
With advancements in multimodal foundation models, auto-segmentation techniques, and synthetic data generation, accurate AI data labeling remains a crucial component of production-ready AI systems. Clean, precisely annotated datasets directly determine a model’s accuracy, compliance readiness, iteration speed, and ultimately, real-world performance.
Today, teams have to confront complicated labeling situations that include manual annotation, semi-automated tools, and fully synthetic pipelines. Each of these has its own pros and cons in terms of cost, accuracy, and scalability.
Mastering your labeling workflows will provide your organization a decisive competitive advantage, whether you deploy surgical robots that need pixel-perfect annotations or train retail analytics models with millions of data points.
What is data labeling and why does it matter?
Data labeling is the practice of annotating images, videos, or multimodal data (text-in-image, LiDAR, etc.) with metadata or descriptive tags that computer vision models use to learn and generalize.
Common labeling formats include:
- Bounding boxes (bbox): Simple rectangular annotations around objects.
- Polygon annotation: Complex shapes outlining objects precisely.
- Semantic and instance segmentation: Pixel-level masks defining class and instance details.
- Keypoint labeling: Marking individual points (e.g., joints in pose estimation).
- Captioning and OCR: Descriptive text labels or text transcription within images.
- Multimodal annotations: Combined annotations involving multiple data modalities (e.g., text prompts aligned with visual regions).
Robust labeling provides the semantic context required for model training, which can help your AI apps to interpret visual input accurately.
Why is data labeling still important in 2025?
Large multimodal models may ingest pixels, tokens, and embeddings, but their ground truth still comes from labeled data. Even the best vision-language models, VLMs (SAM, Grounding-DINO, GPT-4o-vision, etc.), still rely on high-fidelity labeled data for:
- Fine-tuning/domain adaptation: Aligning generic encoders to your edge cases.
- Evaluation and regression testing: You can’t trust mAP/ROUGE/BLEU without trustworthy ground truth.
- Token quality: “Vision tokens” passed into LLMs inherit every upstream labeling flaw (garbage in, garbage reasoning out).
A single noisy class definition or mislabeled cluster can bias feature learning and silently cap mAP/F1, no matter how strong the backbone is.
In short, labeling accuracy directly translates to real-world model reliability, regulatory compliance, and user trust.
What are the trends currently shaping data labeling?
Four major trends have elevated the complexity and sophistication of data labeling workflows.
1. LLM-Generated “Pseudo-labels”
- Multimodal foundation and VLMs generate initial labels that people then improve to ensure they are high quality.
- For example, SAM/Grounding-DINO handles masks and boxes, while GPT-4o Vision handles captions and layout hints.
- Benefits: Rapid bootstrapping, faster cold starts.
- Caveat: Trust but verify because systematic errors propagate if unchecked.
2. Synthetic Video and 3D Data Explosion
- Game engines (Blender, Unity), Neural Radiance Fields (NeRF) pipelines, and LiDAR simulators produce perfectly labeled edge cases and rare events.
- Benefits: Datasets offer huge variability at reduced cost.
- Caveat: Careful management of domain adaptation is necessary to avoid performance degradation due to distribution shifts (domain gaps).
3. Multimodal Tasks Proliferation
- Tasks that analyze visual, textual, and sensory inputs at the same time (like text-in-image grounding, chart QA, and vision-language alignment) show that labels now need to represent meanings and relationships (semantic + relational), not just locations (spatial).
- Benefits: Great for use cases like captioning for accessibility and product attribute extraction.
- Caveat: Each modality requires coherent labeling strategies, which makes unified labeling tools and frameworks essential.
4. Compliance and Audit Requirements
As regulatory oversight intensifies, particularly under frameworks like the EU AI Act, traceable labeling workflows have become mandatory. Regulations demand:
- Traceable labels (who labeled what, when, and how).
- Versioned schemas and audit logs (are also important to monitor label drifts on the development side).
Data lineage: To tie each model prediction back to a labeled example.
Accurate and transparent labeling is now as much a compliance requirement as a technical necessity.
