13 May 2026 • 5 min read GPT-5.5: Vision Benchmarks & Use Cases Explore OpenAI GPT 5.5 vision benchmarks. Learn how its new high-resolution encoder improves document parsing and how to use it in Roboflow Workflows.
6 May 2026 • 4 min read Claude Opus 4.7: Vision Benchmarks & Use Cases See Claude Opus 4.7 vision benchmarks. Learn how to use its higher-resolution image encoder and document parsing for automated data labeling.
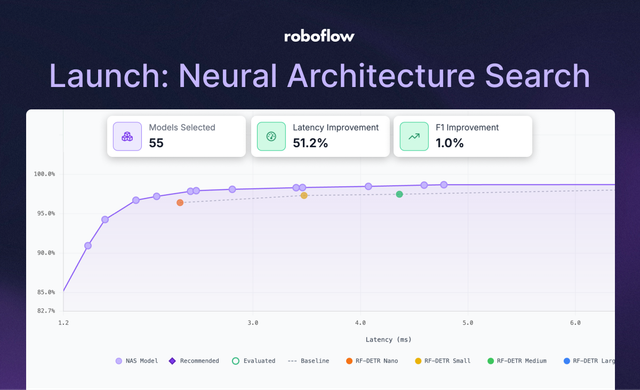
27 Apr 2026 • 5 min read Neural Architecture Search: Train the best vision model for your data Balancing inference speed and accuracy just got easier. Learn how Neural Architecture Search evaluates thousands of configurations simultaneously to deliver the highest-performing model for your target hardware.
2 Apr 2026 • 5 min read Using Videos as Training Data Turn video files into training data. Learn how to extract frames, set sampling rates, and use Roboflow to speed up computer vision labeling.
16 Mar 2026 • 25 min read Gemini 3 Guide: Master Google’s Deep Think Model in Roboflow Explore Gemini 3’s native multimodality and Deep Think reasoning. Learn how to deploy Gemini 3.1 Pro for object detection, OCR, and VQA using Roboflow Workflows and Playground.
23 Feb 2026 • 15 min read Roboflow Training Graphs Guide Learn how to read Roboflow training graphs. Understand what each curve means, how the underlying metrics are computed, and how to diagnose common training problems.
4 Feb 2026 • 7 min read Best Multimodal Models in 2026 From SAM 3’s record-breaking segmentation speed to Gemini 3’s massive 2-million-token context window, explore the top models that can "see," reason, and deploy in production today.
4 Feb 2026 • 7 min read Segment Anything This guide breaks down the SAM lineage - from SAM 1’s 50ms CPU inference to SAM 3’s open-vocabulary "GPT moment" - showing you how to deploy these foundation models into your production workflows today.
26 Jan 2026 • 9 min read Open-Vocabulary Object Detection Using Qwen3-VL in Google Colab See how to run Qwen3-VL in Google Colab to build a prompt-driven detection pipeline that turns “find a yellow taxi” into structured, production-ready results.
22 Jan 2026 • 7 min read Using Vision-Language Models for Image Understanding Vision-language models make image understanding fast and accessible. By using simple text prompts, teams can explore datasets, discover labels, spot errors, and speed up annotation early, before training, building stronger foundations for reliable computer vision systems.
21 Jan 2026 • 6 min read How to Use Qwen3-VL in Roboflow In this guide, build an image-understanding workflow in Roboflow that turns Qwen3-VL into a production-ready vision agent you can run via API or on your own GPU.
15 Jan 2026 • 4 min read Train a YOLO26 Instance Segmentation Model with Custom Data In this guide, we will demonstrate how to implement instance segmentation using the YOLO26 architecture. To follow along, we recommend opening the YOLO26 Instance Segmentation Colab Notebook. While object detection tells you where an object is with a box, instance segmentation takes it a step further by identifying the exact
14 Jan 2026 • 4 min read How to Train a YOLO26 Object Detection Model with Custom Data In this tutorial, we walkthrough how to train YOLO26 for object detection on a custom dataset. We recommend working through this blog post side-by-side with the YOLO26 Object Detection Colab notebook. You'll learn how to train a custom model to detect NBA players, referees, and basketballs. ⚡RF-DETR Neural
14 Jan 2026 • 7 min read Depth Anything 3 for Depth Estimation In this guide, learn what makes DA3 different, where it shines, and how to build a working depth estimation pipeline in Roboflow Workflows that generates real 3D insight in minutes.
