
This is a head-to-head comparison of YOLO and Roboflow's RF-DETR for object detection and instance segmentation, weighing a CNN single-pass design against a Vision Transformer backbone that uses attention across image patches. It works through raw accuracy, generalization to unfamiliar data, benchmarking methodology, Neural Architecture Search versus hand-tuning, edge hardware fit, and licensing (Apache 2.0 versus AGPL 3.0), landing on RF-DETR for GPU-based commercial products and YOLO26 for low-power CPU and IoT targets.
For almost a decade, YOLO (You Only Look Once) was considered one of the top object detection modeling frameworks. It was among the clear solutions to any debate revolving around model selection. However, back in March 2025, Roboflow released a new object detection model called RF-DETR that made a compelling case against YOLO's dominance.
This article provides an objective, head-to-head comparison of the YOLO series and Roboflow’s RF-DETR models (covering both object detection and instance segmentation) to help you select the ideal architecture for your next computer vision project.
You can try an RF-DETR model below:
An Overview of the Architectures
YOLO Architecture
YOLO processes an input image using a Convolutional Neural Network (CNN) that applies learned filters across the image, detecting local features like edges, corners, and textures.
The efficiency of this architecture comes from its ability to perform these operations in a single forward pass, significantly reducing computational latency. However, the tradeoff is that each detection decision is made somewhat in isolation, based on a local region rather than the full image.
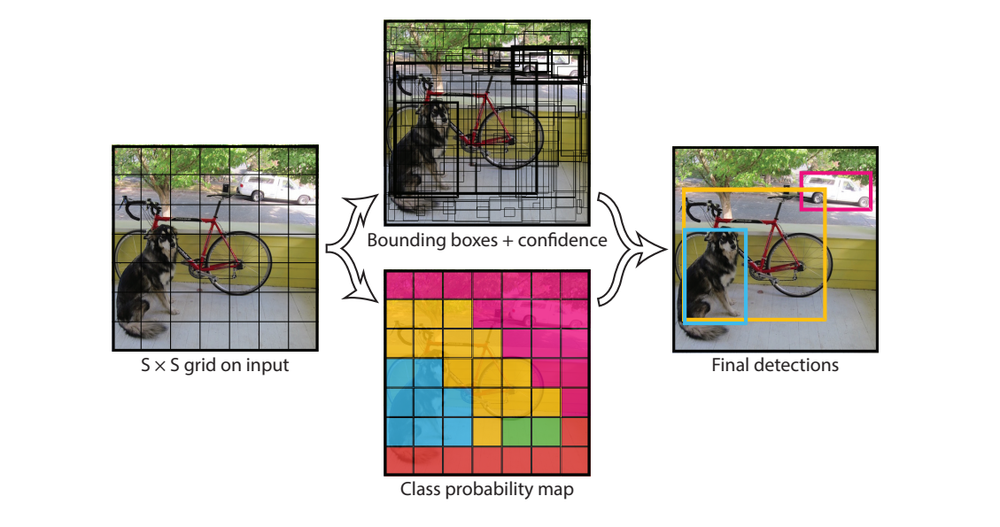
For instance segmentation, YOLO adds a mask prediction branch to its CNN backbone. Since the network focuses on small, local areas, it builds masks using only nearby details. This works perfectly for clearly separated objects. However, it often struggles with overlapping items, complex shapes, and cluttered scenes.
For instance segmentation, YOLO generates masks and crops them to fit strictly inside localized bounding boxes. This works exceptionally well for clearly separated objects. However, because it relies heavily on those boxes to isolate items, YOLO often struggles with overlapping objects, complex shapes, and cluttered scenes where bounding boxes overlap.
Roboflow RF-DETR Architecture
RF-DETR, on the other hand, uses a Vision Transformer backbone. Rather than scanning with filters, it divides the image into a grid of patches and uses attention mechanisms to model relationships between every patch simultaneously.
A detection in the bottom-left corner can be informed by context from the top-right. This global understanding is why RF-DETR produces far fewer false positives on complex and cluttered images.