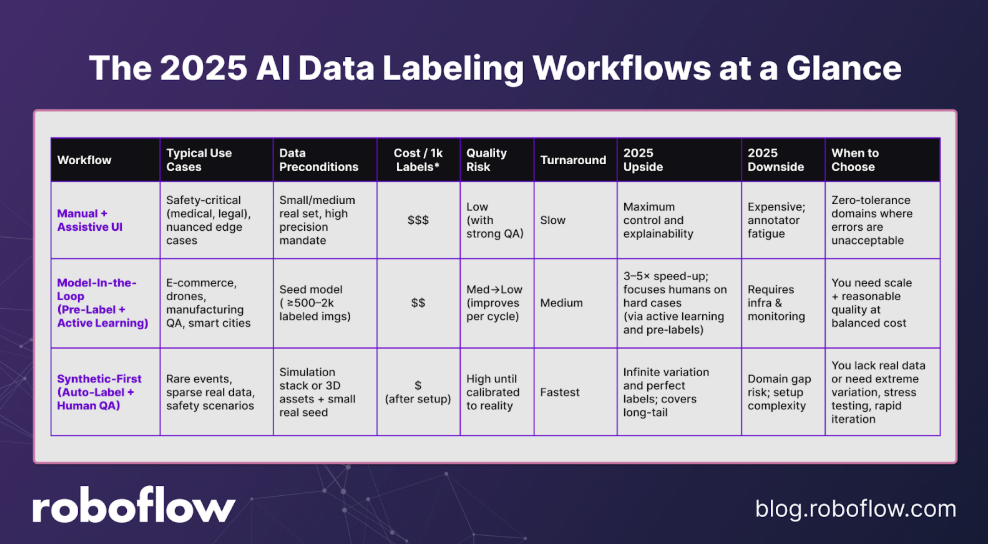
Introducing Three Core Labeling Workflows
Teams now commonly employ one (or a blend) of these labeling workflows:
- Workflow 1: Manual + Assistive UI: Human annotators do primary labeling using intuitive interfaces and tools (shortcuts, snapping, templates) to accelerate the process.
- Workflow 2: Model-In-the-Loop (Pre-Label + Active Learning): Models (e.g., SAM, CLIP-based retrieval) pre-label; uncertainty/diversity sampling sends “hard” samples to humans to refine (active learning).
- Workflow 3: Synthetic-First (Auto-Label + Human QA): Generate labeled synthetic data at scale; humans audit and calibrate against real samples.
Choosing the optimal workflow depends heavily on your accuracy requirements, data complexity, labeling budget, and compliance constraints.
Here’s how these strategies compare, at a glance:
Workflow #1: Assistive AI Data Labeling Tools
When every pixel (or character) matters, think medical imaging, legal discovery, or safety-critical robotics, you still rely on humans.
The win is pairing expert annotators with assistive UI, hotkeys, auto-checks, and tight QA loops to keep precision high without bleeding budget.
Use Cases
Manual + assistive labeling workflows excel in complex, high-stakes scenarios such as:
- Medical and biomedical (tumor boundaries, histopathology slides): Annotating sensitive medical scans (X-rays, MRI) requires precision and interpretive nuance only achievable with expert human review.
- Legal and compliance docs (OCR + redaction accuracy, contract clause tagging): Labeling documents for compliance or litigation requires context understanding, precise boundary marking, and minimal error tolerance.
- Edge-case heavy domains (rare defects in manufacturing, surgical robotics, defense): Specialized tasks or subtle object distinctions that automated models consistently struggle to differentiate without human insight.
- Schema-volatile projects: Labels evolve frequently; humans must interpret nuance.
These use cases prioritize quality and accuracy above automation-driven scale.
Common Pitfalls
However, reliance on manual labeling is not without drawbacks:
- Annotator fatigue and inconsistency: Repetitive, detail-oriented tasks can quickly degrade annotator performance and introduce human errors, impacting overall dataset quality.
- Schema creep: Class definitions evolve silently; older labels no longer match.
- Hidden bias: Different annotators interpret ambiguous classes differently.
- High cost and slow throughput: Purely manual labeling scales poorly without support tools with optimal UI and UX.
Mitigations: Shorter shifts, rotating annotators, periodic calibration tasks (“golden set” checks), explicit schema change logs, and ergonomic tooling to cut clicks/time.
Use Roboflow Annotate: Maximize precision without drowning in clicks—Roboflow’s assistive layer shortens each annotation action and centralizes QA. Here's how:
- Fast label UI: Class pickers, polygon tools, mask editing, and smart snapping to keep annotators efficient.
- Keyboard shortcuts and templates: Bulk-apply labels, duplicate/propagate annotations across frames
- QA queues and inter-annotator review: Assign second-pass reviewers, compare annotator agreement, flag conflicts for resolution, and track approval rates
- Versioning and auditable history: Every change logged; schema diffs visible for compliance.