14 Jan 2026 • 9 min read What is YOLO? The Ultimate Guide Learn about the history of the YOLO family of objec tdetection models, extensively used across a wide range of object detection tasks.
13 Jan 2026 • 12 min read Object Detection vs Vision-Language Models: When Should You Use Each? Object detection and vision-language models solve different problems. This guide explains when to use each. And how speed, cost, and reliability differ.
31 Dec 2025 • 7 min read Try Gemini 3 Pro From Google Learn how Gemini 3 Pro sets new vision benchmarks. Then try and compare it against other top vision models using Roboflow Playground.
10 Dec 2025 • 5 min read How to Fine-Tune Claude 3.7 Sonnet With Roboflow Claude 3.7 Sonnet is one of the most powerful multimodal models for visual reasoning, and now you can customize it for your use case with Roboflow Workflows. Learn how to fine-tune Sonnet for structured JSON outputs and deploy a production-ready visual Q&A tool.
10 Dec 2025 • 17 min read Best Defect Detection Algorithms for Manufacturing This guide breaks down the best defect detection algorithms for manufacturing and shows why instance segmentation is now the standard for high-precision quality control.
9 Dec 2025 • 4 min read Introducing Roboflow Rapid: Text prompt to vision model in minutes For most of computer vision's history, training has been extremely challenging. Going from an idea to a deployed application meant spending weeks labeling hundreds or thousands of images by hand just to see if a concept would work. Now the era of manual labeling is ending. Today, we
25 Nov 2025 • 15 min read Meta SAM 3D: Introduction Understand what is SAM 3d and learn how to use SAM 3D + Roboflow to generate synthetic data and train a computer vision model.
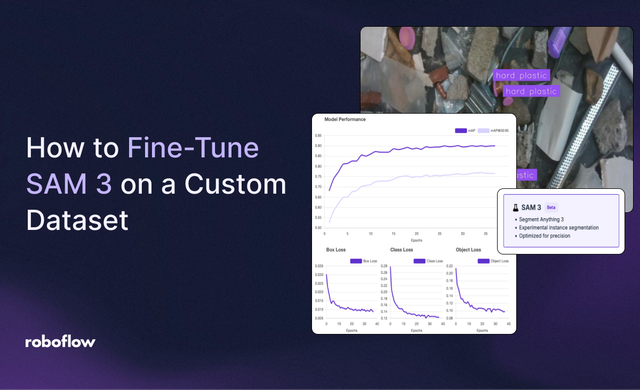
19 Nov 2025 • 8 min read How to Fine-Tune Segment Anything 3 (SAM 3) on a Custom Dataset Learn how to fine-tune SAM-3 for image segmentation with a custom dataset.
13 Nov 2025 • 15 min read Explore the Best Depth Estimation Models Depth estimation gives machines a 3D understanding of the world. See today’s leading depth estimation models, and learn how to run Depth Anything V2 inside Roboflow Workflows.
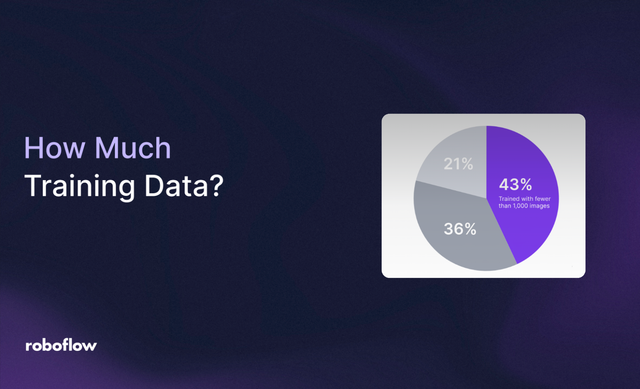
10 Nov 2025 • 13 min read How Much Training Data Do You Need to Train a Computer Vision Model? Discover how to find the right amount of training data for your computer vision project. Learn how dataset size, balance, and annotation quality impact model accuracy.