
Detecting small objects is one of the most challenging and important problems in computer vision. In this post, we will discuss some of the strategies we have developed at Roboflow by iterating on hundreds of small object detection models.
You can test a system that lets you apply one of the strategies we will discuss, image slicing with SAHI, with the following widget:
To learn more about building a workflow that runs an object detection model and detects small objects, refer to our Detect Small Objects with Roboflow Workflows guide.
What is Small Object Detection?
Small object detection is a computer vision problem where you aim to accurately identify objects that are small in a video feed or image. The object itself does not necessarily need to be small. For instance, small object detection is crucial in aerial computer vision, where you need to be able to accurately identify objects even though each individual object will be small relative to the photo size.
There are two stages of a computer vision pipeline at which you can make optimizations to detect small objects:
- At inference time (ideal if you already have a trained model and you want to boost its performance on small objects), and;
- Before training, by adding the right preprocessing steps.
You can make optimizations at both stages to improve detection performance.
In this guide, we will walk through making optimizations at both stages.
Why is the small object problem hard to solve?
There is one fundamental question we need to answer before we start talking about how you can effectively identify small objects: why is finding small objects in an image or video so difficult in the first place?
The small object problem plagues object detection models worldwide. Not buying it? Check the COCO evaluation results for recent state of the art models YOLOv3, EfficientDet, and YOLOv4:
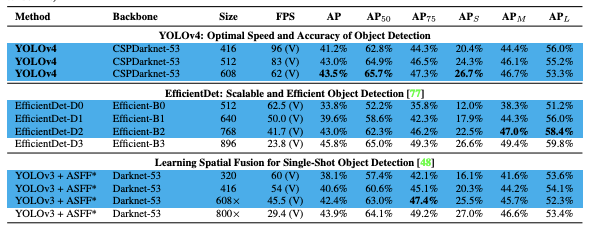
In EfficientDet for example, mean average precision (mAP) on small objects is only 12%, held up against an AP of 51% for large objects. That is almost a five fold difference!
So why is detecting small objects so hard?
It all comes down to the model. Object detection models form features by aggregating pixels in convolutional layers.
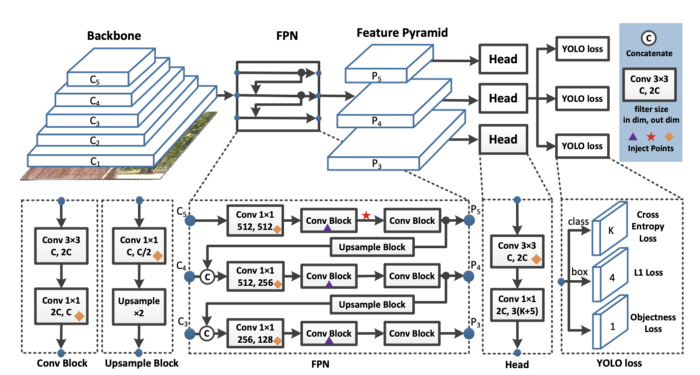
And at the end of the network a prediction is made based on a loss function, which sums up across pixels based on the difference between prediction and ground truth.
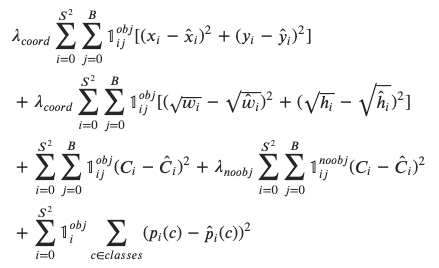
If the ground truth box is not large, the signal will small while training is occurring.
Furthermore, small objects are most likely to have data labeling errors, where their identification may be omitted.
Empirically and theoretically, small objects are hard.
How to detect small objects (inference optimisations)
Whether it’s a bustling street, drone footage of a city, or surfers riding the waves near the horizon, naively running object detection models often yield poor results. The primary reason is that models trained on larger objects miss small details.

