![Top 5 Computer Vision Python Packages [2025]](/content/images/size/w1200/format/webp/2025/01/16_9-4-.png)
Python is the default programming language for many machine learning project types, from computer vision to natural language processing.
In terms of computer vision, there are a number of Python packages you can use to build projects and work with models. These include Supervision, OpenCV, Torchvision, Transformers, and Timm.
These libraries support various computer vision tasks and make it easier than ever to implement complex solutions with minimal effort.
In this article, we’ll explore the top five Python packages for computer vision that offer unique capabilities to help you tackle a wide range of tasks with ease.
Explore The Top Computer Vision Python Packages
We will talk about:
- Supervision, which provides general utilities for working with computer vision models;
- OpenCV, a lower-level library with robust implementations of computer vision algorithms;
- Torchvision, which you can use to build deep learning models for computer vision;
- Transformers, which implements many state-of-the-art vision model architectures, and;
- Timm, which you can use for image classification.
Let's get started!
1. Supervision: General Vision Utilities
Supervision is an open-source Python package developed by Roboflow to make working on computer vision projects easier. It helps simplify common tasks like object detection, tracking, and video processing by providing reusable tools that save you from writing repetitive code.
Suppose you want to quickly draw bounding boxes around detected objects in a video frame, Supervision can help you do so with built-in annotators. It eliminates the need to manually code this functionality from scratch.

Supervision aims to let you focus on building your computer vision application and less on the technical overhead. It’s model-agnostic, meaning you can easily integrate it with popular models for classification, detection, and segmentation without worrying about compatibility. It also comes with connectors to popular libraries like Ultralytics, Transformers, or MMDetection.
Here’s a closer look at some of the other key features of Supervision:
- Dataset Utilities: The package also includes utilities for loading, splitting, and merging datasets in different formats like COCO, YOLO, and Pascal VOC, so that you can manage your data for training and testing
- Real-Time Video Analytics: Supervision supports object tracking with tools like ByteTrack and integrates with video pipelines. Users can analyze video streams in real time.
- Filter Detections: It lets you filter object detections based on things like object type, confidence level, or location in the frame. You can focus on the most relevant data and ignore detections that aren’t useful for your specific task.
2. OpenCV: Low-Level Algorithms
OpenCV is one of the most widely used open-source libraries for computer vision.
Originally developed by Intel, it offers a huge range of algorithms for image processing, object detection, and facial recognition.
OpenCV compatible with several programming languages, including Python, C++, and Java, and works across different platforms, making it a versatile choice for both desktop and mobile applications. In fact, OpenCV works on Linux, Windows, macOS, iOS, and Android, giving it flexibility for a variety of projects.
Here’s a closer look at some of the other key features of OpenCV:
- Large Algorithm Library: OpenCV includes over 2,500 algorithms for tasks like face recognition, 3D modeling, object detection, and more. From basic image manipulation to advanced computer vision functions, OpenCV provides many capabilities.
- Real-Time Video Processing: It excels at real-time video analytics with features for video recording, motion tracking, and object detection.
- Hardware Acceleration: The package is optimized for performance and supports multi-core processing, as well as GPU acceleration with CUDA and OpenCL, making it perfect for real-time tasks.
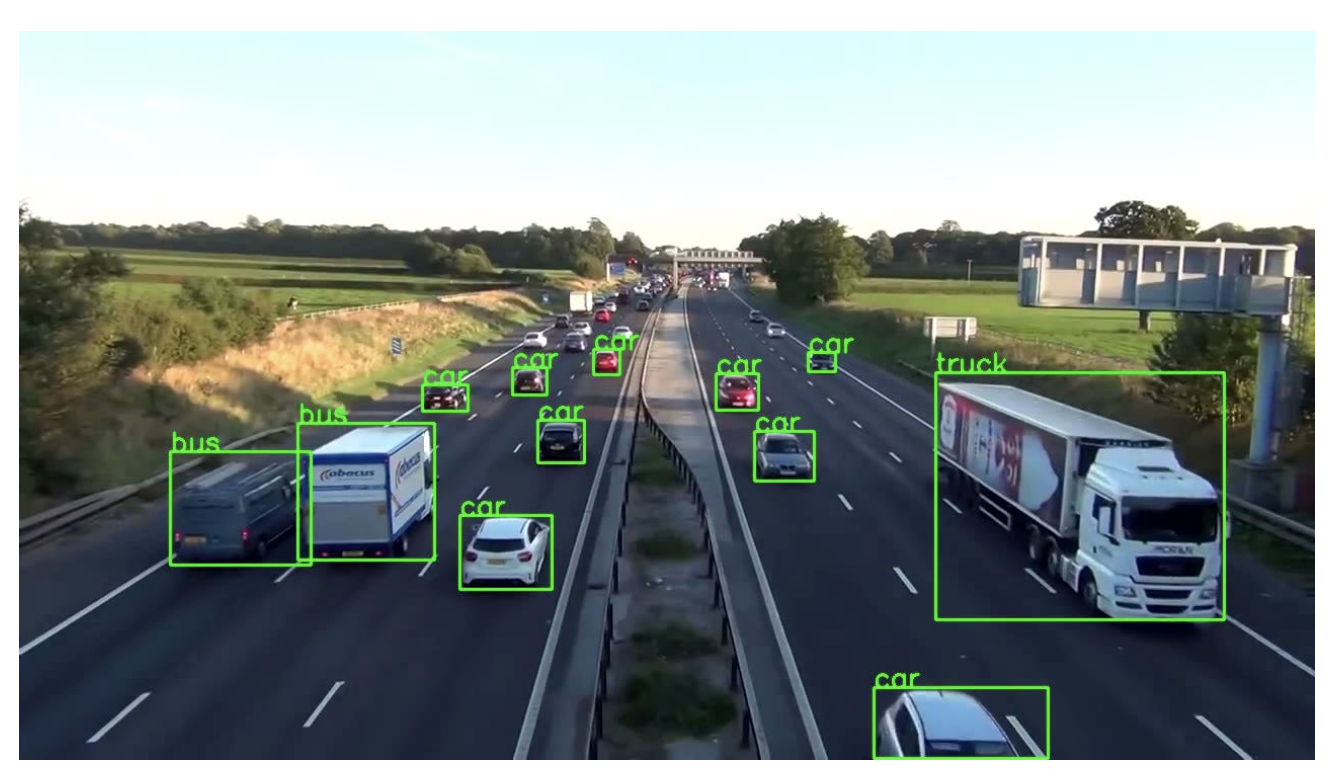
If your project requires hardware acceleration or needs to run across multiple platforms, OpenCV’s support for GPU acceleration and its compatibility with Python, C++, and Java makes it a reliable option for many vision tasks.
Whether you're just getting started or already have experience, OpenCV’s rich features and strong community support make it a solid, go-to option for all kinds of computer vision projects.
Despite its strengths, the documentation can sometimes be sparse, which may pose challenges for beginners, and its deep learning support is limited compared to more specialized libraries like TensorFlow.
3. Torchvision: A PyTorch Library for Image and Video Processing
Torchvision is a core library in the PyTorch ecosystem designed to simplify deep learning tasks related to computer vision. It offers a wide array of tools, including datasets, image transformations, and pre-trained models.
Since Torchvision tightly integrated with PyTorch, the library has extensive support for GPU acceleration and other PyTorch features. For instance, the DataLoader module helps batch and load data efficiently, so you can work with large datasets and make use of GPU power for training.
Torchvision is useful for deep learning projects involving image classification, object detection, or segmentation. It's especially helpful if you're already using PyTorch. The pre-trained models and image transformation tools make it easy to get started quickly.
You don’t need to spend much time training models from scratch or handling complex data preparation.
Here’s a closer look at some of the other key features of Torchvision:
- Pre-trained Models: Torchvision provides an assortment of pre-trained models, such as ResNet, VGG, and Faster R-CNN, for image classification, object detection, and segmentation. These models are well-suited for transfer learning. Developers can fine-tune them for their specific use cases without having to train models from scratch.
- Image Transformations: The library includes numerous functions to manipulate images, including resizing, cropping, normalization, and data augmentation. These tools are essential for preparing data and improving model performance during training.
- Dataset Support: Torchvision comes with built-in support for popular datasets like CIFAR, MNIST, ImageNet, and COCO and simplifies the process of loading and preprocessing data for training.

