
PaliGemma is a vision language model (VLM) developed and released by Google that has multimodal capabilities.
Unlike other VLMs, such as OpenAI’s GPT-4o, Google Gemini, and Anthropic’s Claude 3 which have struggled with object detection and segmentation, PaliGemma has a wide range of abilities, paired with the ability to fine-tune for better performance on specific tasks.
Google’s decision to release an open multimodal model with the ability to fine-tune on custom data is a major breakthrough for AI. PaliGemma gives you the opportunity to create custom multimodal models which you can self-host in the cloud and potentially on larger edge devices like NVIDIA Jetsons.
If you're interested in fine-tuning PaliGemma for object detection tasks, see our guide and Colab notebook for PaliGemma fine-tuning.
What is PaliGemma?
PaliGemma, released alongside other products at the 2024 Google I/O event, is a combined multimodal model based on two other models from Google research: SigLIP, a vision model, and Gemma, a large language model, which means the model is a composition of a Transformer decoder and a Vision Transformer image encoder. It takes both image and text as input and generates text as output, supporting multiple languages.
Important aspects of PaliGemma:
- Relatively small 3 billion combined parameter model
- Permissible commercial use terms
- Ability to fine-tune for image and short video caption, visual question answering, text reading, object detection, and object segmentation
While PaliGemma is useful without fine-tuning, Google says it is “not designed to be used directly, but to be transferred (by fine-tuning) to specific tasks using a similar prompt structure” which means whatever baseline we can observe with the model weights is only the tip of the iceberg for how useful the model may be in a given context. PaliGemma is pre-trained on WebLI, CC3M-35L, VQ²A-CC3M-35L/VQG-CC3M-35L, OpenImages, and WIT.
Links to PaliGemma Resources
Google supplied ample resources to start prototyping with PaliGemma and we’ve curated the highest quality information for those of you who want to jump into using PaliGemma immediately. We suggest getting started with the following resources:
- PaliGemma Github README
- PaliGemma documentation
- PaliGemma fine-tuning documentation
- Fine-tune PaliGemma in Google Colab
- Access PaliGemma in Google Vertex
In this post we will explore what PaliGemma can do, compare PaliGemma benchmarks to other LMMs, understand PaliGemma’s limitations, and see how it performs in real world use cases. We’ve put together learnings that can save you time while testing PaliGemma.
Let’s get started!
What can PaliGemma do?
PaliGemma is a single-turn vision language model and it works best when fine-tuning to a specific use case. This means you can input an image and text string, such as a prompt to caption the image, or a question and PaliGemma will output text in response to the input, such as a caption of the image, an answer to a question, or a list of object bounding box coordinates.
Tasks PaliGemma is suited to perform relate to the benchmarking results Google released across the following tasks:
- Fine-tuning on single tasks
- Image question answering and captioning
- Video question answering and captioning
- Segmentation
This means PaliGemma is useful for straightforward and specific questions related to visual data.
We’ve created a table to show PaliGemma results relative to other models based on reported results on common benchmarks.

While benchmarks are helpful data points, they do not tell the entire story. PaliGemma is built to be fine-tuned and the other models are closed-source. For the purposes of showing which options are available, we compare against other, often much larger, models that are unable to be fine-tuned.
It is worth experimenting to see if fine-tuning with custom data will lead to better performance for your specific use case than out-of-the-box performance with other models.
Later in this post, we will compare PaliGemma to other open source VLMs and LMMs using a standard set of tests. Continue reading to see how it performs.
How to Fine-tune PaliGemma
One of the exciting aspects of PaliGemma is its ability to finetune on custom use-case data. A notebook published by Google’s PaliGemma team showcases how to fine-tune on a small dataset.
It’s important to note that in this example, only the attention layers are fine-tuned and therefore the performance improvements may be limited.
How to Deploy and Use PaliGemma
You can deploy PaliGemma using an open source Inference package. First, we will need to install Inference, as well as some other packages needed to run PaliGemma.
