A tutorial to train and use EfficientDet on a custom object detection task with varying number of classes
YOLOv5 is Out!
If you're here for EfficientDet in particular, stay for EfficientDet. Otherwise consider running the YOLOv5 PyTorch tutorial in Colab. You'll have a very performant, trained YOLOv5 model on your custom data in a matter of minutes.
The Google Brain team recently published EfficientDet, rethinking model scaling for convolutional neural networks. In this post, we provide a tutorial of how to train and use EfficientDet on your own data, with varying number of classes.
For the original posting: please see this blog post on how to train EfficientDet.
If you want to get right into the code implementation, jump to our EfficientDet Training Colab Notebook. Colab is free to use and provides a python programming environment equipped with GPU compute resources.
In the tasks we’ve seen (and as of April 2020), EfficientDet achieves the best performance in the fewest training epochs among object detection model architectures, making it a highly scalable architecture especially when operating with limited compute. This is consistent with the results the EfficientDet authors published.
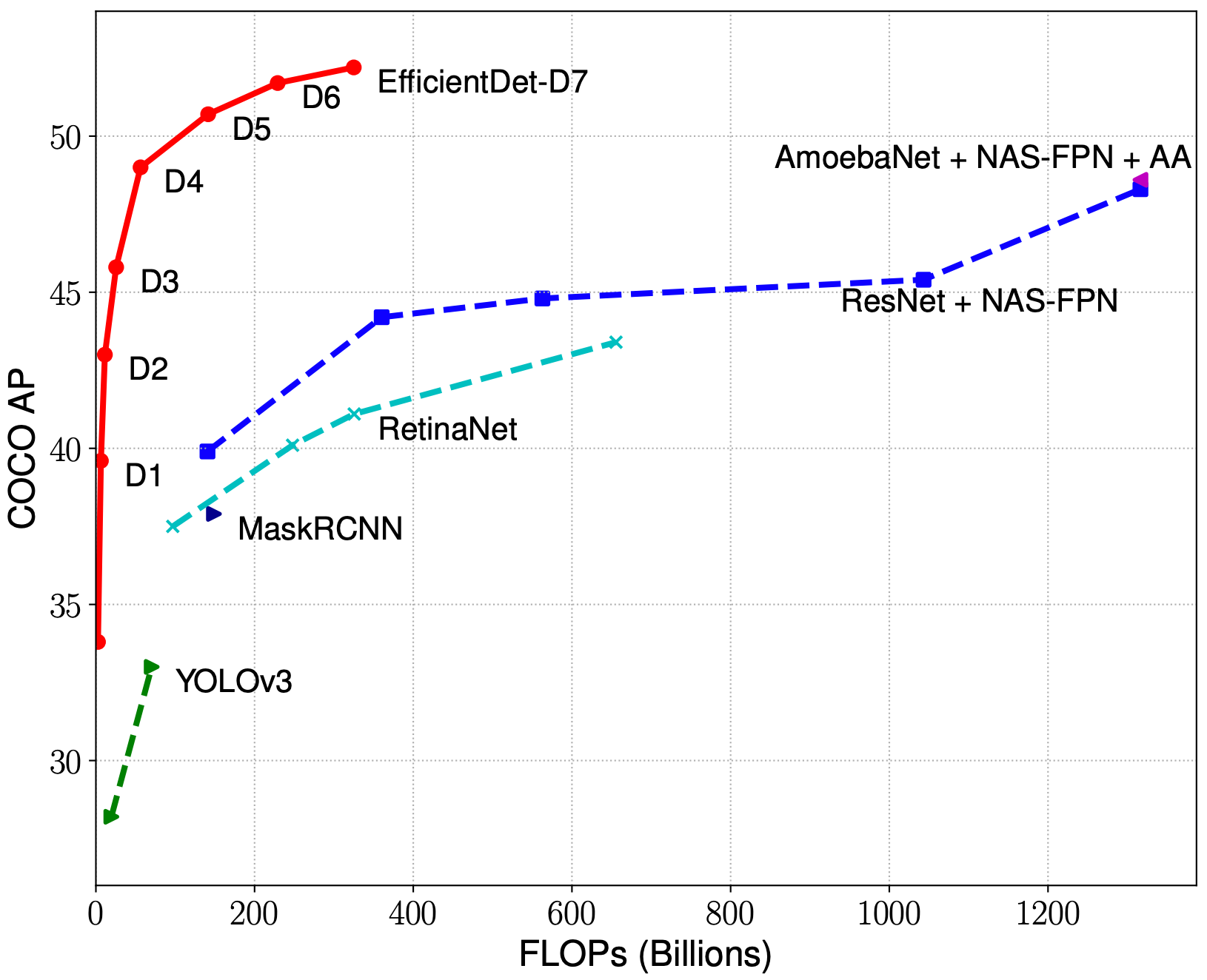
EfficientDet is the object detection version of EfficientNet, building on the success EfficientNet has seen in image classification tasks. EfficientNets come from a family of models that achieve a high performance on benchmark tasks while controlling for a number of efficiency parameters, such as model size and FLOPS. The network is delivered in a series of model sizes d0-d7, and the base model is thought to perform better than YOLOv3 with a smaller model size (more to come on this soon).
