
This tutorial builds a blood cell detection app that trains an object detection model in Roboflow to identify platelets, red blood cells, and white blood cells, then wraps the model's API in a Streamlit interface so users can upload images, adjust confidence thresholds with a slider, and see bounding box predictions update in real time. Streamlit's sidebar and widget components map closely to their Python function names, keeping the glue code minimal. The finished app is deployable directly from a GitHub repository and illustrates how Roboflow's hosted inference API can feed any Python-based front end without additional infrastructure.
Building an app for blood cell count detection.

Most technology is designed to make your life, or your work, easier. If your work involves building computer vision into your applications, using the Roboflow platform gives you everything you need.
Streamlit is an open-source platform that enables you to convert your Python scripts to apps and deploy them instantly. Streamlit and Roboflow can work hand-in-hand, allowing you to tackle computer vision problems and visualizing your output so you can make better decisions faster.
In this post, we’ll walk you through using Roboflow and Streamlit together by showing you how to:
- Fit an object detection model in Roboflow
- Use an API to access the model and its predictions
- Create and deploy a Streamlit app
Specifically, we’ll be working with a common blood cell count and detection dataset. If you want to skip right to playing with it, here's an interactive app and this is the code.
We’ll build an object detection model that detects platelets, white blood cells, and red blood cells. Then, the app we develop together will allow you to make predictions with your object detection model, visualize those predictions at a given confidence level, and edit those predictions based on your preferred confidence level with immediate visual feedback.
How to fit an object detection model in Roboflow
Have you fit an object detection model before?
Even if you haven't, Roboflow helps you work through all aspects of computer vision, from uploading, annotating, and organizing your images to training and deploying a computer vision model.
We believe you shouldn’t have to be a data scientist or need an extensive coding background to be able to use computer vision. You have everything you need right now.
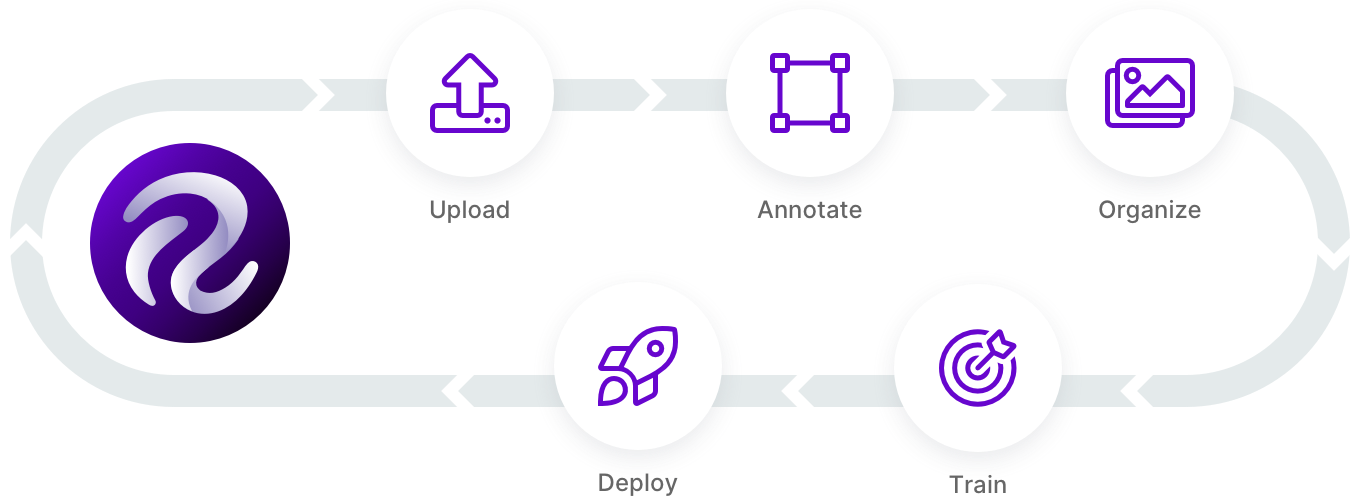
If you don’t already have a Roboflow account, you’ll need to head over to Roboflow and create one. If you’d like to start training your model from a public dataset, Roboflow has a great tutorial that describes how to improve your model more quickly. (Or, you can upload your own dataset!)
