
Baidu publishes PP-YOLO and pushes the state of the art in object detection research by building on top of YOLOv3, the PaddlePaddle deep learning framework, and cutting edge computer vision research.
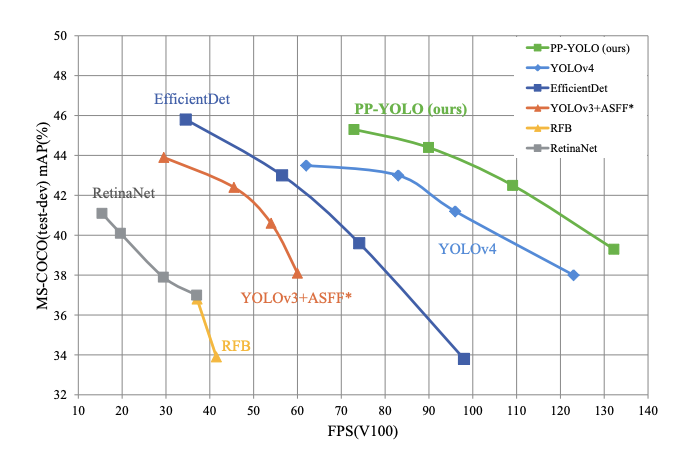
PP-YOLO evaluation metrics show improved performance over YOLOv4, the incumbent state of the art object detection model. Yet, the Baidu authors write:
This paper is not intended to introduce a novel object detecotor.
It is more like a recipe, which tell you how to build a better detector step by step.Mysterious introduction in the PP-YOLO paper
Let's unpack that.
YOLO Development History
YOLO was originally authored by Joseph Redmon to detect objects. Object detection is a computer vision technique that localizes and tags objects by drawing a bounding box around them and identifying the class label that a given box belongs too. Unlike massive NLP transformers, YOLO is designed to be tiny, enabling realtime inference speeds for deployment on device.
YOLO-9000 was the second "YOLOv2" object detector published by Joseph Redmon, improving the detector and emphasizing the detectors ability to generalize to any object in the world.

YOLOv3 made further improvements to the detection network and began to mainstream the object detection process. We began to publish tutorials on how to train YOLOv3 in PyTorch, how to train YOLOv3 in Keras, and compared YOLOv3 performance to EfficientDet (another state of the art detector).
Then Joseph Redmon stepped out of the object detection game due to ethical concerns.
Naturally, the open source community picked up the baton and continues to move YOLO technology forward.
YOLOv4 was published recently this spring by Alexey AB in his for of the YOLO Darknet repository. YOLOv4 was primarily an ensemble of other known computer vision technologies, combined and validated through the research process. See here for a deep dive on YOLOv4. The YOLOv4 paper reads similarly to the PP-YOLO paper, as we will see below. We put together some great training tutorials on how to train YOLOv4 in Darknet.
Then, just a few months ago YOLOv5 was released. YOLOv5 took the Darknet (C based) training environment and converted the network to PyTorch. Improved training techniques pushed performance of the model even further and created a great, easy to use, out of the box object detection model. Ever since, we have been encouraging developers using Roboflow to direct their attention to YOLOv5 for the formation of their custom object detectors via this YOLOv5 training tutorial.
Enter PP-YOLO.
What Does PP Stand For?
PP is short for PaddlePaddle, a deep learning framework written by Baidu.

If PaddlePaddle is new to you, then we are in the same boat. Primarily written in Python, PaddlePaddle seems akin to PyTorch and TensorFlow. A deep dive into the PaddlePaddle framework is intriguing, but beyond the scope of this article.
PP-YOLO Contributions
The PP-YOLO paper reads much like the YOLOv4 paper in that it is a compilation of techniques that are known to work in computer vision. The novel contribution is to prove that the ensemble of these technologies improves performance, and to provide an ablation study of how much each step helps the model along the way.
Before we dive into the contributions of PP-YOLO, it will be useful to review the YOLO detector architecture.