!git clone https://github.com/roboflow/inference.git
%cd inference
!pip install -e .!pip install git+https://github.com/huggingface/transformers.git accelerate -qNext, we will set up PaliGemma by importing the module from Inference and putting in our Roboflow API key.
import inference
from inference.models.paligemma.paligemma import PaliGemma
pg = PaliGemma(api_key="YOUR ROBOFLOW API KEY")Last, we can input a test image as a Pillow image, pair it with a prompt, and wait for the result.
from PIL import Image
image = Image.open("/content/dog.webp") # Change to your image
prompt = "How many dogs are in this image?"
result = pg.predict(image,prompt)When prompted with this image, we get the accurate answer of `1`.

PaliGemma Evaluation for Computer Vision
Next, we will evaluate how PaliGemma does on various computer vision tasks that we’ve tested using GPT-4o, Claude 3, Gemini, and other models.
Here, we will test several different use cases including optical character recognition (OCR), document OCR, document understanding, visual question answering (VQA), and object detection.

The following evaluation tests were run using the official Google Hugging Face Space which you can use to run your own tests as well.
PaliGemma for Optical Character Recognition (OCR)
Optical character recognition is a computer vision task to return the visible text from an image in machine-readable text format. While its a simple task in concept, it can be a difficult task to accomplish in production applications.
Below we try OCR with both the prompts that we’ve seen work with other LMMs, asking it to “Read the serial number. Return the number with no additional text.” With this prompt, it failed, claiming that it did not have the training or capability to answer that question.
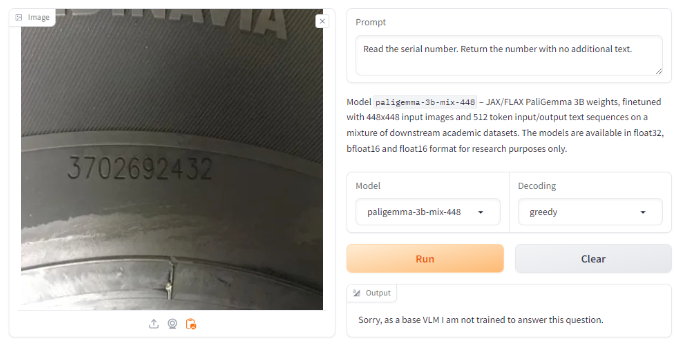
However, we know from the model documentation that it should be capable of OCR. We tried with the example prompt provided in the documentation, `ocr`, where we got a successful, correct result.
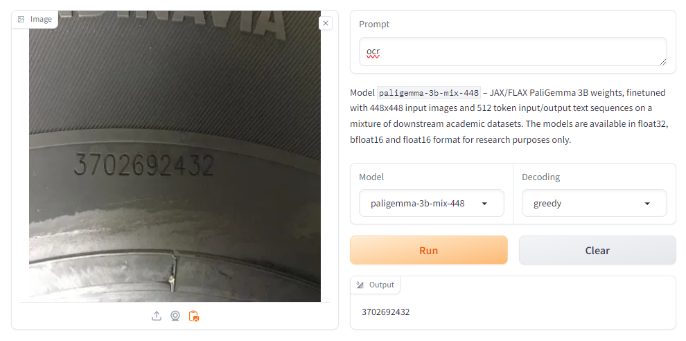
Trying with a different image with the first prompt also yielded correct results, bringing up a potential limitation of prompt sensitivity.