In this post, we explore a PyTorch implementation of EfficientDet on a custom dataset, demonstrating how you can do the same for your own dataset.
Our Example Dataset
Our dataset contains 292 images of chess pieces on a chess board. Each chess piece is labeled with a bounding box describing the pieces class {white-knight, white-pawn, black-queen,...}. Our custom dataset has 12 total classes, which does not match the number of classes in COCO where training occurred. No worries! The model architecture will seamlessly adapt to the number of classes that your custom dataset contains.
***Using Your Own Data***
To export your own data for this tutorial, sign up for Roboflow and make a public workspace, or make a new public workspace in your existing account. If your data is private, you can upgrade to a paid plan for export to use external training routines like this one or experiment with using Roboflow's internal training solution.

Preparing the Data
Going straight from data collection to model training leads to suboptimal results. There may be problems with the data. Even if there aren’t, applying image augmentation expands your dataset and reduces overfitting.
Preparing images for object detection models includes, but is not limited to:
- Verifying your annotations are correct (e.g. none of the annotations are out of frame in the images)
- Ensuring the EXIF orientation of your images is correct (i.e. your images are stored on disk differently than how you view them in applications)
- Resizing images and updating image annotations to match the newly sized images
- Various color corrections that may improve model performance like grayscale and contrast adjustments
- Formatting annotations to match the requirements of your model’s inputs (e.g. generating TFRecords for TensorFlow or a flat text file for some implementations of YOLO).
Similar to tabular data, cleaning and augmenting image data can improve your ultimate model’s performance more than architectural changes in your model.
Roboflow Organize is purpose-built dataset management tool to seamlessly solve these challenges. In fact, Roboflow Organize cuts the code you need to write roughly in half while giving you access to more preprocessing and augmentation options.
For our specific chess problem, our already preprocessed chess data is available on Roboflow as a public dataset.
Either fork this dataset to your free Roboflow account, or create a download in COCO JSON format.

After selecting our annotation format, Roboflow provides a curl script ("Show Download Code") where we can access our dataset.
We can then use this curl script to import our data into the Colab notebook that we are working in. Colab is a Jupyter Notebook python programming environment provided by Google and provisioned with free GPU usage. Colab is free to start, but may time out on you if your notebook sits idle for 15 minutes or so.
Jump to our EfficientDet Colab Notebook.
Once our data has downloaded we will inspect the folder structure. The COCO json data comes down in train, validate, test splits that we have determined in our data set up in Roboflow. Inspecting the train folder, we see that our data has come down as a set of images and an annotation file. We then make file structure in a fashion that our model will be expecting, but no additional data cleaning is required!