Anatomy of the YOLO Detector
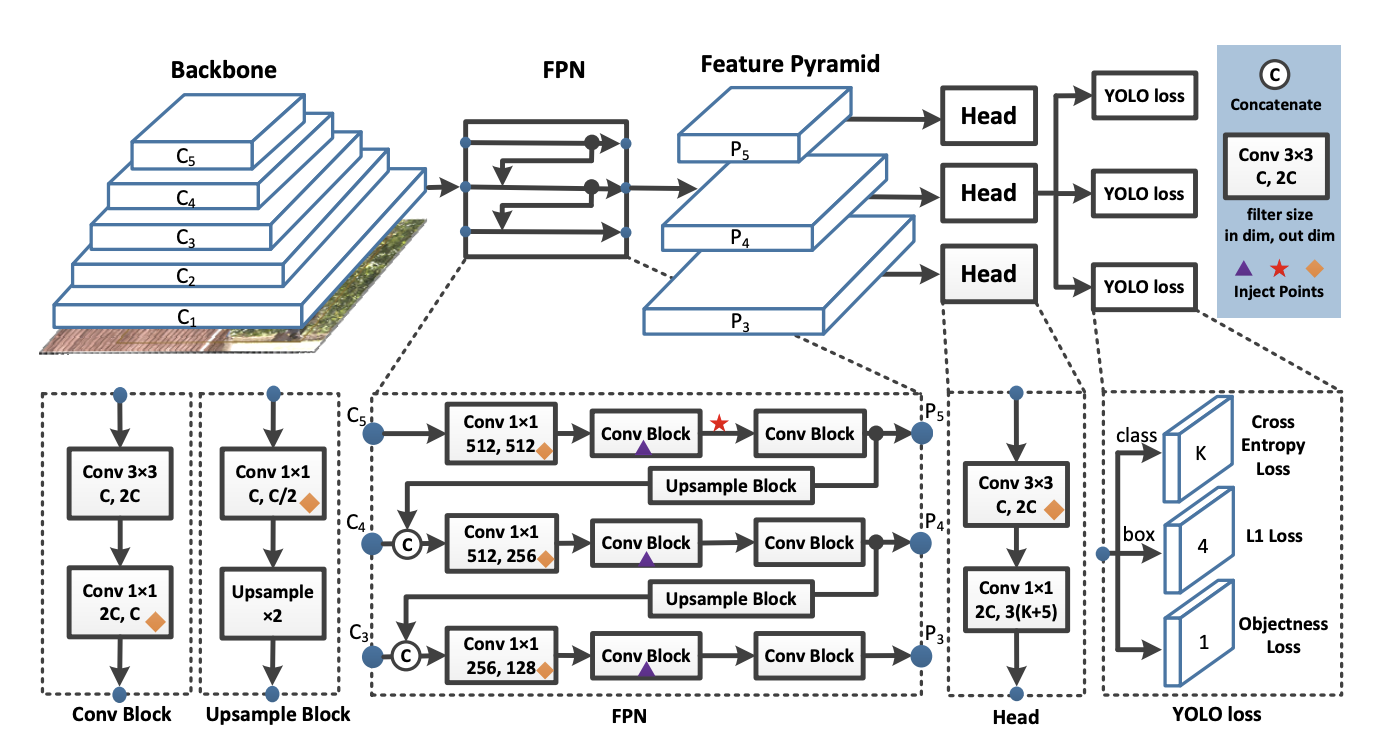
The YOLO detector is broken into three main pieces.
YOLO Backbone - The YOLO backbone is a convolutional neural network that pools image pixels to form features at different granularities. The Backbone is typically pretrained on a classification dataset, typically ImageNet.
YOLO Neck - The YOLO neck (FPN is chosen above) combines and mixes the ConvNet layer representations before passing on to the prediction head.
YOLO Head - This is the part of the network that makes the bounding box and class prediction. It is guided by the three YOLO loss functions for class, box, and objectness.
Now let's dive into the PP YOLO Contributions.