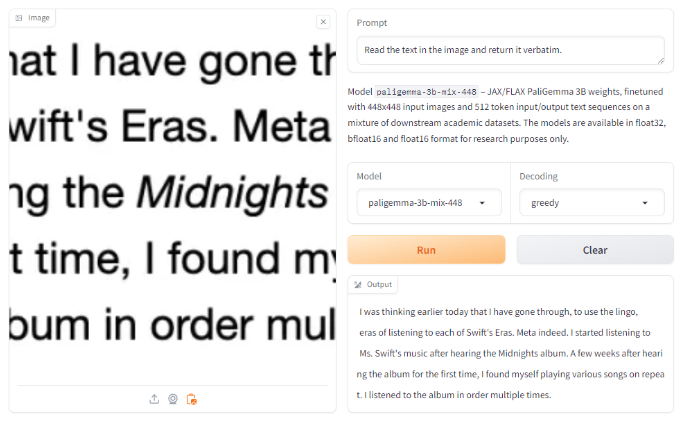
Next, testing on an OCR benchmark that we have used previously to test other OCR models like Tesseract, Gemini, Claude, GPT-4o and others, we saw very impressive results.
In average accuracy, we saw 85.84%, beating all other OCR models except for Anthropic’s Claude 3 Opus.
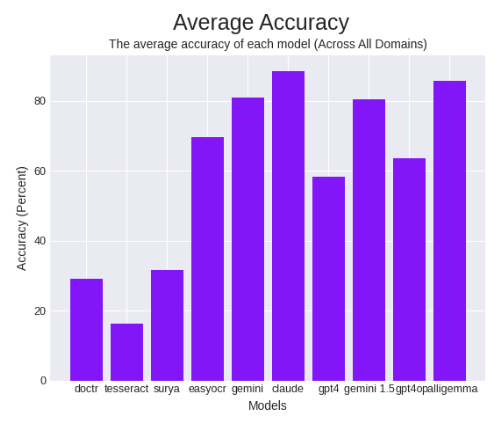
PaliGemma also achieved relatively fast speeds. Combined with the cheaper local nature of the model, PaliGemma seems to be the top OCR model in terms of speed efficiency and cost efficiency.
In median speed efficiency, it beats the previous leader, GPT-4o, set a day earlier when it was released, by a healthy margin. In terms of cost efficiency, PaliGemma outperformed the previous leader, EasyOCR, by almost three times, running more accurately and cheaper.
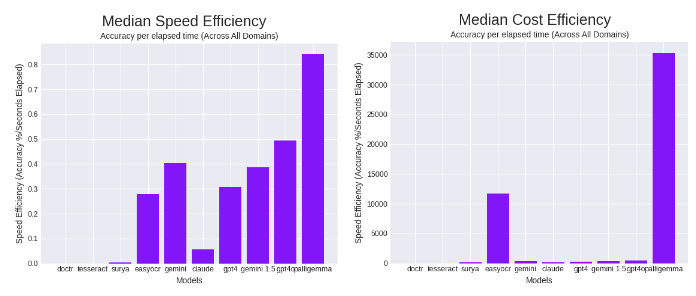
We consider these results to make PaliGemma a top OCR model given the local and more lightweight nature of PaliGemma compared to the models it beat, including the recently released GPT-4o, Gemini, and other OCR packages.
Document Understanding
Document understanding refers to the ability to extract relevant key information from an image, usually with other irrelevant text.
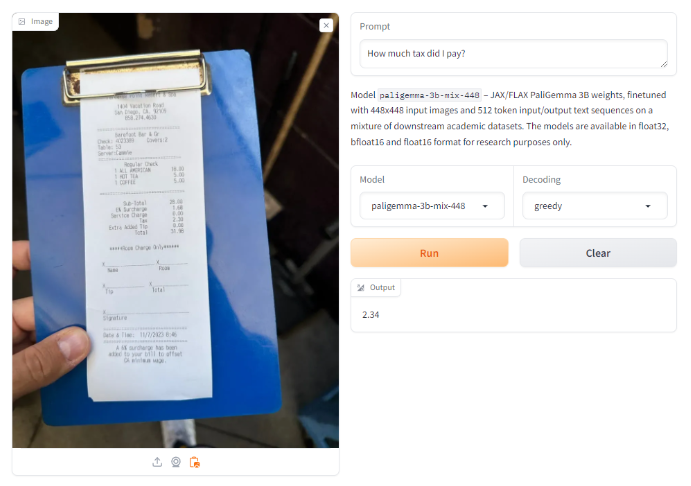
On an image with a receipt, we ask it to extract the tax paid according to the receipt. Here, PaliGemma gives a close but incorrect result consistently across several attempts.