Quality Assurance and Metrics
In manual labeling, robust QA mechanisms and clearly defined quality metrics are essential. Teams should routinely track and optimize the following metrics:
Inter-annotator agreement (IAA):
- What: Degree to which different annotators agree.
- How: Use Krippendorff’s α for nominal/ordinal/interval data (robust to multiple annotators and missing data).
- Target: α ≥ 0.80 for general CV tasks (≥ 0.85 for medical/safety-critical).
- Action: If α drops, trigger a calibration session or clarify guidelines.
Golden set error rate:
Maintain a hidden, expertly labeled subset (“golden set”). Periodically sample annotators’ work and compute % deviation from gold labels.
- Error target: >2% error? Investigate fatigue, unclear schema, or tooling friction.
- Fix: Trigger retraining, tune for your domain, or guideline update.
Annotation time per image (throughput KPI):
Track median seconds/image (or per object) to quantify ROI of assistive features.
- Benchmark how long a manual annotation takes ⇒ after adding shortcuts or templates (pre- and post-shortcut adoption) and % reduction to justify investments.
- Use “seconds per bbox/polygon” as a micro-metric to detect UI bottlenecks.
Optional metrics:
- Review latency: Time between first label and QA approval. Long tails signal bottlenecks in review staffing or processing.
- Schema drift checks: Monitor class frequencies and definition changes over time. Sudden shifts indicate guideline confusion or real distribution change.
These QA metrics help maintain high annotation standards, manage annotator productivity, and provide concrete benchmarks for continual improvement.
Let’s move on to the next workflow: semi-automatic labeling with SAM, CLIP, and active learning.
Workflow 2: Semi-Automatic Labeling with SAM and CLIP + Active Learning
Semi-automatic labeling workflows, or "model-in-the-loop" labeling, strategically combine the speed of AI-powered auto-labeling with targeted human oversight.
This workflow reduces the manual labeling workload significantly (often by 3–5×) by using foundation models (SAM, CLIP) to handle routine labeling tasks while leveraging active learning to identify complex cases for expert review.
You front-load speed (SAM masks, detector bboxes, captioners) and spend human time only where the model is unsure.
Roboflow’s Label Assist in Action
Roboflow’s Label Assist uses foundation (AI) models like SAM and Grounding-DINO or your custom models to quickly produce accurate, preliminary annotations.
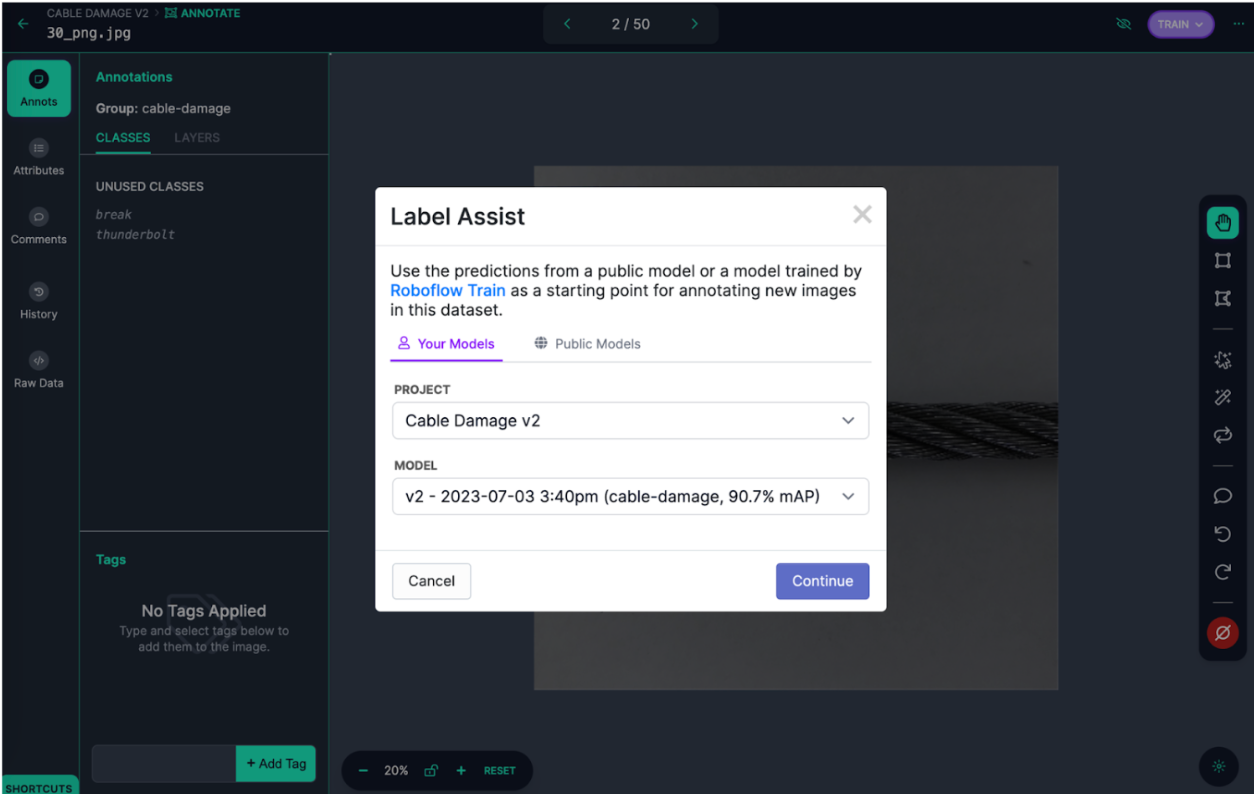
Annotators then refine these auto-generated labels in a fraction of the time traditional manual labeling requires. Label Assist bulk-runs SAM masks, exposes confidence scores, and queues “hard” samples via Annotate.
Here’s the general step-by-step approach:
- Model-backed pre-labeling: Run a seed model (e.g., SAM for masks, Grounding‑DINO for boxes) to auto-generate first-pass annotations.
- Label propagation and interpolation: For videos or image sequences, propagate edits across adjacent frames; interpolate masks instead of redrawing.