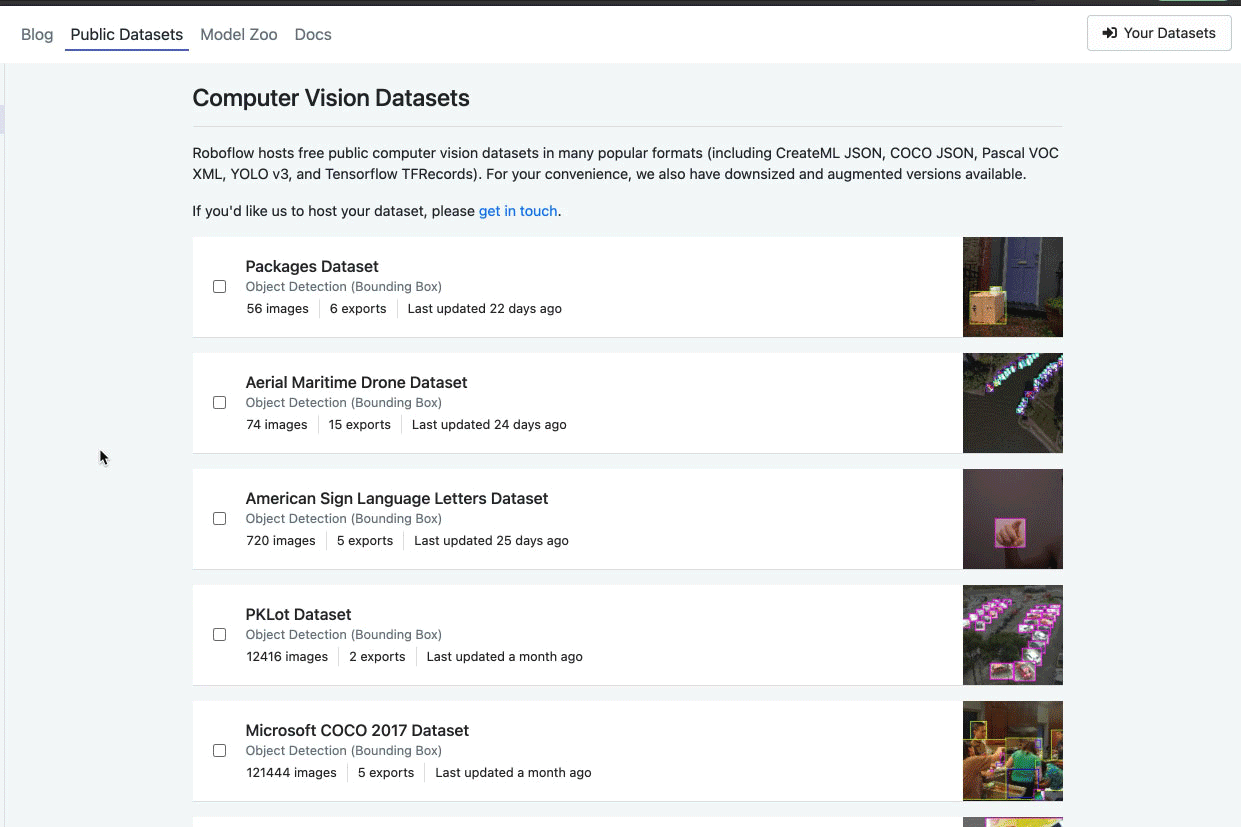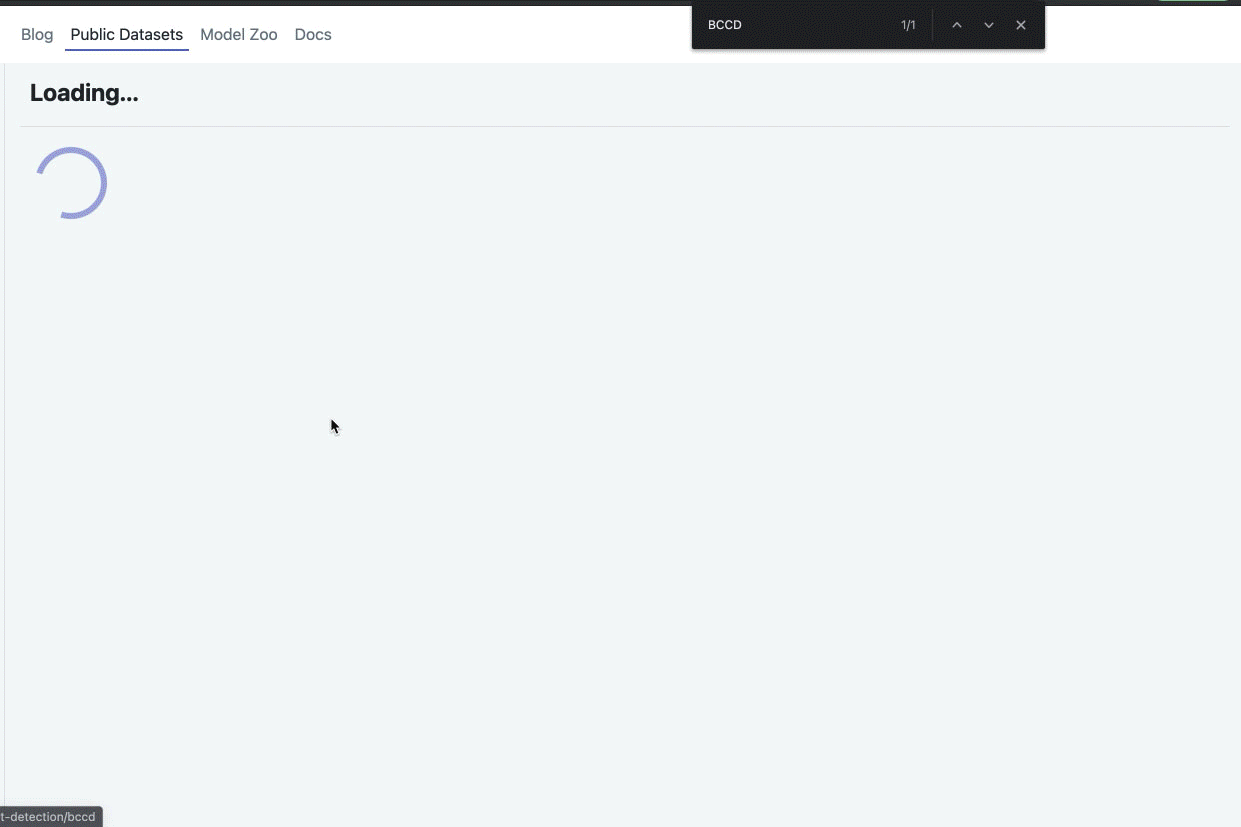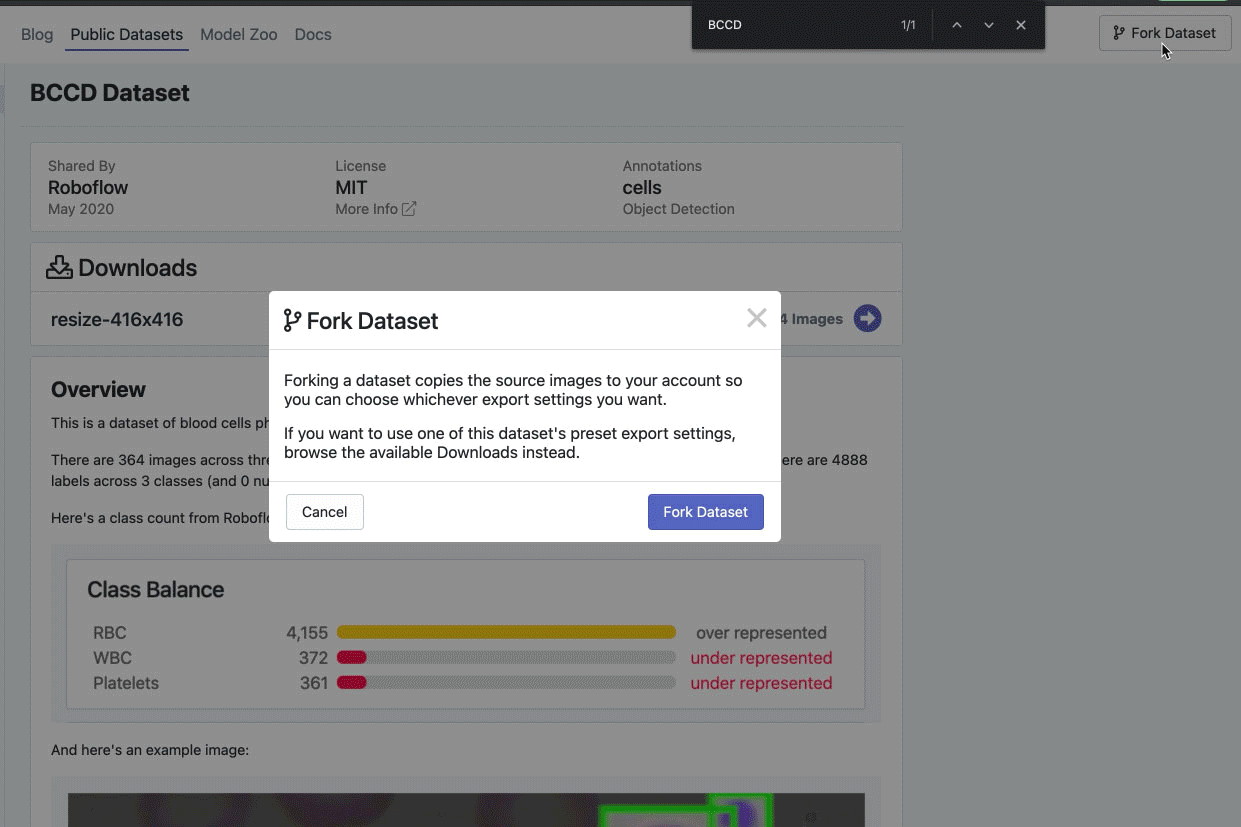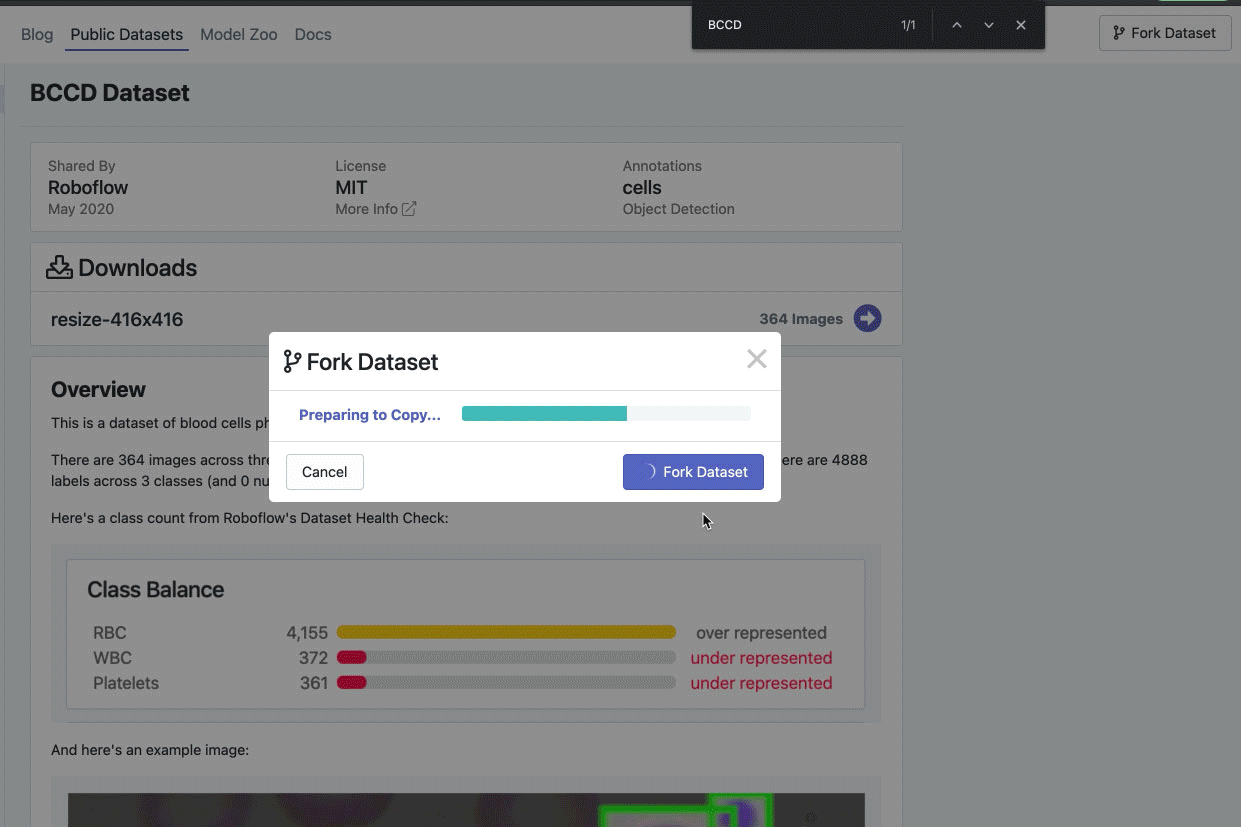
Once you have an account, go to our computer vision datasets page. We’ve made over 30 datasets of different types public and keep adding more.
The one we’ll walk through today is a blood cell count and detection dataset.
After you’ve decided which dataset to use, go ahead and fork it. That will create a copy of the dataset that you can now use.
At this point, you can directly fit a model. However, we recommend that you preprocess and augment your images.
- Image preprocessing. Deterministic steps performed to all images prior to feeding them into the model. For example, you might resize your images so they are all the same size, or convert your images to grayscale.