Training
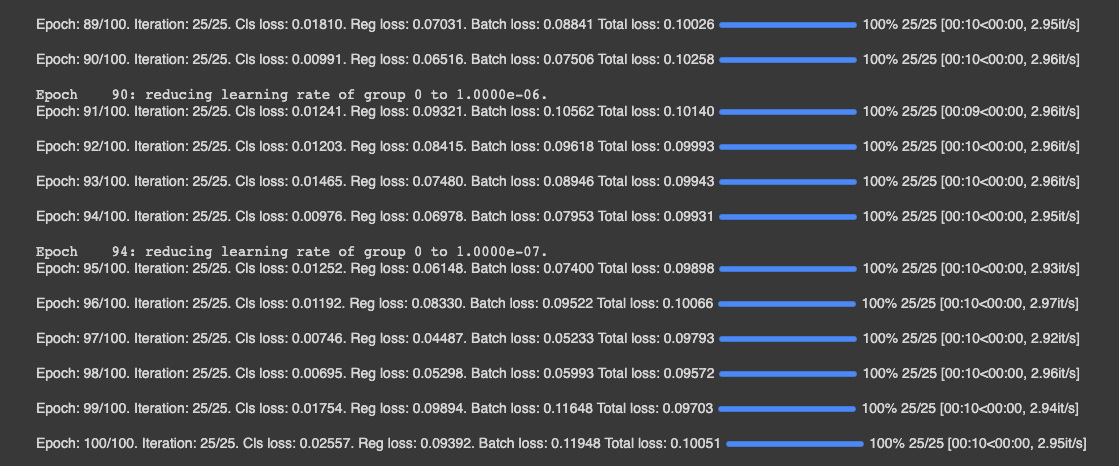
For training, we import a PyTorch implementation of EfficientDet courtesy of signatrix. Our implementation uses the base version of EfficientDet-d0. We train from the EfficientNet base backbone, without using a pre-trained checkpoint for the detector portion of the network. We train for 20 epochs across our training set. The implementation naturally adapts to the number of training classes, which is a nice comparison to the original network release in TensorFlow.
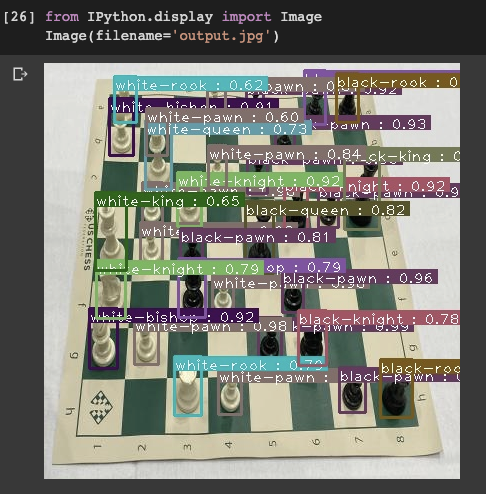
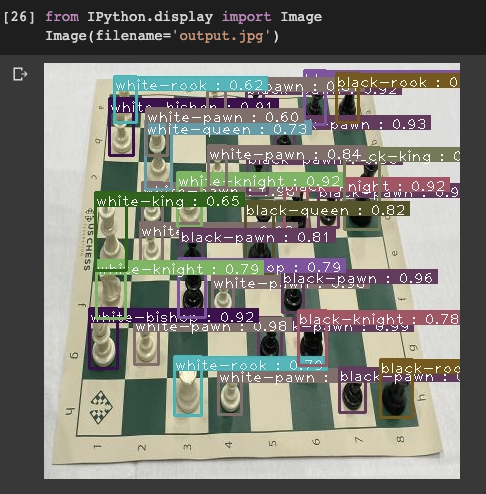
Inference
During training, our model saves .onnx files that can be easily called during inference time. We call these files to set up an infer detector and simply pass an image, our list of classes, and a prediction threshold through to our inferencer. The prediction threshold can be adjusted dynamically to control for precision and recall according to your use case.
We witness a fast inference time and according to a few test images it looks like the network quickly adapted to our custom object detection problem!
Saving Our Weights
We export our trained model’s .onxx files to Google Drive for future use. You can simply pull those files back down and rebuild the inferencer for your application!
At the bottom of the notebook, we provide an example of how you can pull trained model weights back down and use them for inference in your application. In a future post, we will provide more detail on how to use EfficientDet in your application.
And there you have it — a quick and easy way to begin prototyping EffienctDet on your own data, for your own custom use case, with a varying number of classes.
Next Steps
We compared more granular evaluations of the EfficientDet model compared to YoloV3 including training time, model size, memory footprint, and inference time in future blog posts. We also took a deep dive into the EfficientDet model architecture to better understand how the magic happens.