However, on an image with a pizza menu, when asked to provide the cost of a specific pizza, it returned a correct value.
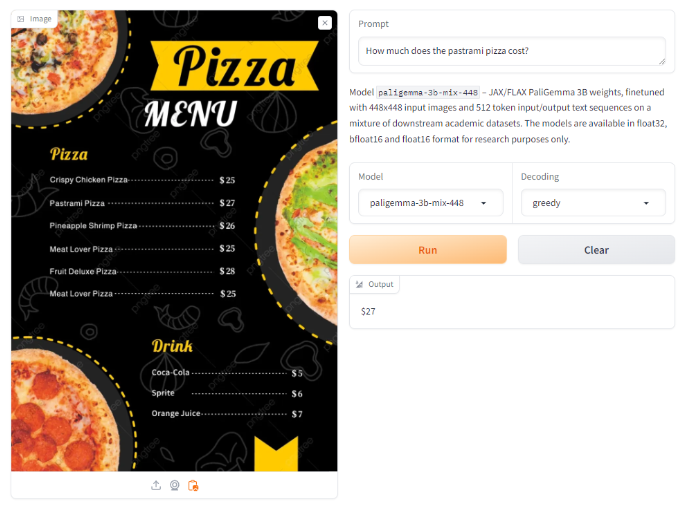
This performs similar or equivalent to the experience we had with GPT-4 with Vision, where it failed tax extraction but answered the pizza menu question correctly. Gemini, Claude 3 and the new GPT-4o did answer both questions correctly, as well as Qwen-VL-Plus, an open source VLM.
Visual Question Answering (VQA)
Visual Question Answering involves posing a model with an image and a question requiring some form of recognition, identification, or reasoning.
When posed with a question on how much money was present in a picture with 4 coins, it answered with 4 coins. A technically correct answer, but the question asked for the amount of money in the image.

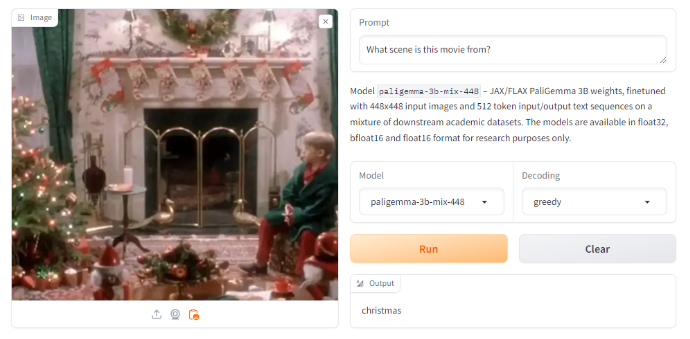
When tasked with identifying a scene featuring Kevin Mcallister from the movie Home Alone, it responded with “christmas”. We consider this to be an incorrect answer.
Object Detection
As we mentioned earlier, VLMs have traditionally struggled with object detection, much less instance segmentation. However, PaliGemma is reported to have object detection and instance segmentation abilities.
First, we test with the same prompt we have given other models in the past. Here, it returns an incorrect, likely hallucinated result.