Replace Backbone
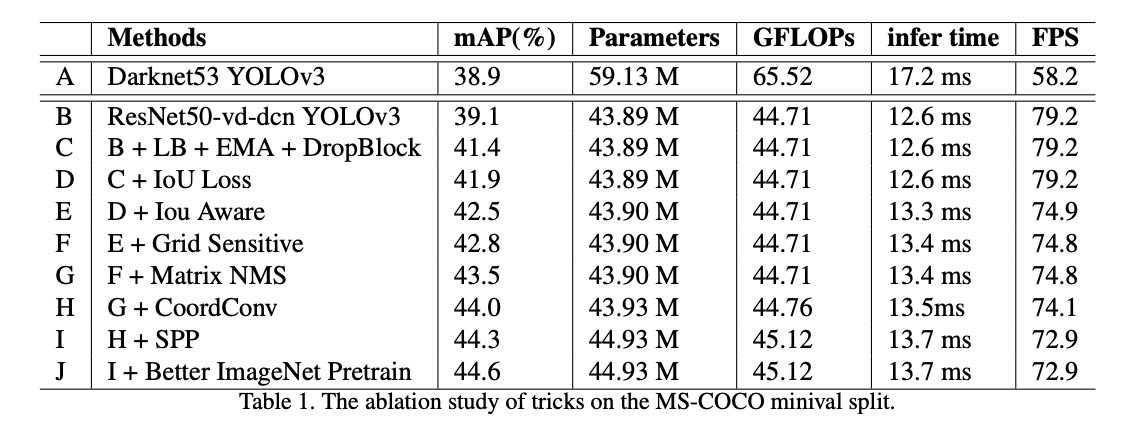
The first PP YOLO technique is to replace the YOLOv3 Darknet53 backbone with the Resnet50-vd-dcn ConvNet backbone. Resnet is a more popular backbone, more frameworks are optimized for its execution, and it has fewer parameters than Darknet53. Seeing a mAP (mean average precision) improvement by swapping this backbone is a huge win for PP YOLO.
EMA of Model Parameters
PP YOLO tracks the Exponential Moving Average of network parameters to maintain a shadow of the models weights for prediction time. This has been shown to improve inference accuracy.
Larger Batch Size
PP-YOLO bumps the batch size up from 64 to 192. Of course, this is hard to implement if you have GPU memory constraints.
DropBlock Regularization
PP YOLO implements DropBlock regularization in the FPN neck (in the past, this has usually occurred in the backbone). DropBlock randomly removes a block of the training features at a given step in the network to teach the model to not rely on key features for detection.
IoU Loss
The YOLO loss function does not translate well to the mAP metric, which uses the Intersection over Union heavily in its calculation. Therefore, it is useful to edit the training loss function with this end prediction in mind. This edit was also present in YOLOv4.
IoU Aware
The PP-YOLO network adds a prediction branch to predict the model's estimated IOU with a given object. Including this IoU awareness when making the decision to predict an object or not improves performance.
Grid Sensitivity
The old YOLO models do not do a good job of making predictions right around the boundaries of anchor box regions. It is useful to define box coordinates slightly differently to avoid this problem. This technique is also present in YOLOv4.
Matrix NMS
Non-Maximum Suppression is a technique to remove over proposals of candidate objects for classification. Matrix NMS is a technique to sort through these candidate predictions in parallel, speeding up the calculation.
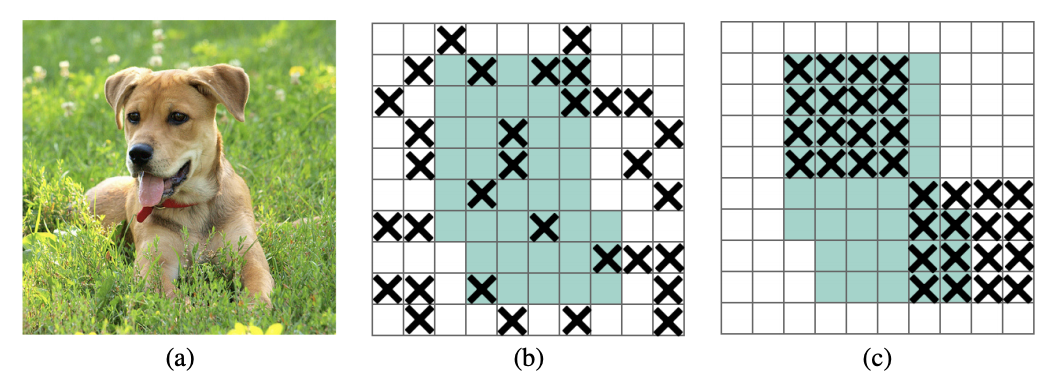
CoordConv
CoordConv was motivated by the problems ConvNets were having with simply mapping (x,y) coordinates to a one-hot pixel space. The CoordConv solution gives the convolution network access to its own input coordinates. CoordConv interventions are marked with yellow diamonds above. More details are available in the CordConv paper.