4. Transformers: Access Pretrained, Open-Source AI Models
Transformers, developed by Hugging Face, is a comprehensive library that gives developers access to pre-trained models for tasks across various domains like computer vision, natural language processing, and audio.
Models implemented in Transformers are all ready to use, so you don’t need to train them from scratch, making it easier and faster to integrate advanced AI into your projects. The library supports frameworks like PyTorch, TensorFlow, and JAX, providing flexibility for different environments.
Here’s a closer look at some of the other key features of Transformers:
- Multimodal Capabilities: Transformers are designed to handle various tasks. So, if you're working with text, images, or even audio, this package is a versatile option for projects that involve multiple data types.
- Easy-to-Use Pipelines: With the pipeline() API, you can quickly perform tasks like image recognition or segmentation using just a few lines of code. It provides a high-level interface that simplifies working with complex models.
- Cross-platform Deployment: With integration options for cloud platforms, you can deploy models efficiently on various cloud infrastructures, including AWS and Google Cloud.

5. PyTorch Image Models (timm) for Classification
Timm, short for PyTorch Image Models, is a popular library designed by Ross Wightman. It provides a wide range of pre-trained models for image classification, making it easier for developers to get started with state-of-the-art architectures.
The library includes implementations of several popular classification architectures like ResNet, EfficientNet, and Vision Transformers that can be fine-tuned for specific tasks.
Timm simplifies model training and deployment for classification while offering tools to help improve performance and efficiency. Timm also includes tools for benchmarking and evaluating models on datasets like ImageNet. You can easily compare model performance.
Here’s a closer look at some of the other key features of Timm:
- Performance Optimizations: Timm supports efficiency-boosting features like mixed-precision training that reduces memory use and speeds up training. It also includes data augmentation techniques like MixUp and CutMix to help improve the robustness of your models.
- Multi-platform Support: It works seamlessly with PyTorch and supports deployment on various platforms.
- Active Community and Continuous Updates: The library is well-maintained with regular updates and contributions from the community, ensuring it stays up to date with the latest advances in image modeling.
How Different Python Packages For Computer Vision Compare
Choosing the best Python package for your computer vision project can make a big difference in your results. Whether you need Supervision for streamlined workflows, OpenCV for classic image processing, Torchvision for deep learning integration, Transformers for cutting-edge AI, or Timm for efficient classification model training, there’s an option that fits your needs.
The key is to consider your project’s specific needs, which may include real-time processing, training models, or detecting objects, and pick the package that fits.
In practice, you may find yourself using several of the libraries above on a project. You may use OpenCV for one application and PyTorch to implement a deep learning model in another application. You may use Transformers to run a vision model, then supervision to process model detections.
Explore More
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Oct 14, 2024). Top 5 Computer Vision Python Packages [2025]. Roboflow Blog: https://blog.roboflow.com/computer-vision-python-packages/