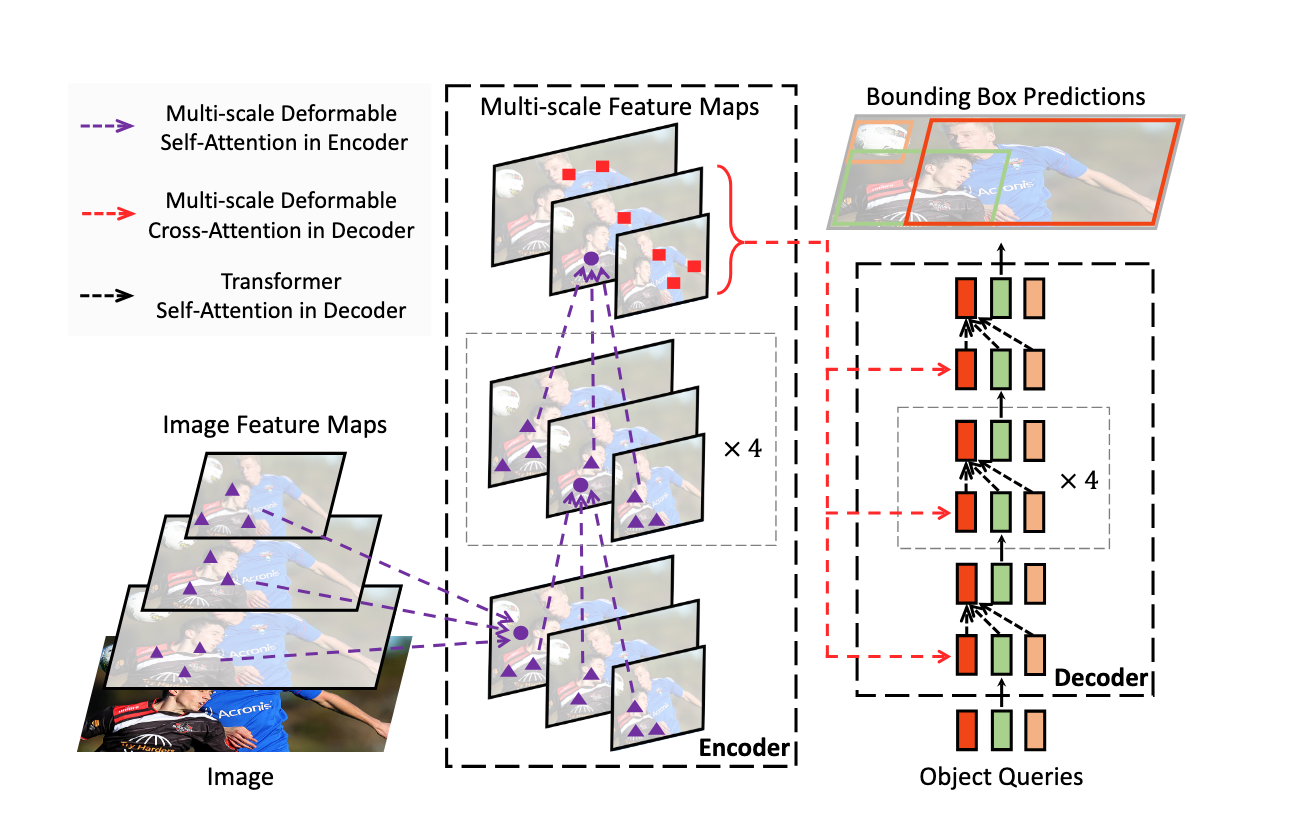
RF-DETR handles segmentation by adding a specialized, MaskDINO-inspired head. The same global attention mechanism that improves its overall detection also creates highly accurate mask boundaries. Because it looks at the entire image at once, it generates precise, pixel-level outlines by using the full context of the scene.
Comparison #1: Raw Accuracy
mAP (mean Average Precision) is the standard scoring metric for object detection. It measures how accurately a model finds objects across varying confidence thresholds on the COCO benchmark, a dataset of 80 everyday object categories.
| Model | MAP on COCO | Latency (MS) |
|---|---|---|
| YOLOv12-N | 40.6 | 1.64 |
| YOLOv12-S | 48.0 | 2.61 |
| YOLOv12-M | 52.5 | 4.86 |
| YOLOv12-X | 55.2 | 11.79 |
| YOLO26-M | 53.1 | 4.7 |
| YOLO26-L | 55.0 | 6.2 |
| RF-DETR Nano | 48.4 | 2.3 |
| RF-DETR Small | 53.0 | 3.5 |
| RF-DETR Medium | 54.7 | 4.4 |
| RF-DETR Large | 56.5 | 6.8 |
| RF-DETR 2XL | 60.1 | 17.2 |
Sources: Ultralytics, Roboflow RF-DETR GitHub. All TensorRT FP16, NVIDIA T4, batch size 1.