To solve this, you could use a model trained on higher-resolution images, such as yolov8s-1280. However, our approach to this problem is InferenceSlicer.
In this article, I’ll explain how to use it and highlight two recent features:
- Overlap filtering strategies
- Segmentation support.
What is Inference Slicer?
Instead of running the model on the whole scene, InferenceSlicer splits it into smaller parts (slices), runs the model on each one, and then stitches the results together. Broadly, this is known as SAHI.
Using InferenceSlicer is straightforward:
import supervision as sv
from inference import get_model
model = get_model(model_id="yolov8m-640")
image = cv2.imread(<SOURCE_IMAGE_PATH>)
def callback(image_slice: np.ndarray) -> sv.Detections:
results = model.infer(image_slice)[0]
return sv.Detections.from_inference(results)
slicer = sv.InferenceSlicer(callback=callback)
detections = slicer(image)To see the results, you can annotate the image:
annotated_frame = sv.BoundingBoxAnnotator().annotate(
scene=image.copy(),
detections=detections
)
While It took much longer, the model detected all the people in the water.
Here's the code we ran:
import supervision as sv
from inference import get_model
import cv2
image = cv2.imread("beach.jpg")
model = get_model("yolov8s-640")
def slicer_callback(slice: np.ndarray) -> sv.Detections:
result = model.infer(slice)[0]
detections = sv.Detections.from_inference(result)
return detections
slicer = sv.InferenceSlicer(
callback=slicer_callback,
slice_wh=(512, 512),
overlap_ratio_wh=(0.4, 0.4),
overlap_filter_strategy=sv.OverlapFilter.NONE
)
detections = slicer(image)
annotated_frame = sv.BoundingBoxAnnotator().annotate(
scene=image.copy(),
detections=detections
)What are all of these parameters? Let's look deeper:
slice_whallows you to set the sizes of each slice. Don’t worry if it doesn’t divide the image precisely -InferenceSlicerwill determine the slice locations automatically, though they overlap sometimes. Givingslice_whsmaller values will produce more blocks, making inference slower but more precise.overlap_ratio_wh, independent of the previous parameter, add some overlap to each slice. If set to(0, 0), objects near the edges may be cropped off, confusing the model. We recommend at least 20% overlap -(0.2, 0.2). Larger values will produce more slices - inference will take longer but will be more precise.callbackdefines what is performed on each slice. It is a function accepting anp.ndarrayimage, performing some model logic, and returning onesv.Detectionsobject. Note that function input will be in BGR (blue-green-red), similar to whatcv2.imreadproduces.thread_workerslets you use multiple threads, which may speed up performance when the model is run on a CPU. When working with a GPU, we suggest keeping this at1. We’re working on a parallelized implementation - let us know if that’s something you need!- Lastly,
overlap_filter_strategyandiou_thresholddeal with removing duplicate or overlapping detections. Let’s dive deeper.
Overlap Filtering Strategy
By their nature, some models produce multiple overlapping detections. Setting overlap_ratio_wh contributes too - in the previous beach example, we ended up with 575 detections, whereas the actual number is closer to 280. How do we reach that?
Since it's hard to see overlaps in the beach example, let's analyze a simpler image. Suppose we have detected the following, with overlap_filter_strategy = sv.OverlapFilter.NONE. We can see all detections, but there's room for improvement.

By default, InferenceSlicer would have performed non-max suppression (NMS), suppressing some detections. The gist of it is - whenever detections with significant overlap are found, InferenceSlier keeps the one with the highest confidence and discards others. You can set the iou_threshold parameter to control that - the lower the value, the more detections will be dropped.
If you're interested, Piotr wrote an in-depth analysis of Non-Max Suppression with NumPy.