- Confidence-based sampling: Route only “hard”/low-confidence images to humans; high-confidence ones pass with lightweight spot checks.
- Click-to-refine: Annotators adjust edges and merge/split instances with a single click instead of full redraws; accept/reject suggestions inline.
Example Use Case: In drone-based agricultural analytics, Roboflow generates initial masks around crop fields or pest infestations. Human annotators can quickly correct minor inaccuracies with just a few clicks, which significantly accelerates overall throughput.
Here’s a video tutorial we put together to show you how it works:
Active Learning Loop
Active learning systematically improves dataset quality and model performance by iteratively identifying the most informative unlabeled data points (those the model is least certain about), directing annotator attention precisely to these critical cases.
Roboflow’s Workflows feature provides integration for this active learning workflow.
How Active Learning works:
Active learning is an iterative cycle:
- Seed model: Train on your initial labeled subset.
- Predict unlabeled pool: Run inference to get scores.
- Score uncertainty and diversity:
- Uncertainty: entropy, margin sampling, or variance of predictions.
- Diversity: embedding-based clustering (e.g., CLIP) to avoid labeling near-duplicates.
- Hybrid: Uncertainty first, then prune to diverse subset.
- Select batch (2–5% of pool): Send only the most informative samples to humans (e.g., top 2–5% uncertain + diverse samples).
- Humans refine and approve: Fix model mistakes; lock in high-quality labels.
- Retrain and evaluate: Measure the mAP/IoU lift on the frozen validation set.
- Repeat until gains plateau or budget hits limit (e.g., <0.5 mAP improvement over 2 cycles).
Here’s a detailed tutorial we created on how to build active learning pipelines that utilize production data for training your next computer vision model.
Active Learning KPIs
Key metrics help teams measure the effectiveness of semi-automatic labeling workflows and iterate for maximum impact. Track these per iteration (cycle t vs. cycle t-1):
- Auto‑label vs. Human Precision/Recall Δ: Measure improvement against a stable, held-out validation set after each active-learning cycle to quantify accuracy gains; Measure Precision/Recall on a frozen validation set; Watch for convergence: ΔPrecision, ΔRecall → ~0 indicates diminishing returns.
- Label Throughput Gain: Track the number of labels completed per hour (e.g., images/hour or masks/hour) compared to fully manual workflows. Expect 3–5× efficiency gains with active learning and AI-assisted labeling tools.
- mAP vs. Iteration Curve: Plot mAP (or F1) over AL cycles; annotate when you cross acceptance thresholds. Expect diminishing returns → define stop criteria.
- % Pool Labeled vs. Performance: % of selected “uncertain” samples that actually contain model errors. This KPI gauges how well your sampling strategy works (shows how little you had to label to hit your production KPI).