SPP
Spatial Pyramid Pooling is an extra block after the backbone layer to mix and pool spatial features. Also implemented in YOLOv4 and YOLOv5.
Better Pretrained Backbone
The PP YOLO authors distilled down a larger ResNet model to serve as the backbone. A better pretrained model shows to improve downstream transfer learning as well.
Is PP-YOLO State of the Art?
PP-YOLO outperforms the results YOLOv4 published on April 23, 2020.
In fairness, the authors note this may be the wrong question to be asking. The authors' intent appears to not simply "introduce a new novel detector," rather to show the process of carefully tuning an object detector to maximize performance. Quoting the paper's introduction here:
The focus of this paper is how to stack some effective tricks that hardly affect efficiency to get better performance... This paper is not intended to introduce a novel object detector. It is more like a recipe, which tell you how to build a better detector step by step. We have found some tricks that are effective for the YOLOv3 detector, which can save developers’ time of trial and error. The final PP-YOLO model improves the mAP on COCO from 43.5% to 45.2% at a speed faster than YOLOv4
(emphasis ours)
The PP-YOLO contributions reference above took the YOLOv3 model from 38.9 to 44.6 mAP on the COCO object detection task and increased inference FPS from 58 to 73. These metrics are shown in the paper to beat the currently published results for YOLOv4 and EfficientDet.