We can see from the stats that RF-DETR Nano (48.4 mAP, 2.32ms) beats YOLOv12-S (48.0 mAP, 2.61ms). This is smaller, faster, and more accurate than the YOLO model one size up. RF-DETR Small (53.0 mAP, 3.52ms) beats YOLO26-M (53.1 mAP, 4.7ms) at nearly identical accuracy while being 25% faster and production-stable. Lastly, RF-DETR 2XL at 60.1 mAP is a number no YOLO variant has come close to.
| Model | MAP on COCO | Latency (MS) |
|---|---|---|
| RF-DETR-Seg-N | 40.3 | 3.4 |
| RF-DETR-Seg-S | 43.1 | 4.4 |
| RF-DETR-Seg-M | 45.3 | 5.9 |
| RF-DETR-Seg-L | 47.1 | 8.8 |
| RF-DETR-Seg-XL | 48.8 | 13.5 |
| RF-DETR-Seg-2XL | 49.9 | 21.8 |
| YOLO26-N-Seg | 34.7 | 2.31 |
| YOLO26-S-Seg | 40.2 | 3.47 |
| YOLO26-M-Seg | 44.0 | 6.32 |
| YOLO26-L-Seg | 45.5 | 7.58 |
| YOLO26-X-Seg | 46.8 | 12.92 |
Sources: Roboflow Benchmarks
The instance segmentation metrics show a clear shift when evaluating the actual numbers. At the lightweight tier, YOLO26-N-Seg remains the fastest option at 2.31ms, though upgrading to RF-DETR-Seg-N yields a substantial accuracy increase to 40.3 Mask mAP with a minimal latency tradeoff.
In the mid-range categories, RF-DETR demonstrates excellent architectural efficiency. The Small variant operates at essentially the same speed as YOLO26-S-Seg while outperforming it by nearly 3 points, and the Medium variant beats YOLO26-M-Seg in both precision and processing speed. At the highest capacity, RF-DETR simply scales further. While YOLO26-X-Seg plateaus at 46.8 mAP, RF-DETR-Seg-XL achieves 48.8 mAP at a comparable 13.5ms footprint, with the 2XL version pushing the accuracy ceiling to 49.9 mAP.
Comparison #2: Model Generalization
While peak accuracy on standard benchmarks is impressive, a model’s true utility depends on how well it adapts to data it has never seen before. Standard evaluation protocols often overlook the limits of benchmark overfitting. The COCO dataset represents a controlled environment rather than actual deployment conditions.
Every iterative YOLO variant (including YOLOv12) undergoes exhaustive optimization specifically tailored to this dataset. Hyperparameter choices, data augmentation pipelines, and architectural modifications are all engineered to maximize that single metric. As a result, when these models are deployed outside the standard 80 COCO categories or applied to non-standard images, performance drops off quickly.

In contrast, RF-DETR was evaluated against RF100-VL, a benchmark composed of 100 distinct, real-world datasets spanning diverse domains like medical imaging, aerial photography, industrial defect inspection, and sports tracking.
On these out-of-distribution datasets, YOLO architectures consistently underperform. Scaling up the model size does not mitigate this issue, as larger YOLO variants yield no real improvement over smaller ones on unfamiliar data. This proves that this is an architectural limitation rather than an issue of model capacity.

The reason RF-DETR generalizes so well is because of its backbone architecture. While the YOLO series relies on convolutional networks (CNNs) engineered specifically for detection tasks, RF-DETR leverages DINOv2, a Vision Transformer (ViT) pretrained via self-supervised learning on a massive dataset of internet-scale images without manual labels.
This means the model approaches new datasets with a deep, pre-existing understanding of diverse visual patterns. While recent iterations like YOLOv12 introduce attention mechanisms to break out of traditional CNN limits, their foundational backbones are still anchored to detection-specific training data and COCO-centric tuning.
Comparison #3: Benchmarking Methodologies
To evaluate object detection models objectively, we have to look closely at how their performance numbers are actually recorded. The RF-DETR paper highlights two widespread benchmarking issues that frequently make standard comparisons misleading.
1. Non-Maximum Suppression (NMS) Latency Omission
Standard convolutional detectors inherently generate duplicate bounding boxes around the same object. They rely on a post-processing step called Non-Maximum Suppression (NMS) to filter out these duplicates before final deployment. Historically, many published YOLO benchmarks have left NMS overhead completely out of their latency calculations, which understates the true latency you will see in production. Moreover, even YOLO's segmentation pipeline has additional required steps (mask prototype conversion and mask cropping) that are similarly excluded from published numbers.