Regularly reviewing these KPIs ensures teams clearly visualize productivity improvements and identify when the active learning loop reaches diminishing returns.
Next, let’s look at the third workflow covering synthetic generation, auto-labels, and human QA triggers.
Workflow 3: Fully Automated & Synthetic Data Pipelines
Fully automated and synthetic data pipelines give businesses the best scalability, quick turnaround, and wide range of options.
When you don’t have enough real data, your edge cases are impossibly rare, or you need tight control over scene factors (lighting, pose, occlusion, and backgrounds), a synthetic-first pipeline can slash time-to-first modeling while giving you perfect labels.
Such versatility also makes them perfect for covering long-tail cases like rare defects, dangerous driving scenarios, and medical rarities.
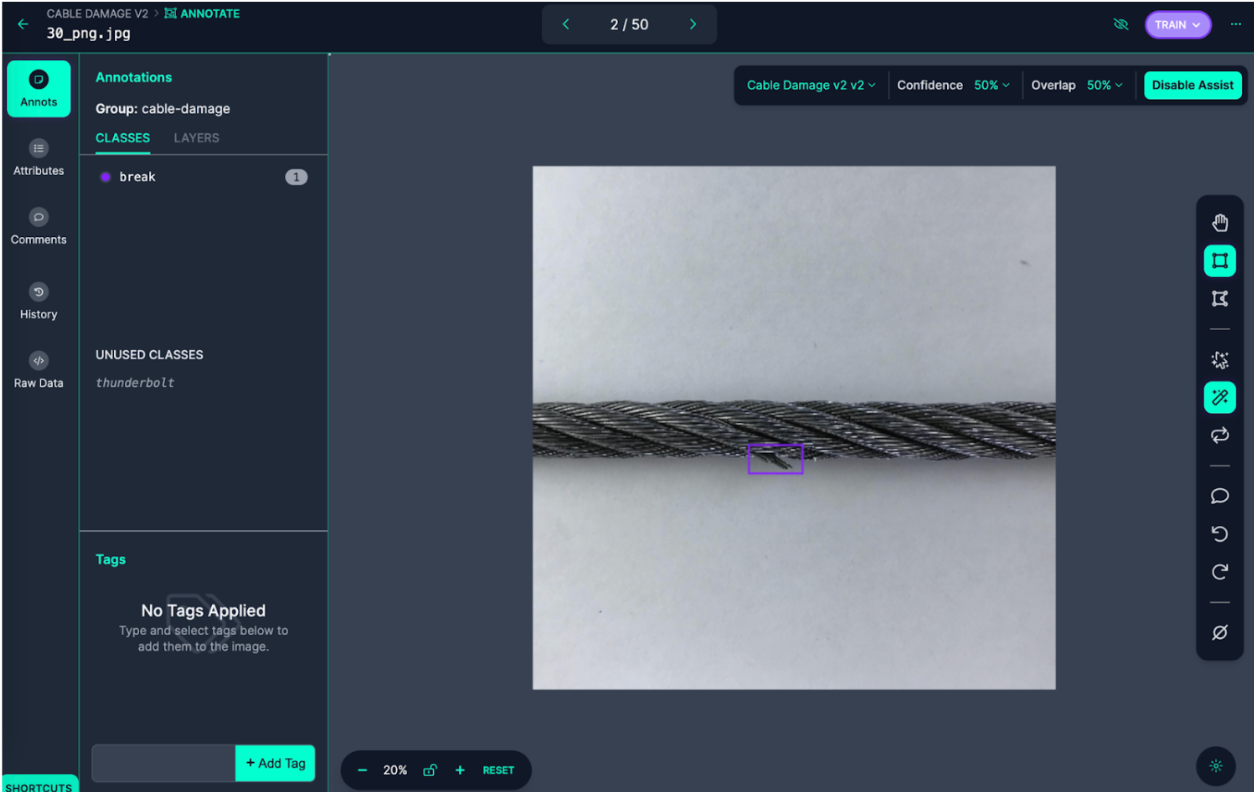
Synthetic data has a lot of potential. But it also comes with risks, especially when it comes to domain gaps and semantic drift. Teams that do well find the right balance between automation and planned human QA interventions.
Generate and Validate Data
Diverse synthetic data generation strategies
Organizations increasingly use advanced synthetic data generators such as Unity, Blender, NVIDIA Omniverse, and Neural Radiance Fields (NeRF).