In benchmarking PP-YOLO against YOLOv5, it appears YOLOv5 still has the fastest inference time-to-accuracy performance (AP vs FPS) tradeoff on a V100. However, a YOLOv5 paper still remains to be released. Furthermore, it has been shown that training the YOLOv4 architecture on the YOLOv5 Ultralytics repository outperforms YOLOv5 and, transitively, YOLOv4 trained using YOLOv5 contributions would outperform the PP-YOLO results posted here. These results are still to be formally published but can be traced to this GitHub discussion.
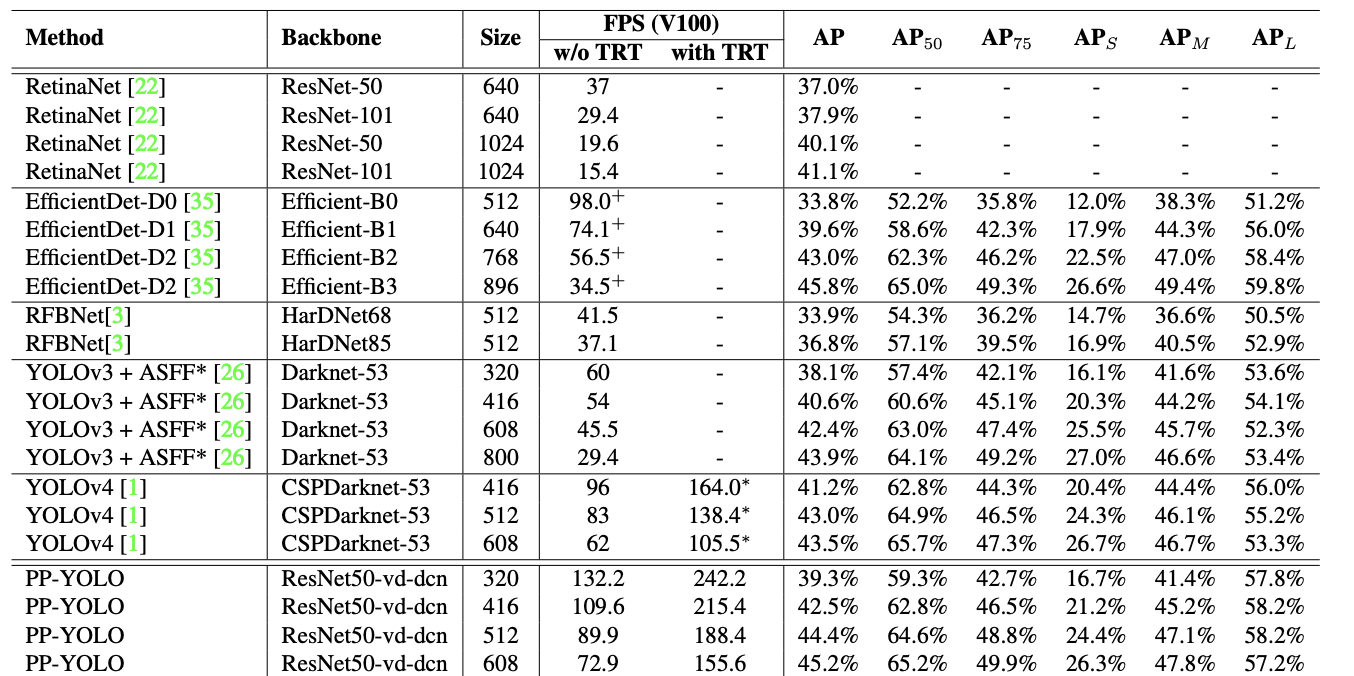
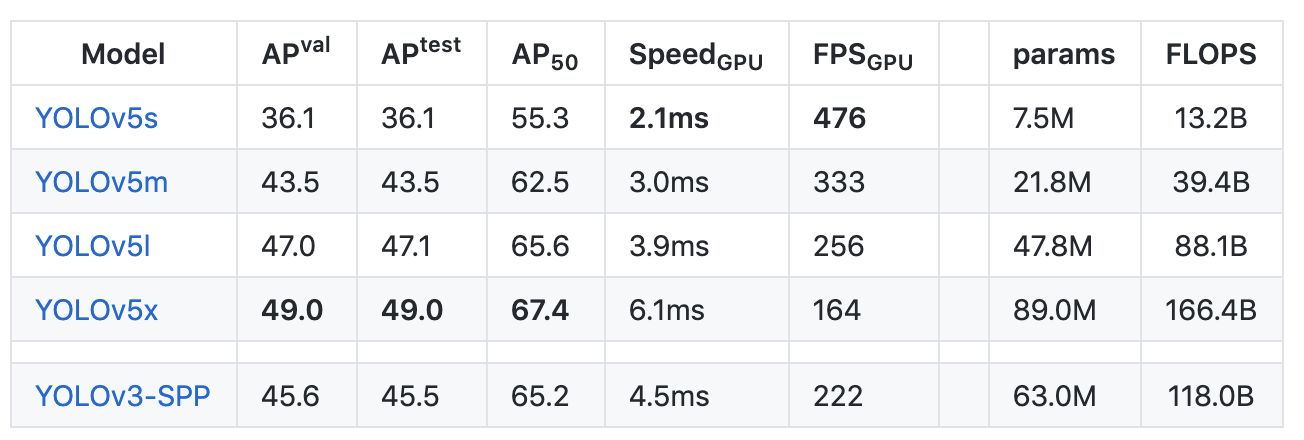
It is worth noting that many of the techniques (such as architecture search and data augmentation) that were used in YOLOv4 were not used in PP YOLO. This means that there is still room for the state of the art in object detection to grow as more of these techniques are combined and integrated together.
Needless to say, is an exciting time to be implementing computer vision technologies.
Should I Switch from YOLOv4 or YOLOv5 to PP-YOLO?
The PP-YOLO model shows the promise of state of the art object detection, but the improvements are incremental over other object detectors and it is written in a new framework. At this stage, the best thing to do is to develop your own empirical result by training PP-YOLO on your own dataset. (To be notified when you can easily use PP-YOLO on your dataset, subscribe to our newsletter.)
In the meantime, I recommend checking out the following YOLO tutorials to get your object detector off the ground:
As always - happy training!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz, Joseph Nelson. (Aug 3, 2020). PP-YOLO Surpasses YOLOv4 - State of the Art Object Detection Techniques. Roboflow Blog: https://blog.roboflow.com/pp-yolo-beats-yolov4-object-detection/