Non-max merge
In supervision v0.21.0, we’ve introduced more filtering strategies. By setting overlap_filter_strategy, you can now do no filtering or non-max-merge (NMM).
You can use it by setting overlap_filter_strategy = sv.OverlapFilter.NON_MAX_MERGE.
Non-max merge is very similar to non-max suppression. First, IOU is computed and compared to a threshold, determining which features overlap significantly. However, instead of discarding all but the most confident one, features are progressively merged. Here’s the algorithm:
- Compute the IOU of all features
- Find groups of features where each overlap by at least
iou_threshold - For each group, starting with the most confident detection, merge the next most confident one into the first
- Recompute the IOU, making sure we don’t merge infinitely
- Go back to step 3 and continue until we find that further merges aren’t possible
- Repeat the process with other groups
In the end, you should see boxes enveloping the detected objects.

Choosing the Right Parameters
Our advice: experiment with your use case and different InferenceSlicer parameters.
First, check if a standard approach, withoutInferenceSlicer can detect all objects you wish.
If not, start by using InferenceSlicer with default parameters. Proceed to set slice_wh and overlap_ratio_wh to fine-tune the results.
Lastly, check for detection overlaps. In most cases, the default value for overlap_filter_strategy will work well. Otherwise, experiment with sv.OverlapFilter.NON_MAX_MERGE. Don't forget to set the iou_threshold!

Segmentation Support
In the article, I mentioned detections and boxes, but since supervision v0.21.0, you can just as quickly do this with segmentation and masks! All you need is a segmentation model, e.g. yolov8s-seg-640:
import supervision as sv
from inference import get_model
model = get_model(model_id="yolov8s-seg-640")
image = cv2.imread(<SOURCE_IMAGE_PATH>)
def callback(image_slice: np.ndarray) -> sv.Detections:
results = model.infer(image_slice)[0]
return sv.Detections.from_inference(results)
slicer = sv.InferenceSlicer(callback=callback)
detections = slicer(image)Make sure to use a different annotator to see the masks!
annotated_frame = sv.MaskAnnotator().annotate(
scene=image.copy(),
detections=detections
)Here's a run on an AI-generated image:

While harder to see, here's a segmentation of the beach image created with InferenceSlicer.

Roboflow's Inference Slicer will split an image into small segments, run a model of your choice on each part, and glue the results together. If there are overlapping results, Slicer will automatically handle it based on the overlap_filter_strategy you choose. As of recently, it also works with segmentation!
Next time you find yourself struggling with small objects, give it a try!

How to detect small objects (pre-processing)
Now we understand the problem, we're ready to start talking about how to solve it. To improve your model's performance on small objects, we recommend the following techniques:
- Increasing your image capture resolution
- Increasing your model's input resolution
- Tiling your images
- Generating more data via augmentation
- Auto learning model anchors
- Filtering out extraneous classes
In the following video, we discuss how to tackle the small object problem in more depth, providing you with the tools and information you need:
Small object detection guide video
Tip #1: Increase your image capture resolution
Resolution, resolution, resolution... it is all about resolution.
Very small objects may contain only a few pixels within the bounding box - meaning it is very important to increase the resolution of your images to increase the richness of features that your detector can form from that small box.
Therefore, we suggest capturing as high of resolution images as possible, if possible.
Tip #2: Increase your model's input resolution
Once you have your images at higher resolution, you can scale up your model's input resolution. Warning: this will result in a large model that takes longer to train, and will be slower to infer when you start deployment. You may have to run experiments to find out the right tradeoff of speed with performance.
You can easily scale your input resolution in our tutorial on training YOLOv4 by changing image size in the config file.
[net]
batch=64
subdivisions=36
width={YOUR RESOLUTION WIDTH HERE}
height={YOUR RESOLUTION HEIGHT HERE}
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue = .1
learning_rate=0.001
burn_in=1000
max_batches=6000
policy=steps
steps=4800.0,5400.0
scales=.1,.1You can also easily scale your input resolution in our tutorial on how to train YOLOv5 by changing the image size parameter in the training command:
!python train.py --img {YOUR RESOLUTON SIZE HERE} --batch 16 --epochs 10 --data '../data.yaml' --cfg ./models/custom_yolov5s.yaml --weights '' --name yolov5s_results --cacheNote: you will only see improved results up to the maximum resolution of your training data.
Tip #3: Tile images during preprocessing
Another great tactic for detecting small images is to tile your images as a preprocessing step. Tiling effectively zooms your detector in on small objects, but allows you to keep the small input resolution you need in order to be able to run fast inference.
Tiling images as a preprocessing step in Roboflow
If you use tiling during training, it is important to remember that you will also need to tile your images at inference time.
Tip #4: Tile images at inference
If you’ve used tiling during training, you will also need to use tiling during inference for more accurate results. This is because we want to maintain the zoomed in perspective so that objects during inferences are of a similar size to what they were during training.
Here’s an example of a model trained to detect cars via aerial photos. The model was trained with tiling to better recognize cars given their small size and the large size of the source image, but without tiling at inference, it ends up detecting buildings and other large shapes instead of cars because they are closer to the size of the object it was attempting to detect during training.