These platforms can simulate realistic scenarios, including varied lighting conditions, textures, and camera perspectives, essential for robust AI training.
Common synthetic data generation approaches include:
- 3D scene simulations: Create digital replicas of real-world environments, such as warehouses, retail spaces, or cityscapes.
- Domain randomization: Randomly vary textures, lighting, sensor noise, and camera angles within synthetic scenes to promote model generalization.
- Programmatic scene graphs: Scripted object placement to guarantee class balance and edge cases.
- NeRFs and 3D Gaussian splatting: Reconstruct scenes from sparse captures, then re-render novel viewpoints for dense supervision.
- Video synthesis: Simulate motion blur, occlusions, and temporal continuity for tracking tasks.
- Physics-based rendering: Generate highly realistic synthetic imagery, crucial for tasks such as autonomous driving and medical imaging.
Auto-labeling ground truth
One critical advantage of synthetic datasets is automatic, pixel-perfect annotations directly generated by the simulation software. Annotations are inherently accurate, covering bounding boxes, polygons, segmentation masks, and keypoints without human intervention.
Synthetic engines emit perfect annotations by construction (bbox, polygons, segmentation masks, depth maps, optical flow, keypoints) directly from the renderer.
No human is needed to create labels. The work shifts to verifying that they transfer well to real data.
Validate with quantitative similarity/drift scores
- Embedding similarity filtering: Compute image embeddings (e.g., CLIP ViT-L/14) for synthetic vs. real validation data; flag samples beyond a tuned percentile (e.g., <5th percentile similarity).
- Domain gap metrics:
- FID/KID between feature distributions (for 2‑D).
- Downstream metric proxy: Train a small proxy model on synthetic only; evaluate on a tiny real validation set to estimate domain gap (e.g., “mAP drop = 6.2 pts”).
- LLM‑Judge (Optional/Experimental):
- Use a VLM (e.g., CLIP, GPT‑4o‑vision) to check semantic alignment between scene metadata (captions/prompts) and rendered images.
