
When a model is underperforming and more field collection is impractical, merging your dataset with publicly available annotated data is often the fastest way to improve accuracy. This post demonstrates the approach using COCO and OpenImages car images, where doubling the training set by adding 1,000 OpenImages examples raised mean average precision from 47.2% to 50.8%, a 7.5% gain. The method works best when the public dataset shares similar image conditions with your target domain.
Ok, so you've trained a model and it's not doing as well as you'd hoped. Now what? You could experiment with augmentation, try a different architecture, or check your training data for errors. But what if those all fail?
Oftentimes, the single most impactful thing you can do to improve your model is to give it more training data. In this post we explore a quick and easy way to give your model a boost by combining your own custom dataset with publicly available image datasets.
Collecting More Data
The naive solution is to send someone out into the wild with a camera to capture more images. As you would expect, this is an expensive and time-consuming process.
This is why we encourage our customers to get the first version of their model into production as soon as possible so they can use their users to collect real-world data to iteratively improve their model with active learning.
You can also add augmentations, generate synthetic data via context augmentation, 3d renders, or generative adversarial networks (GANs).
But there's another way that can quickly yield improvements: adding annotated images from public datasets. In this post we'll show how we can use data from OpenImages to improve our model's accuracy on a COCO class by up to 7.5%.
The Baseline
We're going to create a car detection model. We'll start by training a baseline model on a subset of 1000 images of cars from the COCO dataset.
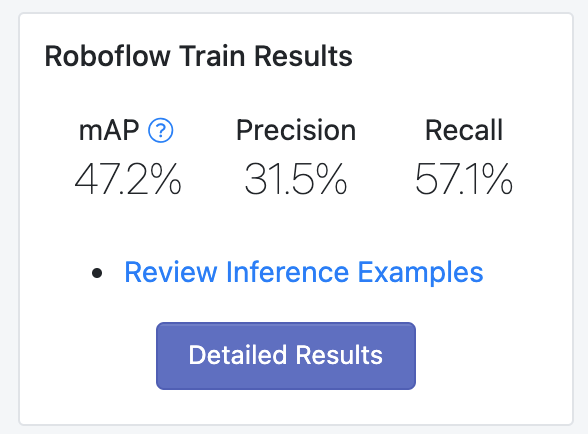
The results from training on COCO alone are pretty good, but we can do better.

Adding Images from a Public Dataset
We're now going to follow the steps from this OpenImages data slicing tutorial to double the size of our dataset by adding an additional 1000 car images from OpenImages to our dataset's training set (making sure to remap Car to car so the model sees them as the same class).
The Results
We re-trained our model with these new images and achieved a 7.5% improvement on our validation set! (From 47.2% mean average precision to 50.8%)
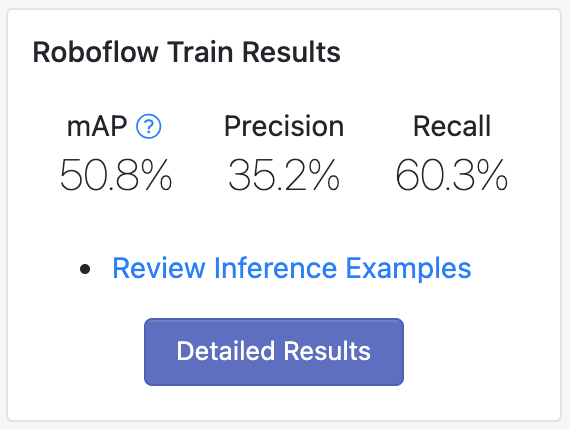
Subjectively, the model performs much better as well. Here's that same image from my camera roll (note how the first model didn't identify the Volkswagen Beetle as a car but this one did).

Limitations
The effectiveness of this method, understandably, degrades the as the size of the original dataset increases. It only works if the problem is that your model doesn't have enough varied examples to work from and the images you feed in are similar enough to your own dataset that your model can extract useful information from it.
Starting with all 12,000 COCO car images yielded 63.4% mAP; adding an additional 5,000 from OpenImages did still improve the results but it only boosted mAP to 63.8% (a 0.6% improvement).
Implications
In just a few minutes we were able to show a marked improvement on our car model just by adding more data from a public dataset. COCO and OpenImages have labeled data for hundreds of classes; if you're looking for similar objects, you're in luck! If they don't have any relevant images have a look at our public datasets page to see if there's another public dataset that might fit the bill.
In addition to adding examples of the things your model is looking for you may also want to add examples of things it is getting confused by. For example, my sign language detection model was identifying human faces as hands because there weren't many in its training examples; I was able to improve its performance by adding images of faces from OpenImages which decreased the number of false positives.
Cite this Post
Use the following entry to cite this post in your research:
Brad Dwyer. (Jan 6, 2021). Using Public Datasets to Improve your Computer Vision Models. Roboflow Blog: https://blog.roboflow.com/using-public-datasets/