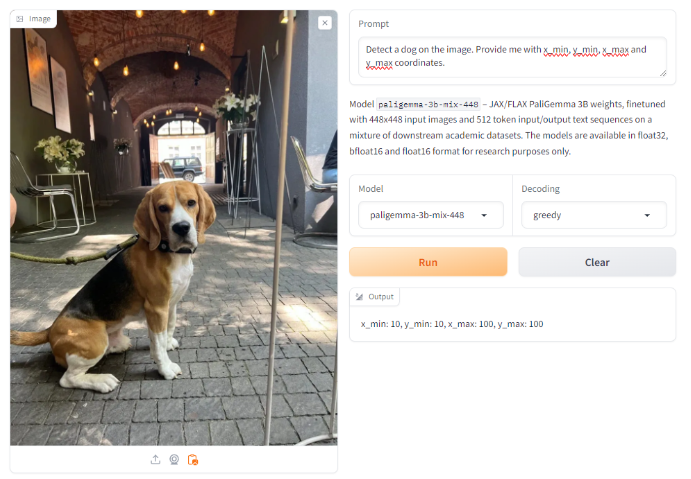
However, when prompting with the keyword `detect`, followed by the object `dog` (so `detect dog`) as detailed in the model documentation, it correctly and accurately identifies the dog in the image. Using the keyword `segment dog` also resulted in a correct segmentation.

Although it is very impressive that a VLM is able to provide object detection and recognition capabilities, it is worth noting that only basic examples, such as those possible with a traditional object detection model, succeeded. When prompted to find cars, (there is a car present visible through the door of the building in the back) it returned no results.
Use Cases for PaliGemma
Whether using PaliGemma zero-shot or fine-tuned on custom data, there are specific use cases tailored to PaliGemma’s strengths that will open the door to new AI use cases. Let’s take a look at a two of them.
Custom Applications
Models like Claude 3, Gemini 1.5 Pro, and GPT-4o are used out-of-the-box and applied to problems they are suited to solve. PaliGemmi brings multimodal abilities to use cases that are still unsolved by closed-source models because you can fine-tune PaliGemma with proprietary data related to your problem. This is useful in industries like manufacturing, CPG, healthcare, and security. If you have a unique problem that closed-models have not seen, and will never see due to their proprietary nature, then PaliGemma is a great entry point into building custom AI solutions.
OCR
As shown earlier in this article, PaliGemma is a strong OCR model without any additional fine-tuning. When building OCR applications to scale to billions of predictions, latency, cost, and accuracy can be difficult to balance. Before PaliGemma, closed-source models were the best-in-class option for performance but their cost and lack of model ownership made them difficult to justify in production. This model can provide immediate performance and be improved over time by fine-tuning on your specific data.
Limitations of PaliGemma
PaliGemma, and all VLMs, are best suited for tasks with clear instructions and are not the best tool for open-ended, complex, nuanced, or reason based problems. This is where VLMs are distinct from LMMs and you will find the best results if you use the models where they are most likely to perform well.
In terms of context, PaliGemma has information based on the pre-training datasets and any data supplied during fine-tuning. PaliGemma will not know information outside of this and, barring any weights updates with new data from Google or the open source community, you should not rely on PaliGemma as a knowledge base.
To get the most out of PaliGemma, and have a reason to use the model over other open source models, you’ll want to train the model on custom data. Its zero-shot performance is not state-of-the-art across most benchmarks. Setting up a custom training pipeline will be necessary to warrant using PaliGemma for most use cases.
Finally, during various tests, we saw drastic differences in results with slight changes to prompts. This is similar behavior to other LMMs, like YOLO-World, and takes time to understand how to best prompt the model. Changes in a prompt, like removing an ‘s’ to make a word singular rather than plural, can be the difference between a perfect detection and an unusable output.
