
YOLOv5 v6.0 introduces a new P5 and P6 Nano model family that reaches 1666 FPS, small enough to run on mobile and CPU hardware. The release incorporates 465 pull requests from 73 contributors, with model architecture tweaks that reduce backbone size while slightly improving accuracy across the full YOLOv5 family, and adds native Roboflow integration for datasets, labeling, and active learning. The post covers the history of YOLO releases, a benchmark comparison of YOLOv5n versus YOLOv4-tiny, and a training tutorial to get started on a custom dataset.
If you're curious to learn about the most recent introduction of MT-YOLOv6, or as the authors say, "YOLOv6 for brevity", see our YOLOv6 breakdown
Object Detection advances yet again with the newest release of YOLOv5 - v6.0.
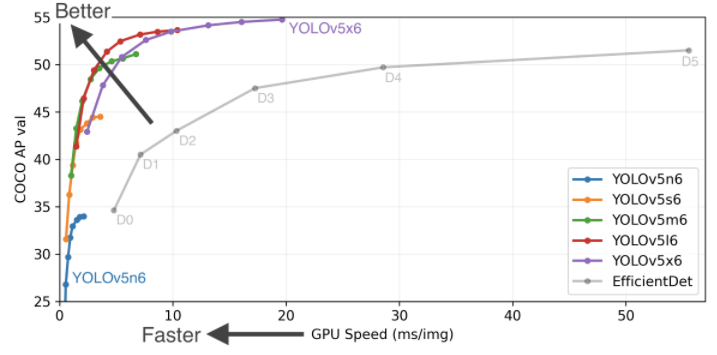
Object detection has been at the core of the recent proliferation of computer vision models in industry - the task of recognizing objects in images. Object detection practitioners care about two primary benchmarks on their model - inference speed and model accuracy.
0:00/1×Example object detection inference on Roboflow's Joseph going for a bike ride
With the v6.0 release, YOLOv5 further solidifies its position as the leading object detection model and open source repository.
YOLOv5 Creator Talks About What Is New
A Brief History of YOLOs
If you need to catch up on the history of YOLO models - there are plenty of blogs detailing the evolution of YOLO from its first evolution to YOLOv3, YOLOv4, YOLOv4-tiny, YOLOv5, Scaled-YOLOv4, YOLO-X, and YOLO-R.
With each new iteration of YOLO models, the model has gotten more nimble and more accurate - reaching a pinnacle with this latest release.
History of YOLO models with Roboflow's CEO, Joseph Nelson
What's New in YOLOv5-V6.0?
The YOLOv5-v6.0 release includes a whole host of new changes across 465 PRs from 73 contributors - with a focus on the new YOLOV5 P5 and P6 nano models, reducing the model size and inference speed footprint of previous models. The new micro models are small enough that they can be run on mobile and CPU.
Model architecture tweaks slightly reduce backbone networks size and slightly improve performance across the family of YOLOv5 models.
Additionally, Roboflow is now integrated for datasets, labeling, and active learning.
For a full review of the release changes, please see the release log.
How Does YOLOv5-V6.0 Compare to Other YOLO Models?
You might be wondering how YOLOv5-V6.0 compares against other YOLO models. We forgo constructing a whole comparison table here, but rather focus on YOLOV5n vs YOLOv4-tiny. That is how do the micro YOLO models compare, since that is what this release is really about.
In the chart below, we compared the training time and inference speed of YOLov5n vs YOLOv4-tiny. We also include COCO mAP accuracy metrics for context.
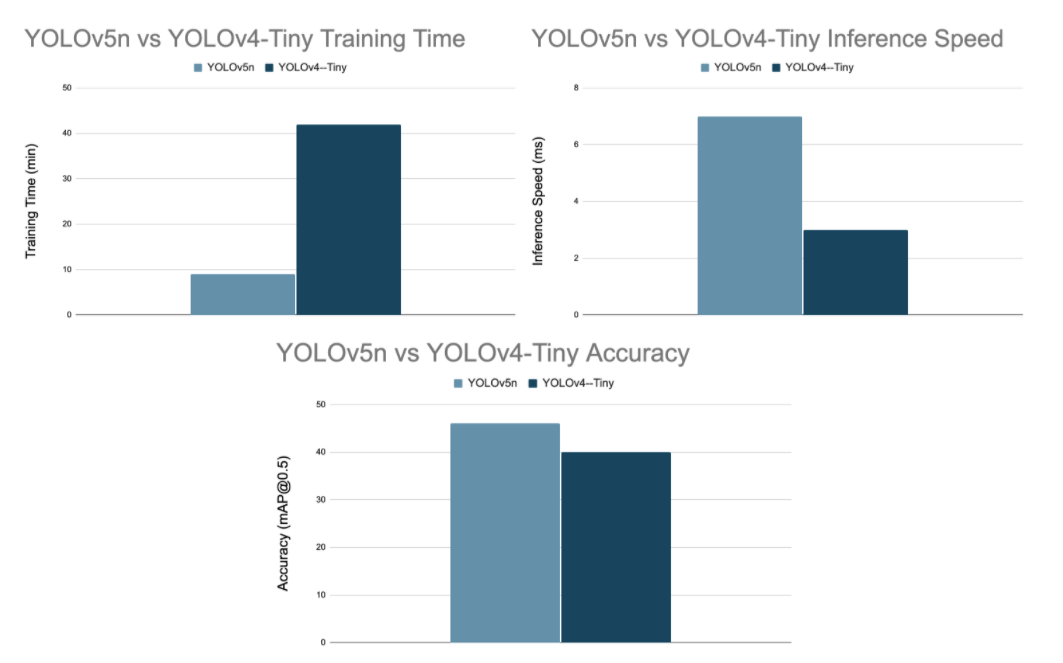
***We provide benchmark Colab notebooks to replicate our results - benchmarking YOLOv4-tiny, benchmarking YOLOV5n. Training is run on the public Roboflow Universe Blood Cell Detection dataset for 100 YOLOv5n epochs, and 6000 YOLOv4-tiny iterations to the point of model fitting. Inference is run on a Colab P100 at 416x416 resolution and a batch size of 1.***
The inference speed in either of these networks can be improved through smaller image size, larger hardware, larger batch size, quantization, pruning, and model conversion. Some of these methods come at the cost of accuracy. Shout out to neural magic and deep sparse - they have been doing some really cool stuff on this front.
With any benchmark we always recommend training the models on your own custom dataset, and deriving your own benchmarks for your conditions.
How to Train YOLOv5-v6.0 on Your Own Dataset
You can train YOLOV5n on your own dataset by labeling your images in Roboflow, generating a dataset version, and following this YOLOv5-v6.0 Training Tutorial and the YOLOv5-v6.0 Training Notebook 🐎.
Training YOLOv5 on Your Own Dataset
What's next for YOLOv5
The object detection world gets more and more exciting by the day. As models get smaller, training time and inference time decreases while accuracy has continued to improve. The horizon of computer vision tasks that are now solvable with AI technology continues to expand.
The biggest improvement from YOLOv5-v6.0 comes in the form of the 465 open source PRs that made it into what it is today as a release. Many of those are not focused on the SOTA metrics that we wrote about above - rather they are real quality of life improvements to make the repository do what you expect it to do - and much more.
Training Yolov5 with Roboflow
We highly recommend you check YOLOv5-v6.0 out for your computer vision task - happy training, and as always happy inferencing.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Oct 13, 2021). YOLOv5 v6.0 is here - new Nano model at 1666 FPS. Roboflow Blog: https://blog.roboflow.com/yolov5-v6-0-is-here/