While older architectures like YOLOv8 and YOLOv9 require heavy NMS post-processing, later iterations like YOLOv10 and the newer YOLO26 framework have pushed toward native NMS-free pipelines. RF-DETR uses a transformer decoder that naturally outputs clean, unique predictions from the start, bypassing the need for a post-processing cleanup phase entirely for both object detection and segmentation.

2. Thermal Throttling and Precision Discrepancies
GPUs slow themselves down when they get too hot to keep from melting. Standard YOLO scripts test the GPU with images back-to-back without stopping. The heat builds up, the clock speed drops, and your average speed numbers get skewed by the hardware choking. RF-DETR adds a mandatory 200ms pause between images to keep the GPU cool so the hardware stays at a baseline speed.
Along with thermal management, benchmark charts often lean on an industry shortcut involving file precision, specifically FP32 (Full Precision) and FP16 (Half Precision).
- FP32 uses massive decimal detail for peak accuracy, which demands more memory and slows down the GPU.
- FP16 rounds those numbers off to cut memory usage in half, allowing the GPU to crunch math twice as fast.
Standard benchmarks frequently mix these up to get an artificial, best-of-both-worlds score. They record accuracy using the highly detailed FP32 file, then measure speed using the compressed FP16 file, and print both numbers side by side.
This creates a major discrepancy for production, where you can only deploy one file format. Deploying the fast FP16 version means those tiny rounding errors can compound across hundreds of layers, occasionally breaking the model's internal logic and tanking real-world accuracy to near zero. The RF-DETR paper maintains data transparency by running both speed and accuracy tests on the same FP16 file, revealing the actual performance you get in production.
The Point: When picking a model (object detection or instance segmentation) for production, ensure the speed test includes NMS, the GPU maintains a stable thermal state during the run, and the accuracy score comes from the exact file precision you plan to deploy.
Comparison #4: Neural Architecture Search vs. hand-tuning
Traditional YOLO variants (such as Nano, Small, Medium, and Large) rely on uniform scaling. Engineers design a single large base model and apply global depth and width factors to shrink or expand it. This cuts the number of layers and channel widths down by a fixed percentage across the entire network.
The downside to this approach is that uniform downscaling acts as a blunt tool, copying the exact structural inefficiencies of the large model directly into the smaller variants.
RF-DETR replaces manual scaling with Neural Architecture Search (NAS), which uses optimization algorithms to discover the most accurate layout for a specific hardware speed limit. It achieves this by training a single master model called a "supernet."
During training, the framework randomly samples a different internal configuration for every batch of images, constantly varying the active layer depths, patch dimensions, and channel configurations. This forces the shared weights inside the supernet to learn how to process features accurately across thousands of different active pathways within a single training run.
At deployment, you specify your hardware latency constraint, such as requiring an execution speed under 2.5ms on a T4 GPU. The search algorithm maps out the trained supernet to extract the exact sub-network permutation that delivers peak accuracy within that timeframe, providing the final weights with zero retraining required.
This explains why smaller models like RF-DETR Nano perform efficiently both for object detection and segmentation. It's because their layouts are custom-carved for tight hardware limits, avoiding the waste of a uniformly shrunken architecture.
Comparison #5: Edge Hardware Target Suitability
RF-DETR Nano runs in 2.32ms on an NVIDIA T4 GPU and has demonstrated 46.7 FPS in multi-camera real-world deployments. For edge hardware equipped with dedicated tensor acceleration, such as the NVIDIA Jetson AGX Orin or Orin NX, RF-DETR provides a highly competitive combination of speed and accuracy for both detection and segmentation. RF-DETR Seg Nano runs at 3.4ms on the same hardware class, making real-time pixel-level segmentation viable on GPU edge devices without dropping to a weaker model.
However, YOLO26 is better suited for deeply embedded edge architectures that lack hardware matrix acceleration, such as Raspberry Pi units, microcontrollers, and native CPU runtimes. With a compact parameter footprint (2.4M to 55.7M) and the removal of DFL layers, it offers an export-friendly profile for low-power IoT applications. YOLO26n-Seg at 33.9 mask mAP and 2.1ms remains the lightest production-grade segmentation option available for CPU edge targets.
RF-DETR's DINOv2 backbone carries significant weight and cannot be compressed to that same degree. Ultimately, RF-DETR is optimized for GPU edge deployment, while YOLO26 remains the practical choice for CPU edge infrastructure.