Below we’ve applied tiling to an image before running inference. This allows us to zoom in to sections of the image and make our cars bigger and easier to detect for the model.

Tip #5: Generate more data using image augmentation
Data augmentation generates new images from your base dataset. This can be very useful to prevent your model from overfitting to the training set.
Some especially useful augmentations for small object detection include random crop, random rotation, and mosaic augmentation.
Tip #6: Use auto-learning model anchors
Anchor boxes are prototypical bounding boxes that your model learns to predict in relation to. That said, anchor boxes can be preset and sometime suboptimal for your training data. It is good to custom tune these to your task at hand. Thankfully, the YOLOv5 model architecture does this for you automatically based on your custom data. All you have to do is kick off training.
Analyzing anchors... anchors/target = 4.66, Best Possible Recall (BPR) = 0.9675. Attempting to generate improved anchors, please wait...
WARNING: Extremely small objects found. 35 of 1664 labels are < 3 pixels in width or height.
Running kmeans for 9 anchors on 1664 points...
thr=0.25: 0.9477 best possible recall, 4.95 anchors past thr
n=9, img_size=416, metric_all=0.317/0.665-mean/best, past_thr=0.465-mean: 18,24, 65,37, 35,68, 46,135, 152,54, 99,109, 66,218, 220,128, 169,228
Evolving anchors with Genetic Algorithm: fitness = 0.6825: 100%|██████████| 1000/1000 [00:00<00:00, 1081.71it/s]
thr=0.25: 0.9627 best possible recall, 5.32 anchors past thr
n=9, img_size=416, metric_all=0.338/0.688-mean/best, past_thr=0.476-mean: 13,20, 41,32, 26,55, 46,72, 122,57, 86,102, 58,152, 161,120, 165,204Tip #7: Filter out extraneous classes
Class management is an important technique to improve the quality of your dataset. If you have one class that is significantly overlapping with another class, you should filter this class from your dataset. And perhaps, you decide that the small object in your dataset is not worth detecting, so you may want to take it out. You can quickly identify all of these issues with the Advanced Dataset Health Check that is a part of Roboflow Pro.
Class omission and class renaming are all possible through Roboflow's ontology management tools.
Conclusion
Properly detecting small objects is truly a challenge. In this post, we have discussed a few strategies for improving your small object detector, namely:
- Increasing your image capture resolution
- Increasing your model's input resolution
- Tiling your images
- Generating more data via augmentation
- Auto learning model anchors
- Filtering out extraneous classes
As always, happy detecting!
Cite this Post
Use the following entry to cite this post in your research:
Linas Kondrackis, Jacob Solawetz. (Jun 14, 2024). How to Detect Small Objects: A Guide. Roboflow Blog: https://blog.roboflow.com/detect-small-objects/