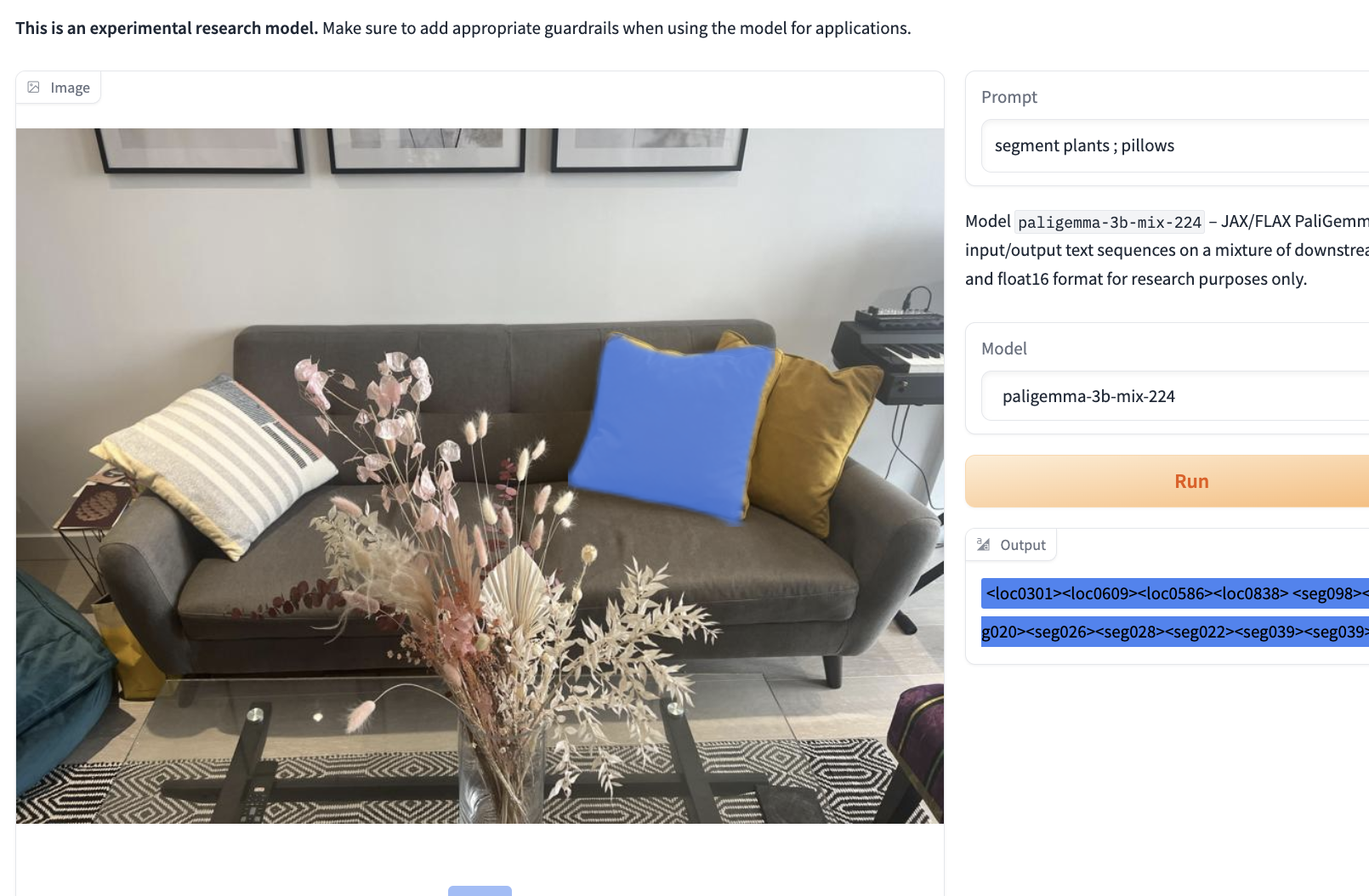
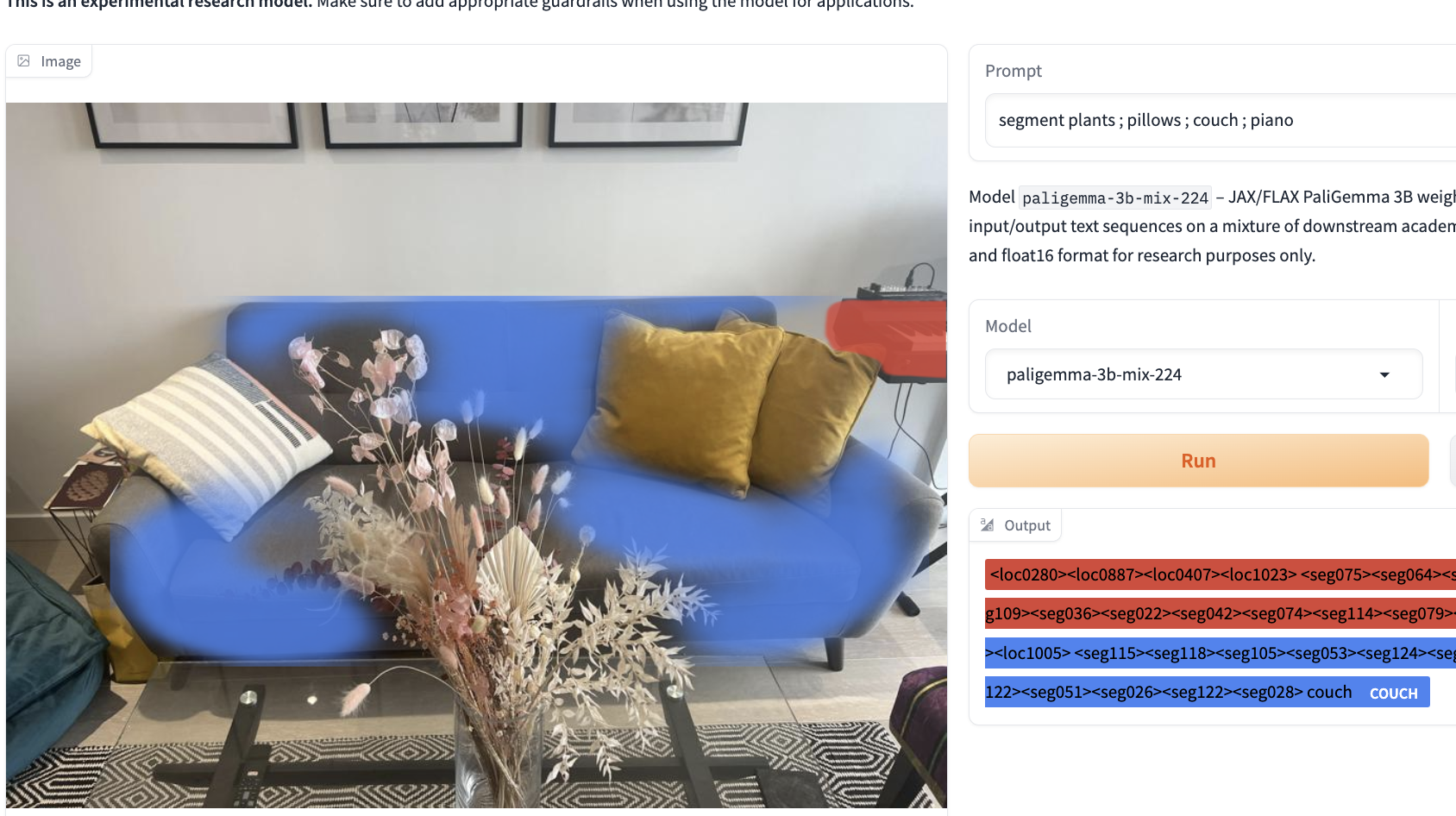
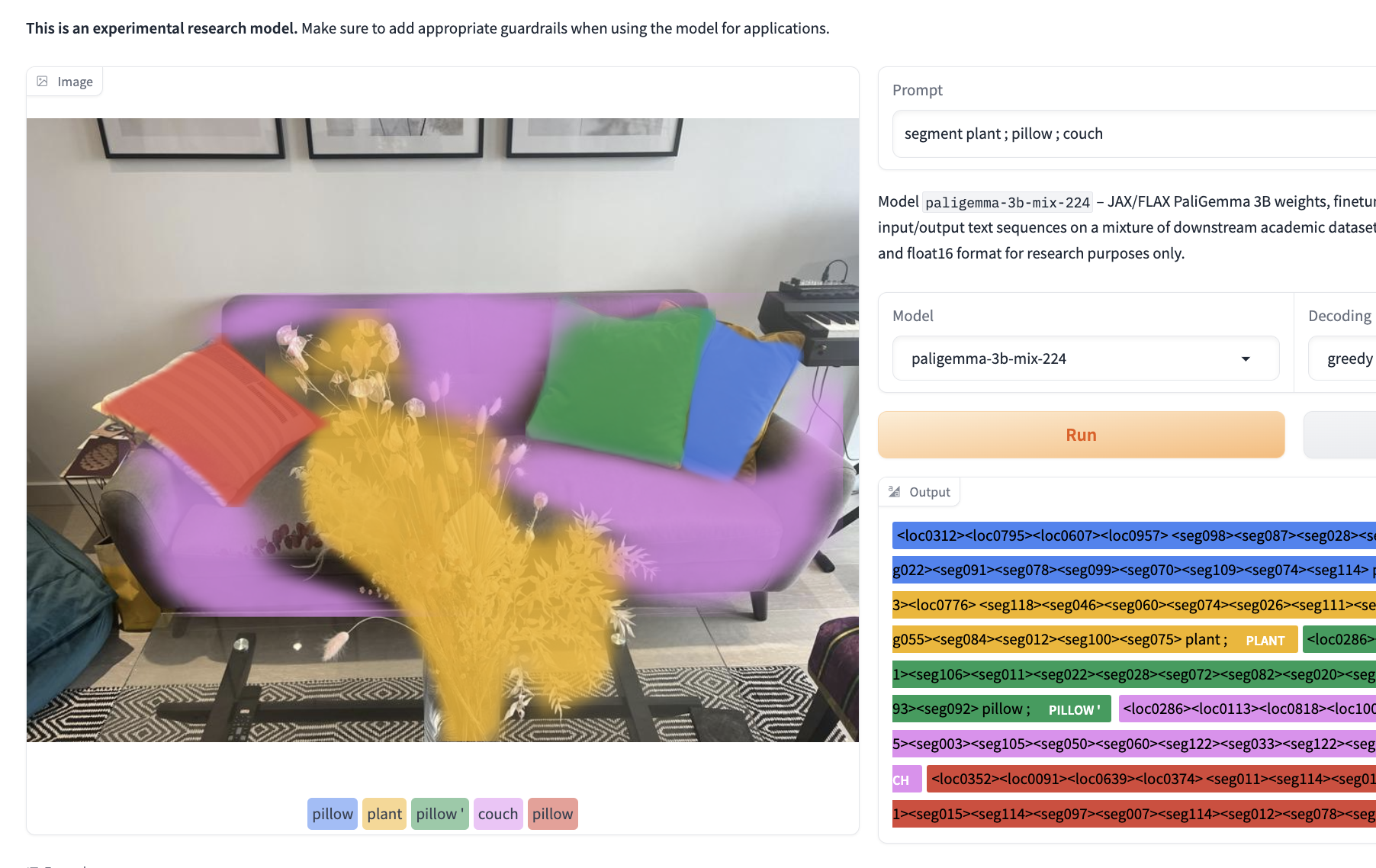
Notice the different results based on plural vs singular nouns
Conclusion
Google’s release of PaliGemma is incredibly useful for the advancement of multimodal AI. The lightweight open model built for fine-tuning means anyone can custom train their own large vision-language model and deploy it for any commercial purpose on their own hardware or cloud.
Previous LMMs have been extremely expensive to fine-tune and often require large amounts of compute to run, making them prohibitive for broad adoption. PaliGemma breaks the mold and offers people building custom AI applications a breakthrough model to create sophisticated applications.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno, Trevor Lynn. (May 15, 2024). PaliGemma: An Open Multimodal Model by Google. Roboflow Blog: https://blog.roboflow.com/paligemma-multimodal-vision/