- Image augmentation. Creating more training examples by distorting your input images so your model doesn't overfit on specific training examples. For example, you may flip, rotate, blur, or add noise to your images. The goal is to get your model to generalize better to “the real world” when you deploy your model.
With the blood cell count dataset I’m using, I chose the following preprocessing and augmentation options:
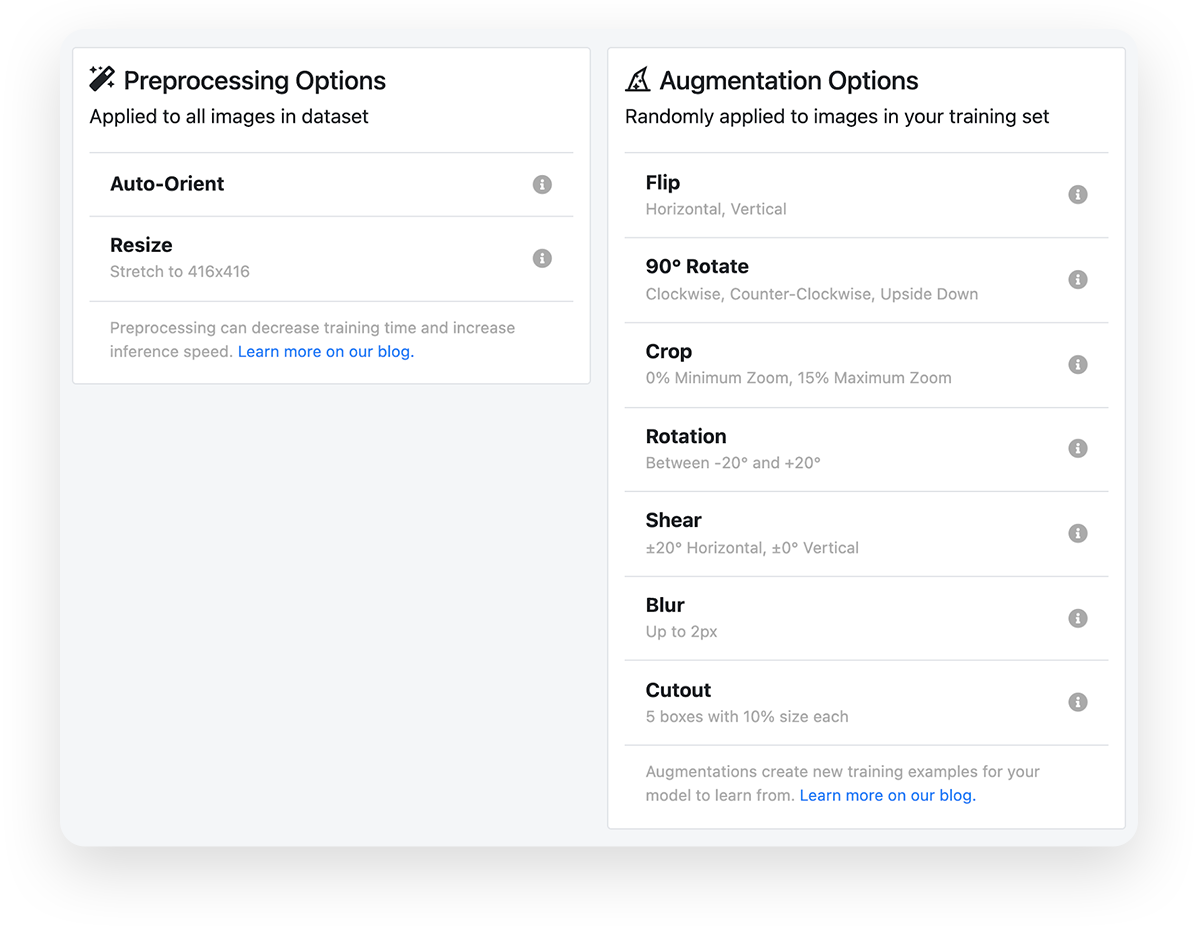
When deciding whether to use a specific augmentation option, I asked myself the question “Is the augmented image a reasonable image for my model to see?” In this case, I added 90°, 180°, and 270° rotations to my image because the slide of cells could reasonably be rotated 90 degrees and still make sense.