- CLIPScore (text↔image similarity) can flag semantic drift, but set thresholds empirically (e.g., < P10 of real distribution ⇒ send to human QA).
- Treat it as heuristic triage, not a ground-truth arbiter.
Here’s a typical workflow:
- Generate synthetic data (e.g., Unity/Blender).
- Compute CLIPScore: Calculate embedding similarity scores between generated images and reference real-world datasets.
- Flag outliers: Automatically tag images scoring below a predetermined threshold (e.g., CLIPScore < 0.8) for human review, thereby reducing model training risks.
When to Insert Human Quality Assurance (QA)
While fully automated synthetic pipelines greatly reduce manual annotation overhead, targeted human validation remains essential, particularly when precision and compliance demands are high.
Use the decision table below to identify when human intervention is critical:
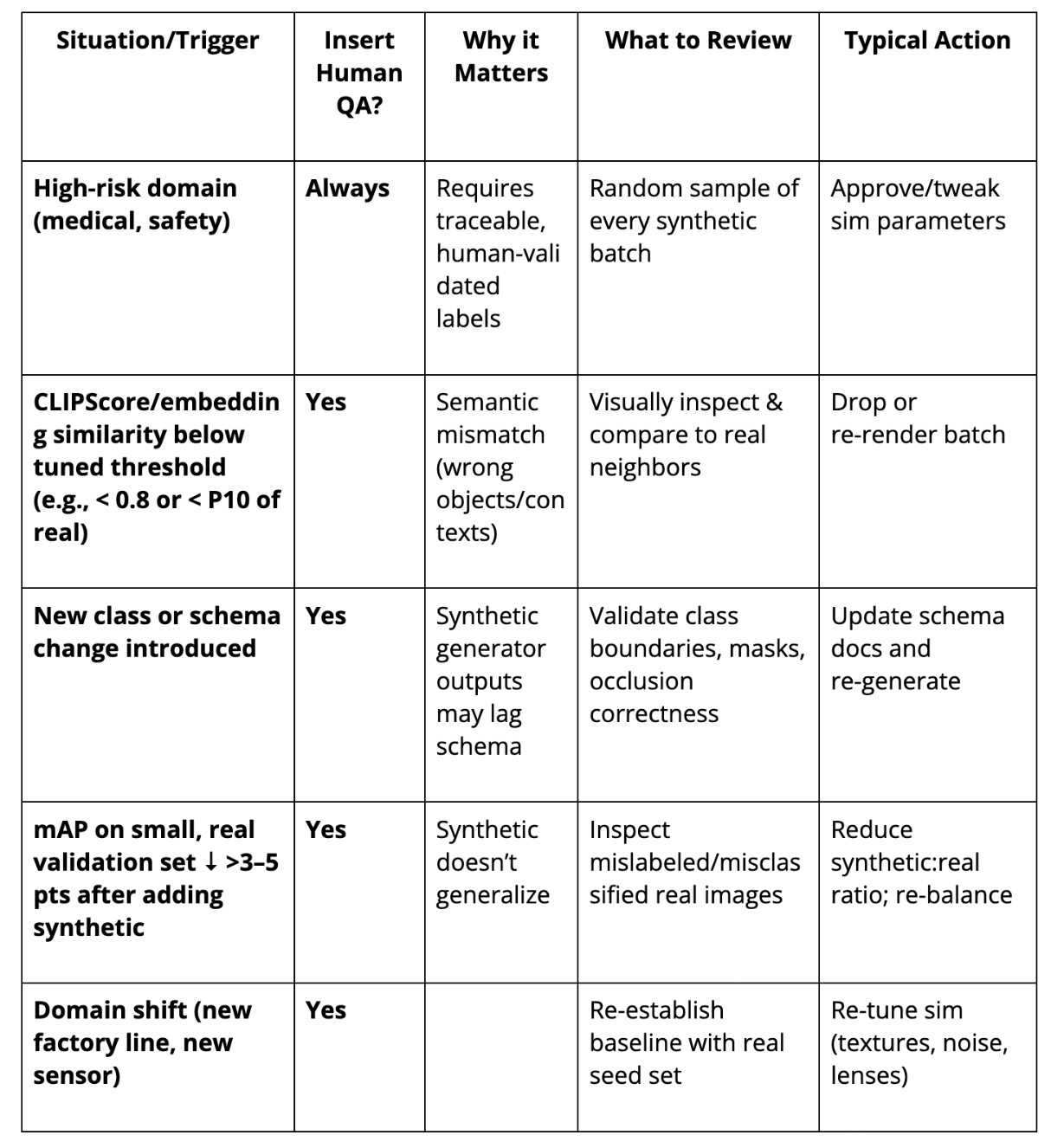
Strategically embedding human QA at these trigger points ensures dataset integrity, compliance readiness, and sustained model accuracy.
Practical Blend: Synthetic ↔ Real
- Warm-start with a small real seed (e.g., 500–2k images) to calibrate the synthetic generator.
- Ratio schedule: Begin 70:30 synthetic:real, and decay to 50:50 (or lower) as you scale real-world feedback.
- Weighted training or curriculum: Weight real examples higher in loss or stage training (pretrain on synthetic → fine-tune on real).
- Style transfer/domain adaptation: Reduce texture gap (e.g., AdaIN, CycleGAN) if synthetic photorealism lags.
Metrics and Monitoring You Need
- Domain gap score: Choose one primary metric (e.g., mAP@0.5 real‑val drop, or FID vs. real) and track per iteration.
- Coverage/rarity score: % of long-tail scenarios (rare classes, extreme poses) covered by synthetic data.
- Synthetic:real ratio over time: E.g., start 80:20 → converge to 50:50 as you collect more real feedback.
- QA Hit Rate: % of synthetic samples that fail human checks; should fall as your simulation pipeline matures.
- Post-deployment label drift: Compare embedding distribution of new, human-labeled production samples vs. original training set.