Comparison #6: Open-Source Licensing Frameworks
Licensing often determines architectural selection for commercial applications before performance metrics are considered. YOLOv12 and YOLO26 are distributed under the GNU Affero General Public License (AGPL 3.0). This copyleft framework requires organizations utilizing the models within commercial platforms to open-source their proprietary application code unless they secure a commercial enterprise license from Ultralytics.
The open-source core of the RF-DETR family (Nano through Large models) is governed by the permissive Apache 2.0 license. This allows engineering teams to integrate the models into proprietary software architectures without mandatory code disclosure or commercial licensing fees.
Conclusion: What YOU Should Choose
Choosing between these frameworks comes down to your deployment hardware and your commercial strategy. Roboflow’s RF-DETR (Apache 2.0) delivers the highest raw accuracy, the lowest false-positive rate, and excellent real-world generalization thanks to its transformer backbone. It runs efficiently in real-time on GPU-accelerated edge devices like the Jetson AGX Orin.
The community-developed YOLOv12 (AGPL 3.0) brings an attention-centric design and impressive COCO benchmarks alongside access to the industry's largest user ecosystem. However, it exhibits notable training instability and high memory usage, meaning it remains better suited for research and testing instead of immediate production deployment.
For low-power IoT hardware and microcontrollers, YOLO26 (AGPL 3.0) offers exceptional CPU and edge efficiency. Its NMS-free pipeline allows for clean ONNX and TFLite exports in a highly stable package, even though it skips real-time GPU optimizations and remains highly overfit to COCO distribution.
Ultimately, you should lean toward RF-DETR if you are building a commercial product on GPU hardware, while saving YOLO26 for localized CPU infrastructures where AGPL licensing boundaries are not a constraint.
For some extra resources aside from this article, feel free to check out the following links:
- The Official RF-DETR Paper
- Roboflow's RF-DETR GitHub repo — architecture details & model family info
- Comparison between RF-DETR and YOLOV12
- YOLO26 Overview
- The Moonlight — YOLO26 benchmarks & architectural breakdown
RF-DETR vs YOLO: Head-to-Head Comparison
A summary of how RF-DETR and the YOLO series compare across the dimensions that decide a production deployment.
| Dimension | RF-DETR | YOLO |
|---|---|---|
| Backbone | Vision Transformer (DINOv2), pretrained self-supervised on internet-scale images | Convolutional neural network, detection-specific (recent variants add attention) |
| How it sees the image | Global attention across all patches at once, so a detection in one corner is informed by the whole scene | Local filters in a single forward pass, so each detection is made from a local region |
| False positives on cluttered scenes | Fewer, due to global context | More, due to local-only reasoning |
| Instance segmentation | MaskDINO-inspired head; global attention produces precise pixel-level boundaries, handles overlap and complex shapes | Mask branch cropped to local bounding boxes; struggles with overlapping objects and cluttered scenes |
| Peak COCO accuracy | Highest in class; RF-DETR 2XL reaches 60.1 mAP, a level no YOLO variant approaches | Strong on COCO (YOLOv12-X 55.2, YOLO26-L 55.0) but plateaus below RF-DETR |
| Real-world generalization (RF100-VL) | Strong out-of-distribution performance; transformer backbone transfers across domains | Underperforms on unfamiliar data; scaling up the model does not close the gap |
| Post-processing | Transformer decoder outputs clean, unique predictions, no NMS needed | Older variants need NMS; YOLOv10 and YOLO26 move toward NMS-free pipelines |
| Benchmark methodology | Latency includes all steps; speed and accuracy reported on the same FP16 file, with thermal control | Published numbers often omit NMS latency and mix FP32 accuracy with FP16 speed |
| Model scaling | Neural Architecture Search carves each size for a specific latency target | Uniform depth/width scaling copies the large model's inefficiencies into smaller ones |
| Edge hardware fit | Best on GPU-accelerated edge (NVIDIA Jetson AGX Orin, Orin NX) for real-time detection and segmentation | YOLO26 is better for CPU-only and deeply embedded targets (Raspberry Pi, microcontrollers, IoT) |
| Licensing | Apache 2.0 (Nano through Large), commercial-safe, no code disclosure | AGPL 3.0; commercial use requires open-sourcing your code or a paid Ultralytics license |
| Best for | Commercial products on GPU hardware that need accuracy, low false positives, and real-world reliability | Low-power CPU and IoT infrastructure where AGPL is not a constraint |
Cite this Post
Use the following entry to cite this post in your research:
Aarnav Shah. (Jan 15, 2026). RF-DETR vs. YOLO: Choosing the Right Architecture for your Project. Roboflow Blog: https://blog.roboflow.com/rf-detr-vs-yolo/