It wouldn't make sense for all applications. For instance, I might not include that kind of rotation for a self-driving car, because stop signs should be seen with the pole jutting into the ground. To rotate the image 180 degrees would make the stop sign upside down and the ground where the sky should be – that probably isn’t a very useful thing for my model to learn.
I have my data split up so that 70% of my data is in the training set, 20% is in the validation set, and 10% is in the test set. As you may know, splitting your data into training, validation, and testing sets can really help avoid overfitting.
I’ve decided to create three augmentations. This means that, for each training image, we’ll create three copies of that image, each with random augmentation techniques applied to it. This will give me a total of 874 images that are generated:
- 765 augmented training images (765 = 255 * 3)
- plus 73 validation images
- plus 36 testing images.
Once you’re done with your preprocessing and augmentation, click “Generate” in the top-right corner. Helpful hint: make sure to name your dataset something memorable!
Now you’re ready to build a model
To build a model, it’s as easy as clicking “Use Roboflow Train.”
Generally, you need a Roboflow Train credit to do this. Reach out to us and we’ll get you set up!
You’ll have the option either to train from scratch or to start from a checkpoint.
- Train from Scratch. This is the easier option. Just click and go! Your model will be built from scratch, using only the data you’ve provided to it.
- Start from a Checkpoint. This option is a little more sophisticated and requires a related existing model. If you’ve already built a model (or if there’s a public model) that has been fit on related data, then starting from a checkpoint allows you to use the existing model as your starting point. The model is additionally trained on your images. Two advantages to this are that your model will train more quickly, and you'll frequently see improved performance! This is known as transfer learning. However, this does require a related existing model, and we don't always have that.
In my case, I built my model from scratch, because I didn’t already have a related model.
That’s all it takes to fit a model in Roboflow. When all is said and done, if your data is already annotated and you don’t make many changes to the augmentations, it’s only a handful of clicks to go from your images to a trained computer vision model. We've also turned annotating images into a pretty fast process – especially with model-assisted labeling.
How to use an API to access the model and predictions
You’ll want to make sure your model performs well before getting too far into this.