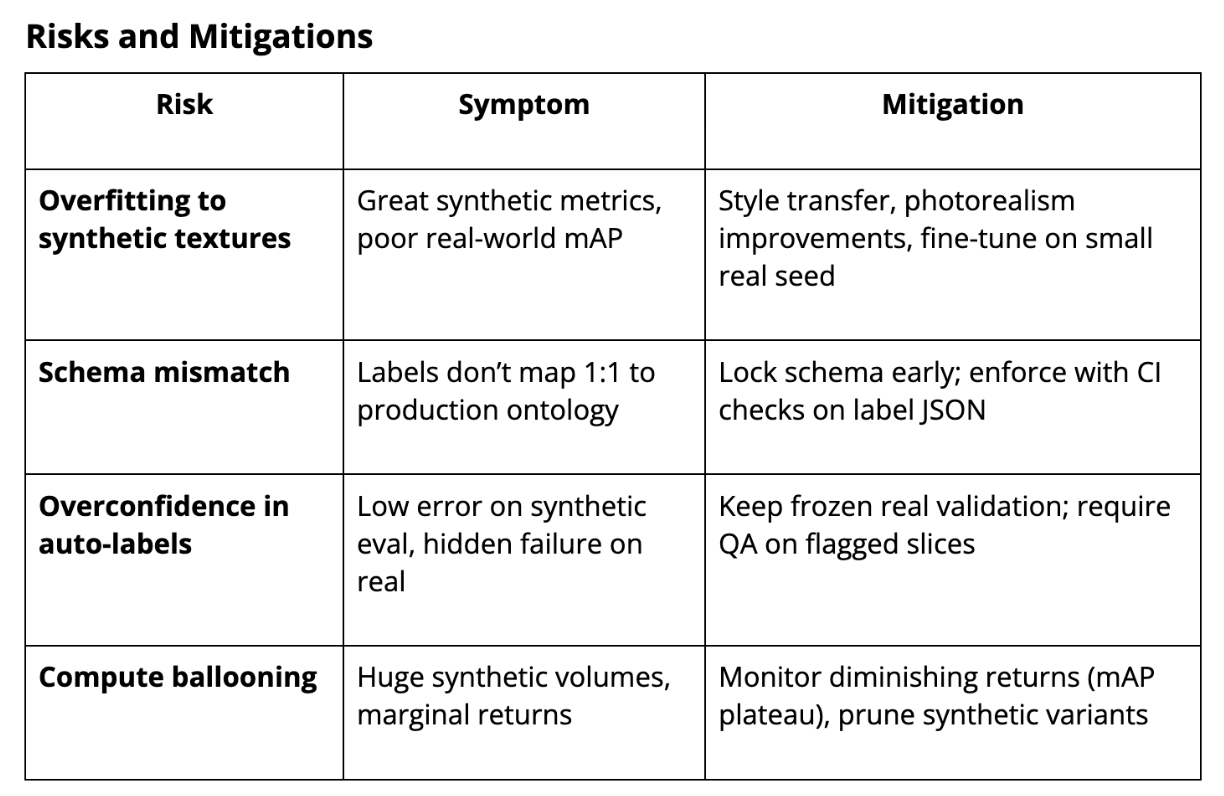
AI Data Labeling Tools
Not all labeling platforms are created equal. If you need governance, auditability, and speed, Roboflow’s end‑to‑end platform (plus Label Assist + QA dashboards) will cut the most time to value.
Roboflow Annotate stands out as one of the most powerful AI-assisted image labeling tools available. It allows users to manually draw bounding boxes or polygons, or boost efficiency using Label Assist, which applies your own model checkpoint to pre-label images automatically. For even more precise segmentation tasks, Roboflow provides Smart Polygon, leveraging Meta’s Segment Anything Model (SAM 2) to generate clean annotations in just a few clicks.
On top of these intelligent annotation tools, the platform includes full dataset management features: semantic search, class filtering, automated analytics to find edge cases, and role‑based team collaboration with assignment workflows, approval queues, and version history. It’s built for real-world scale: handling millions of images across teams while keeping labeling accurate, efficient, and auditable .
AI Data Labeling Conclusion
High-quality labels remain the most reliable lever for production accuracy, compliance, and iteration speed, even in the era of foundation models, SAM, and synthetic data.
The winning strategy isn’t “manual vs. auto,” it’s orchestrating the right blend of Manual + Assist, Model-in-the-Loop active learning, and Synthetic-first pipelines, with measurable quality gates and auditable governance.
If you implement the 10-step playbook above, expect to:
- Cut labeling costs likely by 20–40%,
- Lift mAP by +2–5 points via active learning & QA loops, and
- Shorten iteration cycles by automating what machines do best and reserving humans for what truly matters.
What to Do Next
Ready to experience these workflows firsthand? Test and fork the active learning loop with Roboflow Workflows and track mAP lift per iteration.
What to Read Next
Deepen your expertise further with these essential resources:
- Active Learning Guide: Maximize labeling efficiency with iterative uncertainty sampling.
- Label Assist Tutorial: Accelerate manual labeling using AI-powered auto-labeling tools.
- Roboflow QA Docs: Maintain dataset quality with advanced QA tools and workflows.
- How to Monitor Label Drift in Production: Detect and mitigate dataset drift effectively in production scenarios.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Jul 28, 2025). AI Data Labeling Guide. Roboflow Blog: https://blog.roboflow.com/ai-data-labeling/