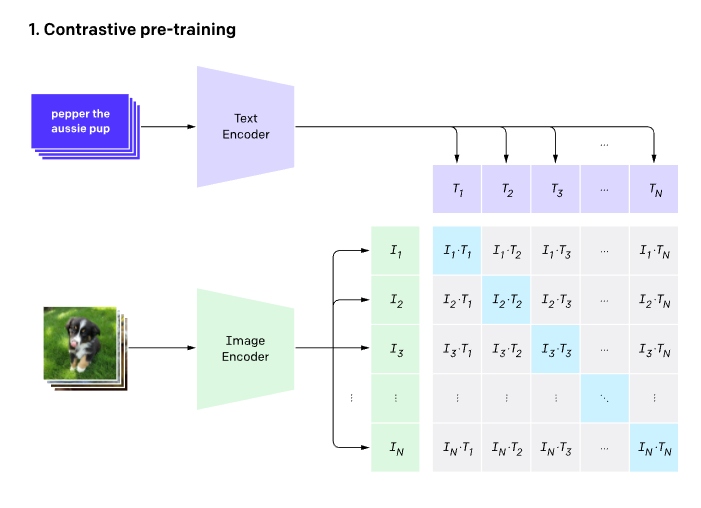
Computer Vision saw its first foundational model with OpenAI's release of CLIP - Connecting Text and Images, perhaps the most influential AI model of 2021. The CLIP model was trained on 400MM image-caption pairs, learning to associate the semantic similarity of text and images. It turned out that this kind of a pretraining procedure produced very robust image and text features that can be leveraged for a variety of downstream tasks including search and zero shot classification.
On the modeling side, CLIP is novel to computer vision in that it leverages a vision transformer to encode images. Transformers are transplants to computer vision from the NLP world.
The CLIP research paper focuses specifically on image classification benchmarks, but leaves other computer vision tasks up to the community to build on. Florence, on the other hand, makes modeling progress on a wide host of computer vision tasks within the scope of the paper.
Florence Computer Vision Tasks
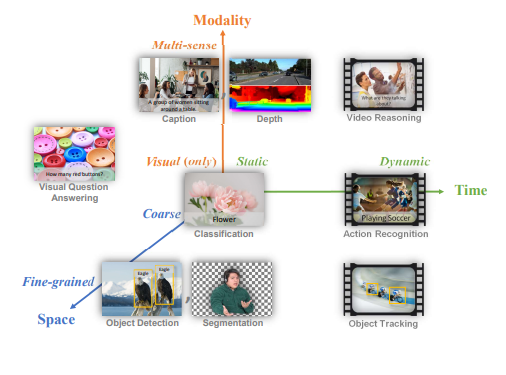
The Florence research team set out to make a foundational model that could adapt to different task dimensions in computer vision. They define three dimensions that the model must span:
- Space: coarse to fine, like image classification to semantic segmentation.
- Time: from static to dynamic, like images to videos.
- Modality: like RGB to RGB+depth
In terms of computer vision task types, Florence adapts to the following:
- Zero shot image classification
- Image classification linear probe
- Image classification fine tuning
- Text to Image Retrieval
- Object detection
- Text to Video Retrieval
- Video Action Recognition
For more details on how the Florence authors adapt their base model to these tasks, like how they apply DyHead for object detection, check out the paper.
Florence Pre-Training Procedure
In order to pre-train the core of their foundational model, the Florence authors use a large image-caption dataset of 900MM images, called FLD-900M. Their training routine iterates over the dataset samples and the model is tasked with picking out which images belong with which captions.
Training ran for 10 days across 512 NVIDIA-A100 GPUs. 🤯
For more details on the model architecture, training loss function, and training infrastructure, check out the paper.
Florence Benchmarks on Roboflow Universe
The part of Florence that is likely most relevant to computer vision practitioners is Florence's progress in object detection.
When making an object detection model, we typically need to gather a full dataset and train a model on it. It would be nice if the model could generalize right away without additional training, termed "zero shot".
To test their model's generalizability, the Florence researchers benchmark against a few popular Roboflow Universe datasets.
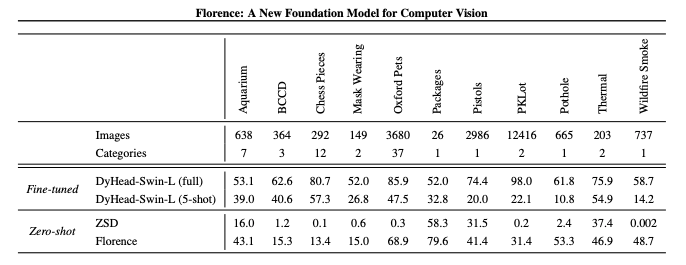
Two things are important to point out in this evaluation:
1) While the model is generalizable, it still greatly benefits from greater exposure to images in the dataset.
2) The model does better in a zero shot setting when the object is more common, like pets.
Is Florence Open Source?
At Roboflow, we are notorious for providing training and inference tutorials for new computer vision models, but unfortunately the code and model weights for Florence are not open source at the time of this article's writing.
In the meantime, if you are itching to get your hands dirty with a foundational model, I suggest you try out CLIP.
Will Foundational Computer Vision Models Have an Impact in Industry?
Foundational models like CLIP and Florence are pushing the boundaries of state of the art computer vision models, but will they have a large impact in industry? My opinion is that they will have an impact limited in scope, and it is summarized by technical constraints.
Non-Realtime Inference - Foundational models will have a large impact. For business applications that do not need low latency inference speeds, foundational models will be leveraged by applications that can use their general scope or they will be fine tuned to a specific domain. They will be deployed on large cloud CPU and GPU servers that can handle their memory requirements.
Realtime Inference - Foundational models will have a small impact on realtime computer vision models, where edge nano models reign supreme (like YOLOv5). This will be true until foundational model researchers start focusing on making model complexity tradeoffs in the name of inference speed.
Florence-2 Released
Florence-2 is a lightweight vision-language model open-sourced by Microsoft under the MIT license. The model demonstrates strong zero-shot and fine-tuning capabilities across tasks such as captioning, object detection, grounding, and segmentation.
Despite its small size, it achieves results on par with models many times larger, like Kosmos-2. The model's strength lies not in a complex architecture but in the large-scale FLD-5B dataset, consisting of 126 million images and 5.4 billion comprehensive visual annotations
Read more about Florence-2.
Conclusion
While the impact of foundational models in computer vision remains to be seen, it is an exciting time to be involved in the world of computer vision.
Perhaps we will be one day be living in a world where we don't need to collect narrow datasets to finetune our models, but the zero shot, few shot, and full shot evaluation in Florence suggest that we are a long way from that day - so until then let's keep building the narrow datasets and models together on Roboflow Universe!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Dec 9, 2021). Florence: A New Foundation for Computer Vision. Roboflow Blog: https://blog.roboflow.com/florence-a-new-foundational-model-for-computer-vision/