Our model seems to perform pretty well. Usually, we use mean average precision (mAP) to evaluate object detection models. The closer your mAP is to 100%, the better! It’s also helpful to look at your model’s performance by class to make sure your object detection model isn’t performing significantly worse for one subset of objects.
If your model isn’t performing the way you want, you may want to work on improving that before you proceed. We usually see dramatic improvements in models when people take one (or both) of the following two actions:
- Improve their labeling. Placing bounding boxes around the entire object, but as close to the edges of the object as possible, can improve your model’s performance.
- Correcting for unbalanced classes. Having one or more classes that are severely underrepresented can make it harder for your model to properly identify those underrepresented classes. A basic example is if you show a child 5 pictures of a dog and 100 pictures of a cat, the child may not do a very good job of identifying a dog.
Now that we’ve fit a model, we can use that model to generate predictions on new images. The Roboflow Infer API is one of a few ways to conduct inference and that's what we’ll use.
In order to use the API, we’ll need a couple of pieces of information from Roboflow. Make sure you keep these both private. These are specific to you!
- The model name: this should begin with
rf. - The access token/API key: this should be a 12+ letter code.
This information can be found in multiple places. I like retrieving these from the Example Web App, because I’ll also easily upload an image and test out my model from there. Once you have these pieces of information, you’ll want to store them – you’ll need them momentarily.
How to create and deploy a Streamlit app
Deploying a Streamlit app is easy. Even if you haven’t spent a lot of time focused on deploying apps before. (Here is the code I wrote to build the app.)
Following Streamlit’s API documentation closely, I was able to build an app that:
- Imported an image file from my computer
- Allowed the user to tweak parameters of our computer vision model
- Showed my imported image overlaid with the model’s predicted annotations
- Calculated and displayed summary statistics about the image and predictions
- Generated a histogram of confidence levels for bounding boxes
I chose to structure this in two physical components: a sidebar and the main area.
- Sidebar. In the sidebar, the user gets to select a file to import from their local computer. This is where the user can select an image to pull into the app and edit the confidence and overlap thresholds used when generating predicted bounding boxes for the image.
- Main Area. In the main area, we have everything else I mentioned. The image that includes predictions, some statistics about the image and predictions itself, a histogram that shows the confidence levels for all bounding boxes, and a printout of the JSON that stores the bounding box annotations.
If you want to see the full code, you can find it here. The three tools that were most helpful in putting this together were:
st.write(): If I wanted to print anything on my screen,st.write()enabled me to do that easily. It supports Markdown, so I can use ## to control how large or small I want my headings to be. I also used f-strings when displaying summary statistics to have more control over how these rendered. For example, rounding off the mean confidence level after four decimal places instead of a long string of trailing decimals.st.sidebar(): I’m decidedly not a web developer. Rather than spending my time figuring out how to set aside the left side of the screen for the user and wrangling dimensions, defining a sidebar was literally as easy asst.sidebar(). Want to add something to the sidebar, like a slider or a way to upload your files? Tryst.sidebar.slider()orst.sidebar.file_uploader(). The Streamlit API is set up so that your components stay where you want them.st.image()andst.pyplot(): Streamlit’s API is intuitive. If you want to insert an image into your app, you can do that with thest.image()function. Plot from pyplot?st.pyplot(). If you wanted to put an image into the sidebar, you’d change it fromst.image()tost.sidebar.image().
You get the point. If you want to do something, you can probably just type st.that_thing_you_want_to_do()! If you want that thing to be in your sidebar, change it to st.sidebar.that_thing_you_want_to_do()!
After writing my Python script and pushing to Github, I followed Streamlit’s instructions to deploy my app -- check the app out here!
Want to learn more about some of the amazing apps developers are making with Streamlit? Check out their app gallery and community forum to find some inspiration for your next project.
This blog post was originally shared on the Streamlit blog.
Cite this Post
Use the following entry to cite this post in your research:
Matt Brems. (Feb 23, 2021). How to Use Roboflow and Streamlit to Visualize Object Detection Output. Roboflow Blog: https://blog.roboflow.com/how-to-use-roboflow-and-streamlit-to-visualize-object-detection-output/